Smooth Rolling Update of Ingress Controller Using AWS NLB - No Service Interruption
1 Overview
In the cloud, to allow external traffic to access your Kubernetes cluster, the typical approach is to use a LoadBalancer-type service, which directs external traffic through a load balancer into the Ingress Controller and then distributes it to various pods.
Ingress controllers often need updates or configuration changes, which usually require the program to be restarted. So, what happens when an Ingress Controller needs a rolling update? Will Ingress access be interrupted?
In the following scenario, we will self-host a Kubernetes cluster on AWS, use Traefik 2 as the Ingress Controller, and deploy AWS LoadBalancer Controller 2.2.0. We will install Traefik 2 from the official Helm repository version 9.19.1. We will use an NLB with 3 availability zones, IP mode targeting, and we won’t use LoadBalancer-type services. Instead, we’ll use headless ClusterIP-type services, which AWS LoadBalancer Controller supports. For the network plugin, we’ll use the Amazon VPC CNI plugin.
2 Why This Design?
NLB operates at Layer 4, directly forwarding traffic without needing to parse the HTTP protocol, resulting in better performance and lower latency.
If the target type is “instance,” then the Kubernetes service type must be either NodePort or LoadBalancer.
If the target type is “ip,” NLB must go directly to the pods without NAT, but you must use the Amazon VPC CNI network plugin.
The default LoadBalancer-type service in Kubernetes allocates a node port. If the target type is “instance,” NLB traffic is routed through the node port to pods, adding response latency. If the target type is “ip,” it also allocates a node port by default, but NLB directly forwards traffic to pods without going through node port forwarding.
AWS LoadBalancer Controller supports target types “ip” and “instance,” while the cloud controller embedded in the controller-manager only supports “instance” type.
Using a headless service avoids allocating node ports and cluster IP, saving IP and node port port resources. Starting from Kubernetes 1.20, LoadBalancer-type services can be configured not to allocate node ports, allowing the LoadBalancer to communicate directly with pods. To enable this feature, you need to activate the ServiceLBNodePortControl feature gate and set spec.allocateLoadBalancerNodePorts to false.
service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: traefik2
meta.helm.sh/release-namespace: kube-system
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: /ping
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-name: k8s-traefik2-ingress
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internal
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: deregistration_delay.timeout_seconds=120,
preserve_client_ip.enabled=true
service.beta.kubernetes.io/aws-load-balancer-type: external
creationTimestamp: "2021-06-04T14:37:20Z"
finalizers:
- service.k8s.aws/resources
labels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: traefik
helm.sh/chart: traefik-9.19.1
name: traefik2
namespace: kube-system
resourceVersion: "734023"
uid: 65312c00-99dd-4713-869d-8b3cba4032bb
spec:
clusterIP: None
clusterIPs:
- None
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: web
port: 80
protocol: TCP
targetPort: web #This corresponds to 3080 in the pod
- name: websecure
port: 443
protocol: TCP
targetPort: websecure #This corresponds to 3443 in the pod
selector:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefik
sessionAffinity: None
type: ClusterIP
status:
loadBalancer:
ingress:
- hostname: k8s-traefik2-ingress-5d6f374f2146c85a.elb.us-east-1.amazonaws.com3 Parameter Optimization
3.1 Preserve Client IP
When the target type is “ip,” NLB does not preserve the client IP by default. To enable client IP preservation, you need to manually enable this feature. The prerequisite for NLB IP preservation is that all targets are in the same VPC, meaning Traefik pods are in the same VPC.
Additionally, Traefik 2 supports both Proxy Protocol v1 and v2 versions (Traefik v1 only supports Proxy Protocol v1) to obtain the client’s IP address. You can enable the NLB’s proxy-protocol for this purpose.
3.2 Configure Readiness Gate to Avoid Asynchronous Pod Creation and LB Registration/De-registration
3.2.1 The Process of Traefik2 Rolling Updates and Target Registration/De-registration
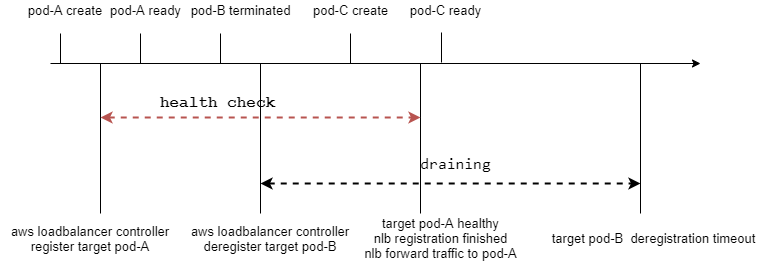
In the diagram, you can see that during the deployment’s rolling update and LB registration/de-registration, they are not synchronized. If there are no available targets in an availability zone within the health check cycle (i.e., all targets in that availability zone have not completed health checks), the IP for that availability zone will be removed from NLB’s domain resolution. If no targets are available in all availability zones within the health check cycle (i.e., all targets in all availability zones have not completed health checks), the entire NLB becomes unavailable.
AWS LoadBalancer Controller creates target health configurations with parameters: HealthCheckTimeoutSeconds as 6, HealthCheckIntervalSeconds as 10, HealthyThresholdCount as 3, and UnhealthyThresholdCount as 3. It takes approximately 3 minutes from pod creation to the successful completion of health checks before it can receive traffic. This means that if the rolling update completes within 3 minutes, the NLB will be in an unavailable state. If within 3 minutes, all pods in an availability zone are still undergoing health checks, the IP for that availability zone’s NLB instance will be removed from domain resolution.
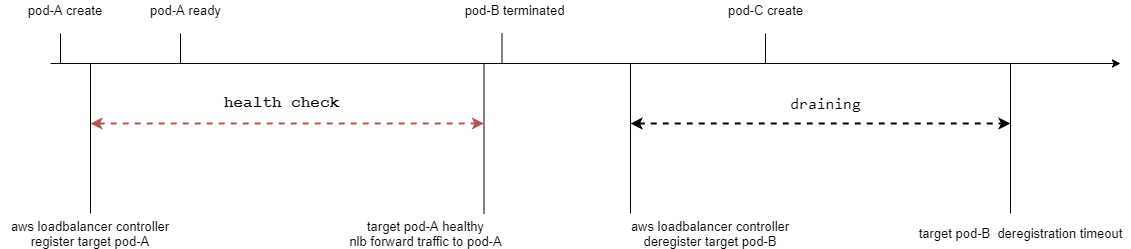
3.2.2 Configuring Readiness Gate
AWS LoadBalancer Controller supports setting the NLB as a readiness gate for pods. With this configuration, after a pod is created, it must pass both the readiness probe and the readiness gate for the deployment to terminate the pod. This ensures that there will always be available targets to receive traffic during a rolling update. Testing has shown that it takes approximately 5 minutes from pod creation to readiness gate passage.
To configure the readiness gate:
配置readiness gate
#Edit the mutatingwebhookconfigurations
kubectl edit mutatingwebhookconfigurations aws-load-balancer-controller-webhook
objectSelector:
name: mpod.elbv2.k8s.aws
namespaceSelector:
matchExpressions:
- key: elbv2.k8s.aws/pod-readiness-gate-inject
operator: In
values:
- enabled
objectSelector:
#Add the following lines to the objectSelector section
matchLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
# Label the kube-system namespace
kubectl label namespace kube-system elbv2.k8s.aws/pod-readiness-gate-inject=enabled
#Set the Traefik pod label in your values.yaml:
deployment:
podLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled3.3 Resolving Delayed Event Issue in AWS LoadBalancer Controller for Pod Deletion
Pod deletion is controlled by the ReplicaSet, which sends requests to the API server. After receiving the event, the AWS LoadBalancer Controller notifies the NLB to deregister targets. Consequently, pod deletion and NLB deregistration are not synchronized, which can lead to situations where a pod has been deleted but still appears as available in the target group. This can cause issues with traffic being directed to the IP of the deleted pod.
How can this issue be resolved?
One solution is to add a preStop hook in the pod lifecycle to sleep for 10 seconds. This prevents new connections from entering during the pod’s termination process. A 10-second delay should generally ensure that the NLB has stopped forwarding new connections to the IP of the pod. The AWS LoadBalancer Controller will receive the pod deletion event and perform deregistration in the target group, marking the target as either draining or unused.
As of Helm Chart version 9.19.1, it does not yet support setting the pod’s lifecycle directly. You would need to configure this manually or use Traefik’s parameters, such as transport.lifeCycle.requestAcceptGraceTimeout=10, to continue accepting connections for a specified grace period before gracefully closing. Note that the Traefik Helm Chart has a hardcoded terminationGracePeriodSeconds of 60 seconds, so make sure that the sum of requestAcceptGraceTimeout and graceTimeOut is less than terminationGracePeriodSeconds. The default transport.lifeCycle.graceTimeOut in Traefik (the time it waits for connections to close) is 10 seconds.
However, after configuring this, you may notice that the AWS Load Balancer Controller displays targets as already deregistered almost instantly, but the deleted pod can still receive new connections. This is because the NLB takes an additional 30 to 90 seconds to successfully deregister targets (during this time, the NLB continues to forward new connections to the target and only stops forwarding new connections once the connection termination occurs). Therefore, you would need to set requestAcceptGraceTimeout or the sleep duration to at least 90 seconds and manually increase terminationGracePeriodSeconds. Unfortunately, Traefik Helm Chart does not currently support setting the terminationGracePeriodSeconds value, but you would need to wait for PR411 to be merged.
{"level":"info","ts":1623221227.4900389,"msg":"deRegistering targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-3e41e3e1b5/74840e00b5fce25f","targets
":[{"AvailabilityZone":"us-east-1f","Id":"10.52.79.105","Port":3080}]}
{"level":"info","ts":1623221227.4903376,"msg":"deRegistering targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-5ce7e766f7/6e7b481251bf928e","targets
":[{"AvailabilityZone":"us-east-1f","Id":"10.52.79.105","Port":3443}]}
{"level":"info","ts":1623221227.524495,"msg":"deRegistered targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-3e41e3e1b5/74840e00b5fce25f"}
{"level":"info","ts":1623221227.5618162,"msg":"deRegistered targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-5ce7e766f7/6e7b481251bf928e"}The corresponding configurations
#Configuration in the pod spec:
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- sleep 90
#Or in Traefik's configuration:
--entryPoints.web.transport.lifeCycle.requestAcceptGraceTimeout=90
#Modify terminationGracePeriodSeconds in the deployment:
terminationGracePeriodSeconds: 120Process After Setting preStop:
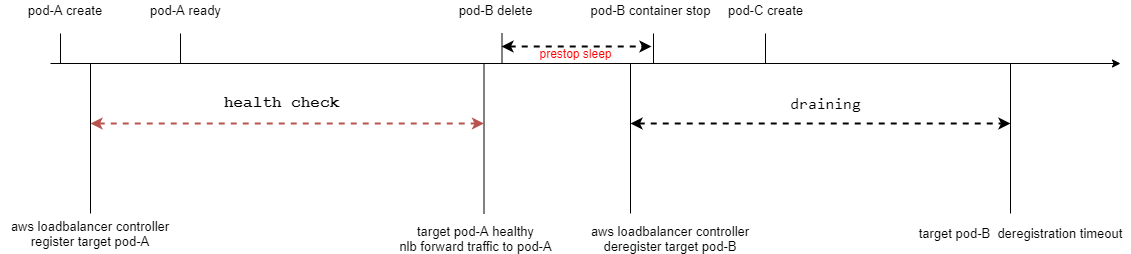
Additionally, you’ll need to configure the NLB with deregistration_delay.timeout_seconds to wait for unclosed connections to close before removing the target from the target group. The deregistration_delay.timeout_seconds in the NLB must be greater than or equal to the time it takes for the pod to exit. The recommended value by AWS is 120 seconds. When Traefik exits, it will close all connections, so this value only needs to be greater than or equal to 120 seconds. To prevent situations where a pod may remain in a terminated state, causing established connections to hang, you can also configure deregistration_delay.connection_termination.enabled to forcefully close established connections before removal.
3.4 Health Check Configuration
In Traefik 2, during graceful shutdown (including the request Accept Grace phase, where it accepts new connection requests, and the Termination Grace Period phase, where it ends established connections), Traefik remains in a healthy state. This can lead to inaccuracies in health checks if NLB uses TCP port-based health checks.
To accurately reflect Traefik’s running status, you can use Traefik’s health check /ping endpoint. During graceful shutdown, this endpoint returns a 503 status code.
To configure NLB health checks with the /ping endpoint, set the health check type to HTTP and configure the health check URL as /ping. The health check port should match the Traefik entry point port.
In your values.yaml chart configuration, you can set it like this:
service:
annotations:
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: "/ping"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-protocol: "HTTP"3.5 Avoid no healthy targets in an availability zone
To avoid situations where there are no healthy targets in an availability zone during a rolling update, you can follow these steps:
- Set
maxUnavailableto a value smaller than the smallest number of Traefik pods in any availability zone and setmaxSurgeaccordingly. In your case, you mentionedspecas 6, so you can setmaxUnavailableto 0 andmaxSurgeto 1. Ensure that the number of pods in each zone is at least 2. This is because ReplicaSet scale-down behavior does not consider pod topology spread, which might lead to all pods in an availability zone being scaled down. This issue is tracked in #issue96748. - Use
topologySpreadConstraintsto balance the number of Traefik pods in each availability zone. Starting from Kubernetes 1.18, you don’t need to enable the EvenPodsSpread feature gate, as it’s enabled by default. You can use thedefaultConstraintsprovided in yourvalues.yamlto achieve this:
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnywayThese constraints help ensure that each host has at most 3 pods difference and that the number of pods between zones differs by at most 5.
If you require stricter balancing, you can manually configure topologySpreadConstraints in your spec.template.spec. As of Traefik Helm Chart version 9.19.1 topologySpreadConstraints PR, this feature is not yet merged, so you’ll need to configure it manually.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefik
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefikYou can also utilize AWS Auto Scaling groups or cluster scaling to increase node resource availability.
4 Summary
In summary, by using readiness gates, configuring preStop lifecycles or Traefik settings, topologySpreadConstraints, and maxUnavailable, you can address various issues related to rolling updates, target availability, and node resource balance. Additionally, enabling NLB’s client IP preservation functionality can help preserve client IPs for connections.
The helm chart file values.yaml
deployment:
replicas: 6
podLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
additionalArguments:
- "--providers.kubernetesingress.ingressclass=traefik2"
- "--providers.kubernetescrd.ingressclass=traefik2"
- "--entryPoints.web.forwardedHeaders.insecure"
#- "--entryPoints.web.proxyProtocol.insecure"
- "--api.insecure=true"
- "--metrics.prometheus=true"
- "--entryPoints.web.transport.lifeCycle.requestAcceptGraceTimeout=90"
globalArguments:
- "--global.sendanonymoususage=false"
ports:
traefik:
port: 8082
web:
port: 3080
websecure:
port: 3443
service:
type: ClusterIP
spec:
clusterIP: None
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
service.beta.kubernetes.io/aws-load-balancer-scheme: "internal"
service.beta.kubernetes.io/aws-load-balancer-name: "k8s-traefik2-ingress"
#service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: "*"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: "/ping"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-protocol: "HTTP"
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: "deregistration_delay.timeout_seconds=120, preserve_client_ip.enabled=true"
#service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: "eregistration_delay.timeout_seconds=120, preserve_client_ip.enabled=true, deregistration_delay.connection_termination.enabled=true"
podDisruptionBudget:
enabled: true
minAvailable: 1
rollingUpdate:
maxUnavailable: 0
maxSurge: 1Reference
https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/guide/service/annotations
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/target-group-health-checks.html
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/network-load-balancers.html
https://stackoverflow.com/a/51471388/6059840
https://github.com/kubernetes/kubernetes/issues/45509
https://github.com/kubernetes/kubernetes/pull/99212
https://github.com/kubernetes/kubernetes/pull/101080
https://github.com/kubernetes/enhancements/issues/2255
https://stackoverflow.com/a/67203212/6059840
https://aws.amazon.com/premiumsupport/knowledge-center/elb-fix-failing-health-checks-alb/
https://stackoverflow.com/questions/33617090/kubernetes-scale-down-specific-pods

