Best Practices for Cost Optimization in Kubernetes
In the context of reducing costs and increasing efficiency, the concept of FinOps aligns well with this demand. FinOps is a best practice methodology that combines financial, technical, and business aspects, aiming to optimize the cost, performance, and value of cloud computing resources. The goal of FinOps is to enable organizations to better understand, control, and optimize cloud computing costs through prudent resource management and financial decision-making.
The stages of FinOps are divided into Cost Observation (Inform), Cost Analysis (Recommend), and Cost Optimization (Operate).
Typically, an enterprise’s internal cost platform includes cost observation and cost analysis, analyzing IT costs (cloud provider bills) based on service types and business departments.
Cost Optimization (Operate) is divided into three stages from easy to difficult:
- Handling idle machines and services, making informed choices on services and resources, including appropriate instance types, pricing models, reserved capacity, and package discounts.
- Applying service downsizing, reducing redundant resources (changing from triple-active to dual-active, dual-active to cold standby, dual-active to single-active, personnel optimization).
- Technical optimization (improving utilization).
This article focuses on the technical optimization stage of cost reduction, specifically in the context of cloud-native cost reduction strategies under Kubernetes.
1 Ideal Cost Model
Our ideal cost model is that IT costs change with business fluctuations. For example, if orders increase, the trend of IT cost increase should be less than or equal to the trend of order increase. Conversely, if orders decrease, the trend of IT cost reduction should be greater than or equal to the trend of order decrease.
This model is the ultimate goal of our cost reduction efforts, and everything revolves around continuously optimizing costs based on this principle.
2 Cloud-Native Cost Reduction Strategy
Kubernetes optimization strategies are explained in terms of deployment colocation, elasticity, increasing node utilization, and rational pod resource configuration.
2.1 Colocation
Generally, offline tasks in big data are executed at night, while online business experiences peak hours during the day and evening, with early morning being a low-traffic period. Therefore, collocating online business and big data offline tasks allows for resource utilization during off-peak hours.
The node resource model (from koordinator) is shown below:
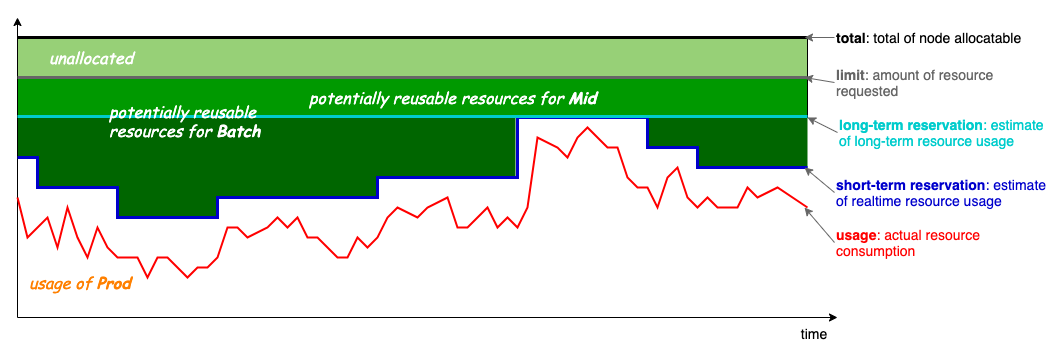
Usage represents the real-time resource usage of online business over time.
Short-term Reservation allocates resources freed up by online business for short-duration job tasks.
Long-term Reservation reserves resources (generally not used by online business unless there’s a surge), which can be utilized for long-running tasks.
Limit is the maximum allocated resource for applications on a node.
Total is the maximum allocatable resource for a node.
Based on this node resource model, scheduling optimization and QOS assurance are necessary to ensure that online business is not affected by offline tasks.
On the scheduling aspect, there are open-source projects such as volcano, koordinator’s scheduler, kueue, katalyst scheduler and godel-scheduler.
For QOS assurance, there are open-source projects like crane , koordinator and katalyst.
Another advantage of colocation is the ability to turn multiple clusters into a supercluster, saving resources used by common components like apiserver, etcd, control-plane, and monitoring components.
Colocation can be applied not only within a single cluster but also across multiple clusters. For instance, if different clusters have varying utilization rates, tasks can be deployed to nodes with lower utilization. If clusters are distributed in different time zones, meaning peak resource usage differs, tasks can be deployed at staggered times.
The open-source project karmada is exploring solutions for managing multiple clusters in these aspects.
2.2 Elasticity
Elasticity is divided into application elasticity, cluster elasticity, and hybrid cluster elasticity.
Application Elasticity includes horizontal and vertical scaling. Horizontal scaling involves Horizontal Pod Autoscaling (HPA), KEDA, serverless (knative, etc.), scheduled HPA (Tencent Cloud TKE cron-hpa, Alibaba Cloud open-source kubernetes-cronhpa-controller, Ant Financial open-source kapacity), predictive scaling (crane’s EHPA, Ant Financial’s kapacity, Alibaba Cloud’s AHPA). Serverless can bring costs close to zero when there is no traffic. Middleware and database elasticity are also considerations, and there are many open-source projects for cloud-native databases and middleware with elasticity as a crucial feature. Vertical scaling includes VPA, supported from Kubernetes version 1.27 onwards.
Cluster Elasticity involves cluster-autoscaler, which automatically adds nodes to the cluster based on pending pods (unscheduled pods) and takes idle nodes offline. Cluster scaling also includes AWS’s open-source karpenter, which scales nodes at the workload level, whereas cluster-autoscaler scales nodes based on the cloud provider’s products.
Hybrid Cluster Elasticity: When a cluster lacks capacity, temporarily deploy applications to other clusters. A typical scenario is Kubernetes in a self-built IDC data center that needs to scale due to events. As self-built data center resource delivery is slow, leveraging the rapid resource delivery capability of cloud providers by deploying some business to the public cloud can address traffic peaks.
There are two solutions for this application scenario:
- Use virtual-kubelet to treat the cloud provider’s Kubernetes cluster as a node in the self-built cluster, and schedule the scaling applications to this node.
- Treat the cloud provider’s Kubernetes cluster as an independent cluster for application deployment. This can be achieved using karmada for deploying applications across multiple clusters.
Scaling Node Strategy on Cloud Provider’s Kubernetes Cluster: Nodes are divided into long-term and short-term running nodes. Scale short-term running nodes, first prioritizing the use of Spot Instances, followed by on-demand nodes, and finally reserved nodes. For long-term running node scaling, choose reserved nodes.
2.3 Increasing Node Utilization
Resource Overcommitment involves setting pod limits higher than requests, a simple method to increase utilization. It improves node packing density, but the downside is that pod QOS can only be Burstable.
Node Amplification enlarges the allocatable resources of nodes, allowing the scheduler to allocate more resources to pods. The advantage is that pod QOS doesn’t have to be locked to Burstable, and pods can freely configure QOS. Koordinator implements node amplification.
BestEffort Pods use idle node resources, meaning pods don’t set limits and requests. However, not restricting limits can affect other pods on the node. To address this, crane predicts node resources dynamically, calculates the remaining resources, and configures pods to use these resources with expanded configurations (QOS remains BestEffort). The crane agent ensures that pods using expanded resources don’t exceed their declared limits.
Scheduling Based on Real Node Load utilizes actual node resource usage for scheduling, improving node utilization and balancing resource usage across cluster nodes. Both crane and koordinator have this functionality.
Descheduler: The highNodeUtilization plugin evacuates pods from nodes with high utilization to nodes with low utilization, balancing resource usage. The lowNodeUtilization plugin evacuates pods from nodes with low utilization to nodes with high utilization, then takes idle nodes offline to increase node utilization. The current Descheduler in the community uses allocated requests to calculate node load, which may not have practical significance. Koordinator’s Descheduler implements load-aware descheduling and adds resource reservation capability to ensure that after evicting pods, new pods are created without resource contention.
2.4 Reasonable Application Resource Configuration
Business units tend to be conservative in reserving more resources for applications, leading to significant resource waste. Setting reasonable resource configurations for applications can avoid this waste.
Recommended Resource Specifications: Recommending application specifications based on VPA’s decay algorithm allows requests to approach real usage values. This is useful for the default kube-scheduler (which schedules based on requests) and can improve node packing density. Both crane and VPA have resource recommendation capabilities.
Replica Count Recommendation: For applications without HPA enabled, using a reasonable replica count can also avoid resource waste. Crane has a replica count recommendation feature.
HPA Recommendation: For applications with HPA enabled, inefficient HPA settings can lead to resource waste. Crane recommends appropriate HPA configurations based on actual resource usage, improving resource utilization.
3 Conclusion
By employing colocation, elasticity, increasing node utilization, and reasonable pod resource configuration, various technical strategies can enhance Kubernetes cluster resource utilization and reduce costs. The mentioned strategies are based on my understanding of cloud-native cost reduction, and companies can choose different strategies based on their specific situations. It’s not necessary to adopt all strategies.
Both crane and koordinator are excellent open-source projects for cost reduction and efficiency improvement. However, crane became inactive in 2023, although the founders shared insights at KubeCon 2023 China When FinOps Meets Cloud Native – How We Reduce Cloud Cost with Cloud Native Scheduling Technologies.
Koordinator and karmada continue to be very active.
ByteDance has initiated the open-source projects Katalyst for colocation and Godel-scheduler for scheduler-related functionalities. There is some overlap in the features of Godel-scheduler and Katalyst-scheduler; Godel-scheduler is a more specialized scheduler, while Katalyst-scheduler implements only partial feature enhancements (in v0.4.0, it only extended node resource topology awareness and QoS resource awareness). It’s essential to monitor the ongoing development of these projects.
When inquiring about the relationship and potential overlap between Katalyst-scheduler and Godel-scheduler in the community, the following response was received:
For Katalyst, the positioning of these two does overlap because some of Katalyst’s functionalities require coordination with the scheduler’s capabilities, e.g., scheduling reclaimed resources, topology awareness, etc. However, Katalyst’s core capability lies in enhancing QoS capabilities. We don’t want it to have a strong binding relationship with a specific scheduler, i.e., you shouldn’t have to use a specific scheduler to leverage Katalyst’s capabilities or adapt it based on a particular scheduler. It can work with Godel, schedulers based on the scheduler framework, or even integrate with Volcano. Katalyst-scheduler, based on the scheduler framework (with the core being the scheduler plugin), currently serves as an out-of-the-box scheduler for users to quickly experience Katalyst’s capabilities. Additionally, if users are using a Kubernetes scheduler in production and want to use Katalyst but don’t want to replace the scheduler (e.g., if they have already developed some scheduler plugins), they can integrate some of Katalyst-scheduler’s plugins. Godel is a production-ready scheduler for offline fusion scheduling, offering stronger performance and features in fusion scheduling scenarios. Still, it requires replacing the original scheduler and may not be suitable for all users. In general, it caters to different usage scenarios.
As computing evolves, new cost optimization technologies and open-source projects are expected to emerge.

