A Deep Dive into HighNodeUtilization and LowNodeUtilization Plugins with Descheduler
Recently, I have been researching descheduler, primarily to address CPU hotspots on part of nodes in kubernetes clusters. This issue arises when there is a significant difference in CPU usage among nodes, despite the even distribution of pod requests across nodes. As we know, kube-scheduler is responsible for scheduling pods to nodes, while descheduler removes pods, allowing the workload controller to regenerate pods. This, in turn, triggers the pod scheduling process to allocate pods to nodes again, achieving the goal of pod rescheduling and node balancing.
The descheduler project in the community aims to address the following scenarios:
- Some nodes have high utilization and need to balance node utilization.
- After pod scheduling, nodes’ labels or taints do not meet the pod’s pod/node affinity, requiring pod relocation to compliant nodes.
- New nodes join the cluster, necessitating the balancing of node utilization.
- Pods are in a failed state but have not been cleaned up.
- Pods of the same workload are concentrated on the same node.
Descheduler uses a plugin mechanism to extend its capabilities, with plugins categorized into Balance (node balancing) and Deschedule (pod rescheduling) types.
It provides the following plugins:
| Name | Extension Point Implemented | Description |
|---|---|---|
| RemoveDuplicates | Balance | Spreads replicas Ensures that pods of the same workload are spread across different nodes. |
| LowNodeUtilization | Balance | Spreads pods according to pods resource requests and node resources available |
| HighNodeUtilization | Balance | Spreads pods according to pods resource requests and node resources available |
| RemovePodsViolatingInterPodAntiAffinity | Deschedule | Evicts pods violating pod anti-affinity. |
| RemovePodsViolatingNodeAffinity | Deschedule | Evicts pods violating node affinity. |
| RemovePodsViolatingNodeTaints | Deschedule | Evicts pods violating node taints. |
| RemovePodsViolatingTopologySpreadConstraint | Balance | Evicts pods violating TopologySpreadConstraints. |
| RemovePodsHavingTooManyRestarts | Deschedule | Evicts pods having too many restarts. |
| PodLifeTime | Deschedule | Evicts pods that have exceeded a specified age limit. |
| RemoveFailedPods | Deschedule | Evicts pods with certain failed reasons. |
This article focuses on the HighNodeUtilization and LowNodeUtilization plugins for balancing node utilization. However, these plugins rely on request-based statistics to measure node utilization and may not effectively address node CPU overheating (high utilization on some nodes). Studying the execution logic of these plugins can aid in developing custom plugins to address node CPU overheating issues.
This article is based on descheduler v0.28.1.
1 Introduction to the HighNodeUtilization Plugin
The HighNodeUtilization plugin is designed to move pods from nodes with low utilization to nodes with high utilization, coupled with ClusterAutoScaler to remove and destroy (reclaim) idle nodes from the cluster. The primary goal is to enhance node utilization.
In this context, utilization is equivalent to the usage rate of node requests. Node utilization is defined as the ratio of the sum of requests for all pods on a node to the node’s allocatable resources, expressed as NodeUtilization = (PodsRequestsTotal * 100) / nodeAllocatable.
Nodes are classified into underutilized nodes (underutilizedNodes) and overutilized nodes (overutilizedNodes) based on predefined thresholds. Nodes with a request utilization greater than the specified thresholds are considered overutilized (reasonably utilized nodes), while nodes with a utilization less than or equal to the thresholds are considered underutilized nodes.
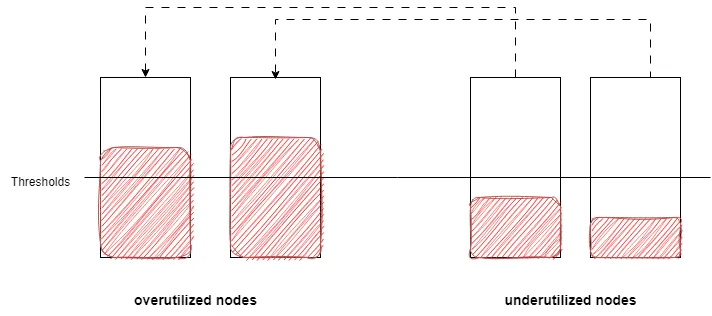
1.1 HighNodeUtilization Configuration Options
The thresholds parameter is a configuration option for the HighNodeUtilization plugin. Additionally, it has two other configuration options: numberOfNodes and evictableNamespaces. numberOfNodes specifies that nodes with a low utilization count less than or equal to this number will not be evicted, and evictableNamespaces specifies namespaces under which pods should be ignored.
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "HighNodeUtilization"
args:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
evictableNamespaces:
exclude:
- "kube-system"
- "namespace1"
plugins:
balance:
enabled:
- "HighNodeUtilization"2 Introduction to the LowNodeUtilization Plugin
The LowNodeUtilization plugin is designed to move pods from nodes with high utilization to nodes with low utilization, aiming to balance the overall node utilization.
Similar to the HighNodeUtilization plugin, utilization here refers to the usage rate of node requests. Node utilization is calculated as the ratio of the sum of requests for all pods on a node to the node’s allocatable resources, expressed as NodeUtilization = (PodsRequestsTotal * 100) / nodeAllocatable.
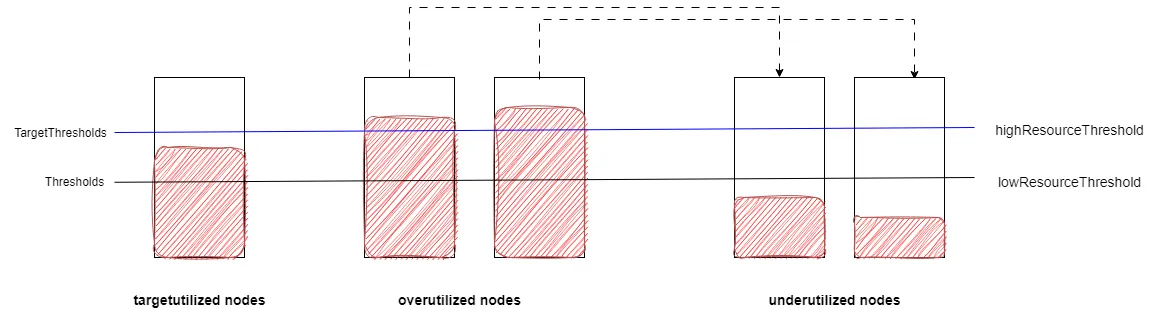
This plugin categorizes nodes into overutilized nodes (overutilizedNodes), underutilized nodes (underutilizedNodes), and target utilization nodes (targetutilizedNodes). The distinction is based on thresholds, targetThresholds, and useDeviationThresholds. Unlike HighNodeUtilization, LowNodeUtilization has two thresholds: a low-watermark threshold (lowResourceThreshold) and a high-watermark threshold (highResourceThreshold). The useDeviationThresholds parameter determines whether the threshold watermark is based on the average utilization of requests across all nodes.
When useDeviationThresholds is disabled, thresholds represents the low-watermark threshold (lowResourceThreshold), and targetThresholds represents the high-watermark threshold (highResourceThreshold). Nodes with utilization rates below the low-watermark threshold (lowResourceThreshold) for all resource types (excluding unschedulable nodes) are considered underutilized nodes (underutilizedNodes). Nodes with the utilization rate of at least one resource type exceeding the high-watermark threshold (highResourceThreshold) are considered overutilized nodes (overutilizedNodes). Nodes with utilization rates between lowResourceThreshold and highResourceThreshold are considered target utilization nodes (targetutilizedNodes).
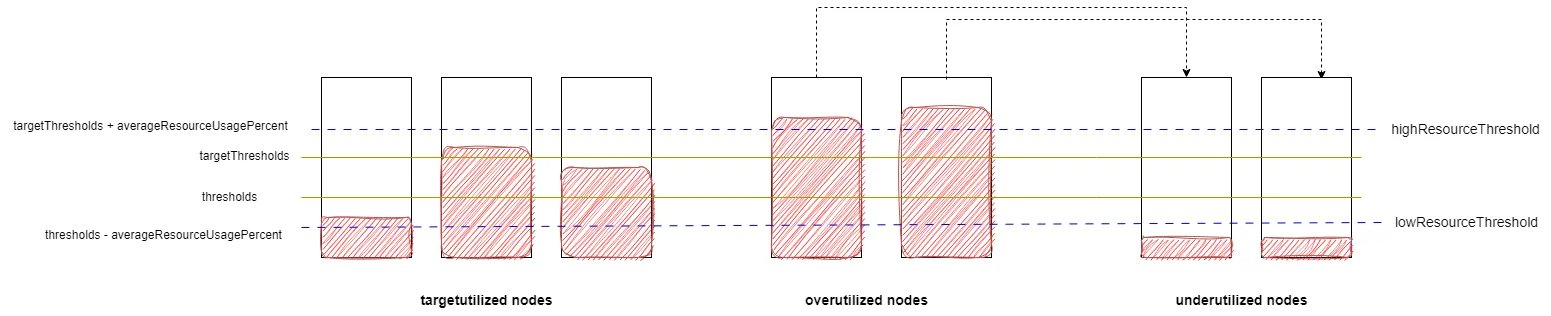
When useDeviationThresholds is enabled, the average usage rate of requests across all nodes (averageResourceUsagePercent) is first calculated. The low-watermark threshold (lowResourceThreshold) is set as thresholds - averageResourceUsagePercent, and the high-watermark threshold (highResourceThreshold) is set as targetThresholds + averageResourceUsagePercent. The node categorization rules remain the same as when useDeviationThresholds is disabled.
2.1 LowNodeUtilization Configuration Options
The configuration options include useDeviationThresholds, thresholds, targetThresholds, numberOfNodes, and evictableNamespaces.
- thresholds: Determines whether a node is classified as having low utilization.
- targetThresholds: Determines whether a node is classified as having high utilization.
- useDeviationThresholds: Represents whether the threshold watermark is based on the average utilization of requests across all nodes.
- numberOfNodes: Nodes with low utilization counts less than or equal to this number will not be evicted.
- evictableNamespaces: Pods in these namespaces will be ignored.
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "LowNodeUtilization"
args:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
plugins:
balance:
enabled:
- "LowNodeUtilization"3 Other Configuration Options
The following configuration options are global settings for descheduler.
| Name | Type | Default Value | Description |
|---|---|---|---|
nodeSelector | string | nil | Used for the PreEvictionFilter extension point. The default Evictor implements this extension point. When the nodeFit is enabled in the default Evictor configuration, it filters out target nodes and determines if there are nodes capable of accommodating the pods to be evicted from these nodes. |
maxNoOfPodsToEvictPerNode | int | nil | Maximum number of pods evicted from each node (summed through all strategies). If the cumulative number of pods evicted from a node exceeds this value, the eviction process for that node is stoped. |
maxNoOfPodsToEvictPerNamespace | int | nil | Maximum number of pods evicted from each namespace (summed through all strategies). If the cumulative number of pods evicted from a namespace reaches this value, pods from that namespace are ignored. |
Default Evictor Configuration Options
| Name | Type | Default Value | Description |
|---|---|---|---|
nodeSelector | string | nil | Limits the nodes that are processed. Only nodes that pass the filtering will undergo rescheduling. |
evictLocalStoragePods | bool | false | Allows eviction of pods with local storage. |
evictSystemCriticalPods | bool | false | Warning: Will evict Kubernetes system pods. Allows eviction of pods with any priority, including system pods like kube-dns. |
ignorePvcPods | bool | false | Determines whether pods with Persistent Volume Claims (PVC) should be evicted or ignored. |
evictFailedBarePods | bool | false | Allows eviction of pods without owner references and in the failed phase. |
labelSelector | metav1.LabelSelector | (See label filtering). Pods matching this LabelSelector will be evicted. | |
priorityThreshold | priorityThreshold | (See priority filtering). Pods with a priority lower than this level will be evicted. | |
nodeFit | bool | false | (See node fit filtering). When nodeFit is enabled, it uses the nodeSelector from the global configuration to filter out target nodes and determines if there are nodes capable of accommodating the pods to be evicted from these nodes. |
4 Execution Flow
The execution flow for the lowNodeUtilization and highNodeUtilization plugins is the same; the only difference lies in the source and destination nodes for pod movement. In other words, the criteria for selecting nodes (for pod eviction) differ.
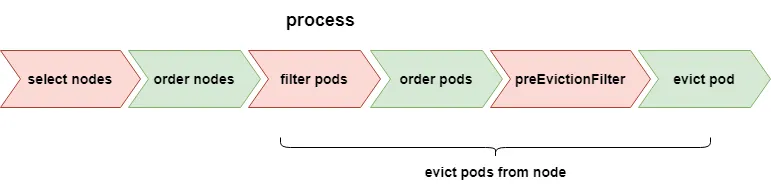
Execution Flow:
- Select Nodes: Choose nodes where pod eviction will be performed.
- Order Nodes: Sort nodes.
- Filter Pods: Select a list of pods on nodes that can be evicted.
- Order Pods: Sort pods.
- Pre-Eviction Filter: Check if pods meet restriction conditions.
- Evict Pod: Execute pod eviction.
4.1 Select Nodes
Filter nodes from all clusters that satisfy the following two conditions:
- Nodes matching the descheduler global configuration nodeSelector.
- For the lowNodeUtilization plugin, nodes with high utilization (
highResourceThreshold), and for the highNodeUtilization plugin, nodes with low utilization (underutilizedNodes).
Next, categorize the nodes based on the methods mentioned in the introduction of the plugins. The purpose of this categorization is to determine whether to proceed with the subsequent steps. For example, if no nodes meet the eviction conditions, there is no need to proceed with the following steps.
The decision to execute the subsequent steps is based on the following conditions:
For the lowNodeUtilization plugin, do not proceed with the subsequent steps if any of the following conditions are met:
- The number of underutilized nodes is 0.
- The number of underutilized nodes is less than or equal to the
NumberOfNodesconfigured in the lowNodeUtilization plugin. - The number of overutilized nodes is 0.
- The number of underutilized nodes is equal to the number of nodes selected.
For the highNodeUtilization plugin, do not proceed with the subsequent steps if any of the following conditions are met:
- The number of underutilized nodes is 0 (indicating that all selected nodes are overutilized).
- The number of underutilized nodes is less than or equal to the
NumberOfNodesconfigured in the highNodeUtilization plugin. - The number of underutilized nodes is equal to the number of nodes selected (indicating that all selected nodes are overutilized).
- The number of overutilized nodes is 0 (indicating that all selected nodes are underutilized).
4.2 Order Nodes
Sort the nodes selected above. For the lowNodeUtilization plugin, nodes are sorted based on the sum of requests for all resource types. Nodes with a larger sum come first. For the highNodeUtilization plugin, nodes are sorted based on the sum of requests for all resource types. Nodes with a smaller sum come first.
4.3 Evict Pod from Node
Following the order of nodes determined above, perform pod eviction on each node. The subsequent processes involve the sub-processes of executing pod eviction on the node, including filtering pods, ordering pods, pre-eviction filtering, and pod eviction.
4.3.1 Filter Pods
Filter out pods on the node that can be evicted, including actively marked pods for eviction and other pods that meet certain conditions. Actively marked pods for eviction are those with the annotation “descheduler.alpha.kubernetes.io/evict” in their annotations.
Other pods that meet certain conditions are those that match all the rules below:
- Not generated by a DaemonSet.
- Not a static pod.
- Not a mirror pod.
- The pod has not been deleted.
- When
EvictFailedBarePodsin the default Evictor configuration is set to true, either the pod has an ownerReference, or the pod has no ownerReference and is in the Failed phase. - When
EvictFailedBarePodsin the default Evictor configuration is set to false, the pod has an ownerReference. - When
EvictSystemCriticalPodsin the default Evictor configuration is set to false and noPriorityThresholdis configured, the pod’s priority is less than systemCritical (priority is 200000000). - When
EvictSystemCriticalPodsin the default Evictor configuration is set to false andPriorityThresholdis configured, the pod’s priority is less than the priority defined inPriorityThreshold(priority is read frompriorityThreshold.Value, and if not set, it is read frompriorityThreshold.Name). - When
EvictLocalStoragePodsin the default Evictor configuration is set to false, the pod’s volume does not have HostPath and EmptyDir. - When
IgnorePvcPodsin the default Evictor configuration is set to true, the pod’s volume does not have PersistentVolumeClaim. - When a LabelSelector is set in the default Evicor configuration, the pod matches the LabelSelector.
4.3.2 Order Pods
Sort the pods filtered above. The sorting rules are as follows: the first sorting field is the pod’s priority, and the second sorting field is the pod’s QoS class. In other words, sort pods based on priority first, with pods without priority coming first. If two pods have priorities, they are sorted from smallest to largest. If the priorities are the same (both pods without priority are considered to have the same priority), they are sorted in the order of BestEffort, Burstable, Guaranteed. If the QoS is the same, the order remains unchanged.
4.3.3 Pre-Eviction Filter
This step mainly checks whether nodes are available for scheduling and whether pods match the namespace whitelist. It is primarily designed to consider the stability of applications after pod eviction, ensuring that there are nodes available for scheduling and limiting the number of pod evictions in namespaces for maintaining application availability.
When the NodeFit is set to true in the Default Evictor configuration, it checks whether the pod can be scheduled. The logic is as follows:
- Obtain a list of all nodes based on the NodeSelector in the Default Evictor configuration (if NodeSelector is empty, it includes all nodes in the cluster), and then filter out all ready nodes.
- Check if there is a node that satisfies all the following conditions. This mimics the predicates algorithm used by the scheduler to ensure that after evicting pods, new pods can be scheduled using the same algorithm. This is why plugins use requests to calculate node resource usage (similar to how kube-scheduler schedules based on requests).
- Satisfies the pod’s
Spec.NodeSelectorandSpec.Affinity.RequiredDuringSchedulingIgnoredDuringExecution. - Pod’s
Spec.Tolerationscan toleratenode.Spec.Taints(considering only NoSchedule and NoExecute taints). - Not on the node where the pod is located, and the node’s remaining resources satisfy the pod’s request.
- The node is in a schedulable state.
- Satisfies the pod’s
If a node that can be scheduled is found using the above algorithm, it undergoes a whitelist filter (checking whether the pod’s namespace matches the evictableNamespaces.exclude in the plugin configuration). Otherwise, eviction is not performed on this pod.
If the pod’s namespace matches evictableNamespaces.exclude in either the “lowNodeUtilization” or “highNodeUtilization” configuration, eviction is not performed on this pod. In other words, if no node can be scheduled or if the pod’s namespace matches the namespace whitelist in “lowNodeUtilization” or “highNodeUtilization,” eviction is not performed on this pod.
4.3.4 Evict Pod
First, execute the global strategies of descheduler, limiting the number of pods evicted per node and the number of pod evictions per namespace. The global configurations maxNoOfPodsToEvictPerNode limit the number of pod evictions per node, and maxNoOfPodsToEvictPerNamespace limits the number of pod evictions per namespace.
If the pod passes the above strategic restrictions, perform the final pod eviction action. Otherwise, do not perform eviction on this pod.
4.3.5 When to Stop Evicting Pods on a Node
After each pod eviction, check whether the node has reached a reasonable (desired) utilization. If it reaches the desired utilization, the eviction process for this node ends, and the next pod eviction on the node continues.
For the lowNodeUtilization plugin to reach a reasonable utilization: The node reaches the expected utilization (i.e., the usage rate of requests for all resource types is less than or equal to the high water threshold highResourceThreshold). The node transitions from being an overutilized node (overutilizedNodes) to a reasonably utilized node (targetutilizedNodes). Alternatively, all underutilized nodes have at least one resource (CPU, memory, pods, etc.) with a request less than or equal to 0 (i.e., underutilized nodes have no resources left to allocate).
For the highNodeUtilization plugin to reach a reasonable utilization: In all overutilized nodes, the request value for at least one resource in the remaining resources is less than or equal to 0. In other words, there is at least one resource (CPU, memory, pods, etc.) with a request less than or equal to 0 in the total remaining (unallocated) resources of overutilized nodes.
There is another scenario that can end the eviction process for a node: If the number of pods evicted from a node reaches the global strategic limit (configured in the global settings as maxNoOfPodsToEvictPerNode), this applies to both the highNodeUtilization and lowNodeUtilization plugins.
5 Existing Issues
However, using requests to measure resource utilization does not accurately reflect the actual resource usage on nodes, making it unsuitable for production use. There is an open issue in the community, “Use actual node resource utilization in the strategy ‘LowNodeUtilization’,” tracking this problem. There are two pull requests addressing this issue: “real utilization descheduler #1092” and “feat: support TargetLoadPacking strategy.”
Descheduler relies on the workload controller and scheduler mechanisms to ensure that after evicting a pod, the workload to which the pod belongs can generate a new pod, and the scheduler will then schedule this new pod to the ideal target node. However, the scheduler may not always place the new pod on the ideal target node. There are also cases where a newly created pod might be scheduled back to the original node, as reported in the community issue “LowNodeUtilization does not take into account podAntiAffinity when choosing a pod to evict.” Although descheduler has the nodeFit feature (checking whether a pod can be scheduled), this code does not cover all kube-scheduler logic. Even if all scheduler logic is implemented, descheduler cannot perceive user-customized scheduler logic or changes to kube-scheduler configurations (currently, nodeFit cannot be configured for enablement or extension). For instance, the highNodeUtilization documentation recommends using the MostAllocated scoring strategy alongside kube-scheduler.
There are several related issues regarding the extension of nodeFit:
- NodeFit Specification
- Consider implementing pod (anti)affinity checks in NodeFit
- The getTargetNodes in RemoveDuplicates does not respect node resources and can mistakenly evict pods
- nodeFit doesn’t handle preferredDuringSchedulingIgnoredDuringExecution (RemovePodsViolatingNodeAffinity)
- NodeFit logic is incompatible with “includeSoftConstraints” option.
- NodeFit doesn’t skip checking of resources which are configured as ignoredByScheduler
- nodeFit = false doesn’t work as expected with RemovePodsViolatingNodeAffinity
Another issue is that after evicting pods, multiple newly created pods may concentrate on specific nodes (for the lowNodeUtilization plugin), potentially causing a loop (pod eviction → pod generation → pod scheduling → pod eviction).
If, at the moment of pod eviction, newly created pods generated due to non-eviction reasons (e.g., scaling up) occupy resources on the target node, there may be a scenario where “newly generated pods” have no nodes available for scheduling. This is because descheduler makes decisions based on outdated node information, considering that node information is static, while it is dynamically changing. Koordinator’s descheduler addresses this issue.
For the requirement to decommission nodes by concentrating pods on specific nodes using the highNodeUtilization plugin and then decommissioning idle nodes, this is not achievable when there are no high-utilization nodes in the cluster. There is an open issue regarding this: “HighNodeUtilization does nothing when all nodes are underutilized.”
It’s essential to note that pods with a replica count of 1 will also undergo eviction. You can set a PodDisruptionBudget to avoid this scenario. The relevant issue is “descheduler when ReplicaSet=1.”
For adding plugins and custom filters, the code needs to be placed within the descheduler project (in-tree). However, there are some limitations, such as the inability to extend the node’s pod sorting algorithm. An issue addressing this is “Introduce sort and preEvictionSort extension points.” Therefore, the community is working on implementing a scheduler framework to address these issues. The proposal is outlined in “Descheduler Framework Proposal.” However, progress has been slow, as indicated in “Descheduling framework wrap up.”
6 Summary
The highNodeUtilization and lowNodeUtilization plugins aim to balance node utilization using requests to calculate node utilization. The goal is to keep nodes either highly utilized or underutilized. The highNodeUtilization plugin strives to keep nodes highly utilized, while the lowNodeUtilization plugin aims for low utilization.
Due to the use of requests to calculate resource utilization, the lowNodeUtilization plugin cannot address the issue of CPU overheating on nodes. To solve the problem of CPU overheating, using a scheduler or plugin based on actual node loads in conjunction with descheduler can balance node resource usage. Some schedulers or plugins based on actual loads include Trimaran, crane, and koordinator. An example of a load-aware
descheduler based on actual loads is koordinator load-aware-descheduling, which also utilizes koord-scheduler’s resource reservation mechanism to ensure that pods can be scheduled after eviction.
Descheduler currently faces challenges as its strategies may not meet various requirements, and extending these strategies involves invasive code changes. The community is working on a scheduler framework to address these challenges.

