Resource Recommendation Algorithms for Crane and VPA
Introduction to VPA
VPA, short for Vertical Pod Autoscaler, is an open-source implementation based on the Google paper Autopilot: Workload Autoscaling at Google Scale. It recommends container resource requests based on historical monitoring data from the containers within pods. In other words, VPA scales by directly modifying the resource requests (and limits, if configured in VPA resources) within the pod.
Key Benefits:
- Increases node resource utilization.
- Suitable for long-running, homogeneous applications.
Limitations:
- Before version 1.27 of Kubernetes do not support in-place upgrades (support in version 1.27), requiring application restarts to apply resource recommendations.
- Less suitable for stateful services due to potential start order dependencies.
- Not ideal for bursty or job-type applications due to limited monitoring data (related issue here).
- Incompatible with HPA. Instead, HPA can be used with custom or external metrics, following Google Cloud’s multidimensional Pod autoscaling approach (VPA for memory, HPA for CPU).
Introduction to Crane
Crane (Cloud Resource Analytics and Economics) is an open-source project by Tencent, designed to reduce costs and increase efficiency in Kubernetes-based environments. Following FinOps standards, Crane offers a comprehensive cloud cost optimization solution for cloud-native users. It includes features such as resource recommendations, elasticity recommendations, intelligent elasticity, and stability enhancements.
This document focuses on Crane’s resource recommendation functionality.
Advantages:
- A single recommendation (CR) for resource control can be applied to all workload types within a namespace, either partially or entirely.
- CR recommendations tend to be conservative (larger), ensuring application performance.
- Supports monitoring data sources like Metrics Server and Prometheus.
Limitations:
- Lacks built-in functionality for automatically applying recommendations; you need to define how to apply these recommendations, which may require custom development.
- Does not provide monitoring metrics for recommendation quality.
Versions: VPA 0.13.0 Crane v0.9.0https://github.com/gocrane/crane/tree/v0.9.0)
Algorithm Principles
Both Crane and VPA calculate recommendations based on historical monitoring data’s percentile values and then amplify these percentile-based recommendations to obtain the final recommendations. They utilize histograms to calculate percentiles, so let’s first introduce the percentile calculation method.
1 Calculating Percentiles Using Histograms
1.1 Histogram Calculation Algorithm Used by Crane
Taking the example of calculating the 95th percentile value from 24 hours of CPU monitoring data, with data points every minute ranging from 0 to 100:
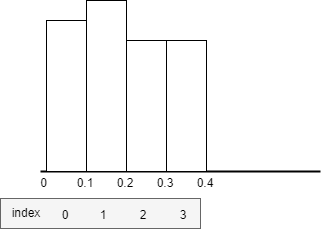
- Each bucket has a size of 0.1, starting with an index of 0. Bucket 0 can hold values in the range
[0, 0.1), with a minimum boundary value of 0. Bucket 1 can hold values in the range[0.1, 0.2), with a minimum boundary value of 0.1. - Each data point is placed into the corresponding bucket based on its numeric value. For example, if a monitoring data point at a certain moment is 1.02, it will be placed into bucket 10.
- When a data point is added to a bucket, the weight of that bucket increases by the value of the data point. The weight of all buckets increases by the value of the data point.
- Calculate
W(95) = 95% * total weight of all buckets. - Start accumulating bucket weights from the smallest to the largest. This weight is denoted as S. When S >= W(95), the index of the bucket at this moment is N. The minimum boundary value of bucket N+1 is the 95th percentile value.
1.2 Histogram Calculation Algorithm Used by VPA
Taking the example of calculating the 95th percentile value from 24 hours of CPU monitoring data, with data points every minute ranging from 0 to 1000.0:
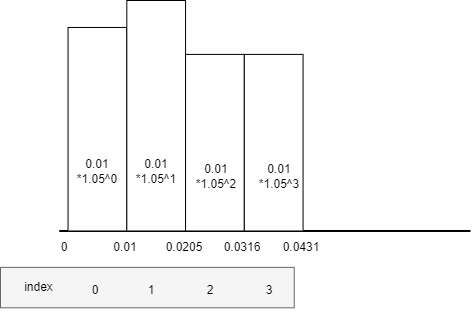
- Bucket indices are represented by N, and the bucket size increases exponentially:
bucketSize = 0.01 * (1.05^N). Bucket 0 has a size of 0.01 and a range of[0, 0.01), while bucket 1 has a size of0.01 * 1.05^1 = 0.0105and a range of[0.01-0.0205). - Data points are placed into buckets based on their numeric values. For instance, if a monitoring data point at a certain moment is 0.032, it will be placed into bucket 3.
- When a data point is added to a bucket, the bucket’s weight increases by
fixed weight * decay factor(details on fixed weight and decay factor are explained later). The weight of all buckets increases byfixed weight * decay factor. - Calculate
W(95) = 95% * total weight of all buckets. - Start accumulating bucket weights from the smallest to the largest. This weight is denoted as S. When S >= W(95), the index of the bucket at this moment is N. The minimum boundary value of bucket N+1 is the 95th percentile value.
1.2.1 Decay Factor and Fixed Weight
Half-life (halfLife): After halfLife time, the weight value decreases to half of its original value. The default halfLife is 24 hours. For example, if the weight value of a data point is 1 now, it will be 0.5 after 24 hours, 0.25 after 48 hours, and 4 if it is newer than 48 hours.
Timestamp of data point (timestamp): The timestamp of the monitoring data.
Reference timestamp (referenceTimestamp): A specific time on the monitoring data (usually the latest midnight timestamp).
Core Concept: Data points before the reference time have lower weights, and data points after the reference time have higher weights.
Fixed Weight for CPU Resources: 0.1
Fixed Weight for Memory Resources: 1
Decay Factor (decayFactor): 2^((timestamp - referenceTimestamp) / halfLife)
2 VPA Recommendation Calculation Process:
VPA provides four recommendation values:
| Name | Explanation |
|---|---|
| target | The final recommendation by VPA. |
| lowerBound | The minimum value for reasonable resource usage by the container. If the container’s resource request is less than this value, VPA considers that the pod needs to be recreated to apply the target recommendation. |
| upperBound | The maximum value for reasonable resource usage by the container. If the container’s resource request is greater than this value, VPA considers that the pod needs to be recreated to apply the target recommendation. |
| uncappedTarget | The original recommendation value without constraints from containerPolicies. |
VPA internally utilizes four Estimators and two Post-processors:
percentileEstimator: Calculates recommendations using percentile values from histograms.
marginEstimator: Amplifies previous recommendations.
minResourcesEstimator: Applies strategies defined by command-line flags –pod-recommendation-min-cpu-millicores and –pod-recommendation-min-memory-mb to ensure recommendations are not lower than these values.
confidenceMultiplier: Scales lowerBound and upperBound recommendations.
IntegerCPUPostProcessor: Rounds CPU recommendations up to the nearest integer.
CappingPostProcessor: Applies minimum and maximum values defined in VPA resources for corresponding containers.
percentileEstimator --> marginEstimator --> minResourcesEstimator --> IntegerCPUPostProcessor (not enabled by default) --> CappingPostProcessor
lowerBound: percentileEstimator --> marginEstimator --> confidenceMultiplier --> minResourcesEstimator --> IntegerCPUPostProcessor (not enabled by default) --> CappingPostProcessor
upperBound: percentileEstimator --> marginEstimator --> confidenceMultiplier --> minResourcesEstimator --> IntegerCPUPostProcessor (not enabled by default) --> CappingPostProcessor
uncappedTarget: percentileEstimator --> marginEstimator --> confidenceMultiplier -Explanation:
Using the example of the target recommendation value:
- First, the percentileEstimator is used to calculate the percentile-based recommendation value. This percentile-based recommendation value is then passed to the marginEstimator to obtain the marginEstimator recommendation value.
- The marginEstimator recommendation value is further passed to the minResourcesEstimator to obtain the minResourcesEstimator recommendation value.
- If the integer CPU estimator is enabled, the minResourcesEstimator recommendation value is passed to the IntegerCPUPostProcessor for processing. The result of this processing is then passed to the CappingPostProcessor for further processing, resulting in the final recommendation value.
2.1 Estimators:
2.1.1 percentileEstimator Recommendation Algorithm
For memory, the index is set to 0 with a bucket size of 10000000. For index N, the bucket size is calculated as 10000000 * 1.05^N. The value range is from 0 to 1e12, and there are a total of 176 buckets.
If a container experiences an Out-Of-Memory (OOM) event, the memory value at the time of OOM is amplified. The amplified memory value is calculated as max(oom memory at the time * oomBumpUpRatio, oom memory at the time + oomMinBumpUp), where the default oomBumpUpRatio is 1.2, and oomMinBumpUp is 100m. If the OOM event occurs outside the aggregation period and the OOM memory value is greater than the most recent OOM value and the most recent memory usage value, or if the OOM event occurs within the aggregation period, the OOM data point is added to the histogram.
For CPU, bucket 0 has a size of 0.01, and for index N, the bucket size is calculated as 0.01 * (1.05^N). The value range is from 0 to 1000, and there are a total of 176 buckets.
The recommendation value is calculated using histograms to compute percentile values, which is the fundamental recommendation value.
2.1.2 marginEstimator Recommendation Algorithm
The recommendation value is equal to the original recommendation value multiplied by (1 + safetyMarginFraction).
2.1.3 confidenceMultiplier Recommendation Algorithm
Relevant Parameters:
| Name | Explanation |
|---|---|
| multiplier | Multiplicative factor. |
| confidence | Confidence factor. min(Monitoring data time in how many 24-hour periods, Number of monitoring data points in a day in minutes) |
| exponent | Exponential factor. |
The recommendation value is calculated as the original recommendation value multiplied by (1 + multiplier / confidence)^exponent.
2.1.4 minResourcesEstimator Recommendation Algorithm
Parameters:
| Name | Explanation |
|---|---|
| minResources | Minimum recommended resource value. For CPU, the minimum recommendation is podMinCPUMillicores. For memory, the minimum recommendation is podMinMemoryMb. |
If the recommendation value is less than minResources, it is set to minResources.
The recommendation value is set to max(minResources, original recommendation value).
2.2 Post-processors
2.2.1 IntegerCPUPostProcessor Logic
This processor only handles CPU recommendations for target, lowerBound, upperBound, and uncappedTarget. It rounds up the CPU recommendation value. For example, if the CPU recommendation is 1100m, it will be rounded up to 2.
2.2.2 CappingPostProcessor Logic
This processor handles target, lowerBound, and upperBound recommendations for containers. It applies the minimum and maximum recommendation value policies specified in the container’s PodResourcePolicy.
2.3 VPA Recommended Parameters
| Parameter | Explanation | Fixed Value or Default Value |
|---|---|---|
| safetyMarginFraction | Fraction of usage added as the safety margin to the recommended request. This represents how much extra allocation should be added to the recommendation, meaning how much additional request value should be requested. | Default Value: 0.15 Configurable via command line using –recommendation-margin-fraction |
| podMinCPUMillicores | Minimum CPU recommendation for a pod. This specifies the minimum CPU recommendation size. | Default Value: 25 Configurable via command line using –pod-recommendation-min-cpu-millicores |
| podMinMemoryMb | Minimum memory recommendation for a pod. This specifies the minimum memory recommendation size. | Default Value: 250 Configurable via command line using –pod-recommendation-min-memory-mb |
| targetCPUPercentile | CPU usage percentile that will be used as a base for CPU target recommendation. This does not affect CPU lower bound, CPU upper bound, or memory recommendations. This represents the percentile value for CPU usage in the target recommendation. | Default Value: 0.9 Configurable via command line using –target-cpu-percentile |
| lowerBoundCPUPercentile | CPU usage percentile for lowerBound recommendation. This represents the percentile value for CPU usage in the lowerBound recommendation. | Fixed Value: 0.5 |
| upperBoundCPUPercentile | CPU usage percentile for upperBound recommendation. This represents the percentile value for CPU usage in the upperBound recommendation. | Fixed Value: 0.95 |
| targetMemoryPeaksPercentile | Memory usage percentile for target recommendation. This represents the percentile value for memory usage in the target recommendation. | Fixed Value: 0.9 |
| lowerBoundMemoryPeaksPercentile | Memory usage percentile for lowerBound recommendation. This represents the percentile value for memory usage in the lowerBound recommendation. | Fixed Value: 0.5 |
| upperBoundMemoryPeaksPercentile | Memory usage percentile for upperBound recommendation. This represents the percentile value for memory usage in the upperBound recommendation. | Fixed Value: 0.95 |
| upperBoundMultiplier | Multiplier factor for confidenceMultiplier in the upperBound recommendation. This is the multiplier used in the confidenceMultiplier for the upperBound recommendation. | Fixed Value: 1.0 |
| upperBoundExponent | Exponential factor for confidenceMultiplier in the upperBound recommendation. This is the exponent used in the confidenceMultiplier for the upperBound recommendation. | Fixed Value: 1.0 |
| lowerBoundMultiplier | Multiplier factor for confidenceMultiplier in the lowerBound recommendation. This is the multiplier used in the confidenceMultiplier for the lowerBound recommendation. | Fixed Value: 0.001 |
| lowerBoundExponent | Exponential factor for confidenceMultiplier in the lowerBound recommendation. This is the exponent used in the confidenceMultiplier for the lowerBound recommendation. | Fixed Value: -2.0 |
3 Resource Recommendation in Crane
Crane follows a five-step recommendation process:
percentileEstimator: Calculates the recommended value based on percentiles obtained from histograms.
marginEstimator: Amplifies the previous recommended values.
targetUtilizationEstimator: Further amplifies the previous recommended values to achieve the desired target utilization percentage.
NormalizedResource: Converts the previous recommended values into the most suitable configuration.
MemoryOOMProtection: Amplifies memory recommended values based on recent OOM (Out Of Memory) events.
3.1 Crane’s Recommendation Process:
cpu: percentileEstimator --> marginEstimator --> targetUtilizationEstimator --> NormalizedResource
memory: percentileEstimator --> marginEstimator --> targetUtilizationEstimator --> MemoryOOMProtection --> NormalizedResourceExplanation:
Using CPU recommended values as an example:
- First, the percentileEstimator calculates percentile-based recommended values. These values are then passed to the marginEstimator, which amplifies them, resulting in the marginEstimator recommended values.
- The marginEstimator recommended values are then passed to the targetUtilizationEstimator, which further amplifies them to achieve the desired target utilization percentage.
- If specifications are enabled, the targetUtilizationEstimator recommended values are passed to NormalizedResource, which looks for the most suitable configuration from the specification-config.
- The final recommended value is returned after processing.
3.2 Crane’s Resource Recommendation Parameters:
| Configuration Items | Default | Description |
|---|---|---|
| cpu-sample-interval | 1m | Metric sampling interval for requesting CPU monitoring data |
| cpu-request-percentile | 0.99 | Target CPU Percentile that is used for VPA |
| cpu-request-margin-fraction | 0.15 | CPU recommended value margin factor. For example, 0.15 means the recommended value is increased by 15%. |
| cpu-target-utilization | 1 | CPU target utilization. For example, 0.8 means the recommended value is divided by 0.8. |
| cpu-model-history-length | 168h | Historical length for CPU monitoring data |
| mem-sample-interval | 1m | Metric sampling interval for requesting Memory monitoring data |
| mem-request-percentile | 0.99 | Target Memory Percentile that is used for VPA |
| mem-request-margin-fraction | 0.15 | Memory recommended value margin factor. For example, 0.15 means the recommended value is increased by 15%. |
| mem-target-utilization | 1 | Memory target utilization. For example, 0.8 means the recommended value is divided by 0.8. |
| mem-model-history-length | 168h | Historical length for Memory monitoring data |
| specification | false | Enable resource specification |
| specification-config | "" | Resource specifications configuration |
| oom-protection | true | Enable OOM Protection |
| oom-history-length | 168h | OOM event history length, ignoring events that are too old |
| oom-bump-ratio | 1.2 | OOM memory bump-up ratio |
3.3 Estimator
3.3.1 percentileEstimator Recommendation Algorithm
For memory, the bucket size is 104,857,600, with a value range of 0 to 104,857,600,000.
For CPU, the bucket size is 0.1, with a value range of 0 to 100.
Recommendation value = Using histogram to calculate the percentile value - this is the most basic recommendation value.
3.3.2 MarginEstimator Recommendation Algorithm
Recommendation value = Original recommendation value * (1 + marginFraction)
Where marginFraction for memory is mem-request-margin-fraction, and for CPU, it’s cpu-request-margin-fraction.
3.3.3 TargetUtilizationEstimator Recommendation Algorithm
Recommendation value = Original recommendation value / targetUtilization
Where targetUtilization for memory is mem-target-utilization, and for CPU, it’s cpu-target-utilization.
3.3.4 NormalizedResource
When specification is enabled, match the configuration set that is the minimum and satisfies (greater than or equal to) the recommendation value from specification-config.
3.3.5 MemoryOOMProtection
If a container has experienced OOM events in the last 7 hours, where the memory value at the time of OOM is oomMemory, if there are no OOM events, oomMemory is set to 0.
Recommendation value = max(max(oomMemory + 100M, oomMemory * oom-bump-ratio), original recommendation value)
Not Mentioned
- In VPA, if the relative time of histogram’s referenceTimestamp exceeds 100 half-lives, the histogram data is scaled.
Related Links
why VPA is not suitable for batch workloads
Automatically adjust pod resource levels with the vertical pod autoscaler
Guide to Kubernetes Autoscaling–Vertical Pod Autoscaler (VPA)

