Analysis of 'an error occurred when try to find container' Errors in Kubernetes Pod Removal Processes
About 4 months ago, while troubleshooting a bug in the CNI plugin that caused pod removal failures, I examined the deletion process of Kubernetes 1.23 version pods. In the kubelet logs, I frequently encountered the error “an error occurred when try to find container,” which I had previously ignored. This time, I decided to analyze the root cause of this error.
This article will analyze the following aspects:
- Introduction to the core components of pod lifecycle management in kubelet.
- Analysis of the actual pod removal process based on the logs output during the pod removal process in kubelet.
Before we begin, if you ask me how serious this error is and what impact it has, my answer is that it doesn’t matter. This issue is caused by inconsistencies in asynchronous and cached information, and it does not affect the execution of the pod deletion and cleanup process. If you want to know the reason, continue reading; if not, you can close this article directly because it is lengthy and not suitable for troubleshooting.
Pod Removal Process Series Articles:
Kubelet Bug: Sandbox Not Cleaned Up - Unraveling Retention Issues
Exploring Mirror Pod Deletion in Kubernetes: Understanding its Impact on Static Pod
This analysis focuses only on the “an error occurred when try to find container” error encountered during the pod removal process. The reasons for encountering this error in other situations may vary.
Environment: kubelet version 1.23.10, log level 4
1 Log Error Examples
E0731 17:20:16.176440 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": not found" containerID="248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a"
I0731 17:20:16.176478 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a} err="failed to get container status \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": rpc error: code = NotFound desc = an error occurred when try to find container \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": not found"E0731 17:16:43.822332 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"cb2bbdc9ae26e1385e012072a4e0208d91fc027ae1af89cf1432ff3173014d32\": not found" containerID="cb2bbdc9ae26e1385e012072a4e0208d91fc027ae1af89cf1432ff3173014d32"2 Components in kubelet that affect pod deletion
Kubelet launches a goroutine to perform pod lifecycle management. It obtains the latest state of pods from podConfig and controls the execution of pod creation and deletion, as well as pod health check management.
This goroutine executes the (*Kubelet).syncLoop method, which includes branches for podConfig, sync, housekeeping, pleg, livenessManager, readinessManager, and startupManager in a select statement.
podWorkers: All pod operations are executed through podWorker, which controls the execution of pod creation and destruction, maintaining various states and the logic for state transitions. Each pod corresponds to a podWorker, which has a separate goroutine executing podWorkerLoop. When notified, it performs different logic based on its current state.
When podWorker is in syncPod state, it executes syncPod (creates and updates pod status).
When podWorker is in terminating state, it executes syncTerminatingPod (stops pod containers) and transitions the state to terminated.
When podWorker is in terminated state, it executes syncTerminatedPod (updates pod status and waits for volume unmounting and removal of the pod’s cgroup directory) and transitions to finished.
When podWorker is in finished state, it does nothing. It waits for housekeeping to execute podWorker recycling and deletion.
podConfig: Aggregates pods from apiserver, file, and http channels (more information in the previous article kubelet podConfig–Providing Pods Running on kubelet). The syncLoop receives ADD, UPDATE, DELETE, RECONCILE, REMOVE events from podConfig and takes corresponding actions.
ADD event: Sends a SyncPodCreate event, notifying podWorker to execute podWorkerLoop logic, executing syncPod (creates pod and updates pod status).
UPDATE event: Sends a SyncPodUpdate event, notifying podWorker to execute podWorkerLoop logic, executing syncPod (tunes whether the pod reaches the expected state and updates pod status).
DELETE event: Sends a SyncPodUpdate event, notifying podWorker to execute podWorkerLoop logic, executing syncTerminatingPod (stops pod containers) and syncTerminatedPod (updates pod status and waits for volume unmounting and removal of the pod’s cgroup directory).
REMOVE event: Sends a SyncPodKill event, notifying podWorker to execute podWorkerLoop logic. If podWorker is in the finished state, it does nothing; otherwise, it executes syncTerminatingPod.
RECONCILE: If there are ReadinessGates conditions in pod status, it sends a SyncPodSync event, notifying podWorker to execute podWorkerLoop logic, executing syncPod (tunes whether the pod reaches the expected state and updates pod status). If the pod is evicted, it removes all exited containers from the pod.
sync: Executes every second to instruct podWorkers that have completed execution (including those that have completed or encountered errors) to re-execute.
housekeeping: Performs various cleanup tasks, such as removing podWorkers for pods that no longer exist, stopping and deleting probe workers for terminated pods, removing containers for pods that have been deleted but are still running (notifying podWorkers to execute termination with a graceful stop time of 1), cleaning up cgroup directories for non-existent pods, removing volumes and pod directories for non-existent pods, and deleting mirror pods (corresponding to non-existent static pods), etc.
pleg: Listens for various events of pod containers (container start, delete, stop events, etc.). When there are container start or stop events, it notifies the corresponding podWorker to re-execute. For container stop events, it also notifies podContainerDeletor to perform container cleanup.
LivenessManager, readinessManager, and startupManager do not affect pod deletion behavior and are therefore not discussed here.
garbageCollector: Executes separately once a minute, including image cleanup and cleanup of exiting containers (including sandboxes).
statusManager: Responsible for periodically updating pod status. When a pod is in the terminated state and the cgroup does not exist, and the volume has been unmounted, it performs the final deletion (setting DeletionGracePeriodSeconds of the pod to 0).
The syncLoop is like a restaurant, where dishes are equivalent to pods. PodConfig provides customer orders, sync manages the progress of serving dishes (prompting for slow dishes), housekeeping cleans and tidies tables, pleg responds to customer needs like adding water and settling the bill, and livenessManager, readinessManager, and startupManager inspect the dishes (redoing those that are not good).
PodWorkers are like chefs and waiters in the restaurant, responsible for preparing dishes, cleaning utensils, and handling leftover food.
The garbageCollector is like a garbage disposal station, clearing kitchen waste.
3 Analysis of Pod Removal Process
After introducing the concepts above, let’s analyze the pod deletion process based on the logs output by kubelet. Note that this is just one of the deletion processes, and due to asynchronous operations, caching, and the randomness of the select statement, there can be many variations in the actual process.
The complete log can be found kubelet log.
Firstly, the podConfig receives an event indicating that a pod is being deleted (when the pod’s DeletionTimestamp is not nil and DeletionGracePeriodSeconds is not 0):
I0731 17:16:31.865371 354472 kubelet.go:2130] "SyncLoop DELETE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]The podWorker starts the teardown process for stopping the pod’s containers and sandbox:
I0731 17:16:31.865402 354472 pod_workers.go:625] "Pod is marked for graceful deletion, begin teardown" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:31.865427 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1
I0731 17:16:31.865457 354472 pod_workers.go:1005] "Pod worker has observed request to terminate" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:31.865468 354472 kubelet.go:1795] "syncTerminatingPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
.......
I0731 17:16:32.257408 354472 kubelet.go:1873] "Pod termination stopped all running containers" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257421 354472 kubelet.go:1875] "syncTerminatingPod exit" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257432 354472 pod_workers.go:1050] "Pod terminated all containers successfully" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257468 354472 pod_workers.go:988] "Processing pod event done" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1The podWorker then proceeds to terminate the pod:
I0731 17:16:32.257476 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=2
......
I0731 17:16:32.372412 354472 kubelet.go:1883] "syncTerminatedPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
.....
I0731 17:16:32.372533 354472 volume_manager.go:446] "Waiting for volumes to unmount for pod" pod="default/test-nginx-976fbbd77-m2tqs"
I0731 17:16:32.372851 354472 volume_manager.go:473] "All volumes are unmounted for pod" pod="default/test-nginx-976fbbd77-m2tqs"
I0731 17:16:32.372863 354472 kubelet.go:1896] "Pod termination unmounted volumes"
.....
I0731 17:16:32.380794 354472 kubelet.go:1917] "Pod termination removed cgroups" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.380871 354472 kubelet.go:1922] "Pod is terminated and will need no more status updates" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.380883 354472 kubelet.go:1924] "syncTerminatedPod exit" Following this, containers and the sandbox exit, triggering the PLEG (Pod Lifecycle Event Generator) to remove the containers:
I0731 17:16:32.372899 354472 kubelet.go:2152] "SyncLoop (PLEG): event for pod" pod="default/test-nginx-976fbbd77-m2tqs" event=&{ID:5011243d-6324-41e3-8ee8-9e8bb33f04b0 Type:ContainerDied Data:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e}
I0731 17:16:32.372929 354472 kubelet.go:2152] "SyncLoop (PLEG): event for pod" pod="default/test-nginx-976fbbd77-m2tqs" event=&{ID:5011243d-6324-41e3-8ee8-9e8bb33f04b0 Type:ContainerDied Data:ae68335cc5733a4c2fc5c15baed083f94a2d05a6b360b1045c9b673e119f8538}
I0731 17:16:32.372946 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393287 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393300 354472 scope.go:110] "RemoveContainer" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
E0731 17:16:32.398137 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.398175 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e} err="failed to get container status \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found"Next, podConfig receives another deletion event (due to statusManager executing deletion with DeletionGracePeriodSeconds set to 0), but since the podWorker is in the finished state, it doesn’t trigger further actions:
I0731 17:16:32.394625 354472 kubelet.go:2130] "SyncLoop DELETE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]
I0731 17:16:32.394654 354472 pod_workers.go:611] "Pod is finished processing, no further updates" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0After that, podConfig detects that the pod is removed from the API server:
I0731 17:16:32.398009 354472 kubelet.go:2124] "SyncLoop REMOVE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]
I0731 17:16:32.398032 354472 kubelet.go:1969] "Pod has been deleted and must be killed" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0The housekeeping process kicks in, removing the podWorker and then creating a new one to execute the termination of the pod:
I0731 17:16:33.810883 354472 kubelet.go:2202] "SyncLoop (housekeeping)"
I0731 17:16:33.820842 354472 kubelet_pods.go:1082] "Clean up pod workers for terminated pods"
I0731 17:16:33.820869 354472 pod_workers.go:1258] "Pod has been terminated and is no longer known to the kubelet, remove all history" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
......
I0731 17:16:33.820908 354472 kubelet_pods.go:1134] "Clean up orphaned pod containers" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.820927 354472 pod_workers.go:571] "Pod is being synced for the first time" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.820938 354472 pod_workers.go:620] "Pod is orphaned and must be torn down" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
0731 17:16:33.821092 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1
I0731 17:16:33.821127 354472 pod_workers.go:1005] "Pod worker has observed request to terminate" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
........
I0731 17:16:33.821138 354472 kubelet.go:1795] "syncTerminatingPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.821149 354472 kubelet.go:1804] "Pod terminating with grace period" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 gracePeriod=1
I0731 17:16:33.821198 354472 kuberuntime_container.go:719] "Killing container with a grace period override" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e" gracePeriod=1
I0731 17:16:33.821212 354472 kuberuntime_container.go:723] "Killing container with a grace period" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e" gracePeriod=1
I0731 17:16:33.821305 354472 event.go:294] "Event occurred" object="default/test-nginx-976fbbd77-m2tqs" kind="Pod" apiVersion="v1" type="Normal" reason="Killing" message="Stopping container nginx"
E0731 17:16:33.822425 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:33.822479 354472 kuberuntime_container.go:732] "Container exited normally" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
.......
I0731 17:16:33.892542 354472 kubelet.go:1815] "syncTerminatingPod exit" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.892552 354472 pod_workers.go:1081] "Pod terminated all orphaned containers successfully and worker can now stop" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.892567 354472 pod_workers.go:969] "Processing pod event done" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1The housekeeping process triggers again, leading to the removal of the podWorker:
I0731 17:16:35.810945 354472 kubelet.go:2202] "SyncLoop (housekeeping)"
I0731 17:16:35.820522 354472 kubelet_pods.go:1082] "Clean up pod workers for terminated pods"
I0731 17:16:35.820564 354472 pod_workers.go:1258] "Pod has been terminated and is no longer known to the kubelet, remove all history" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0Finally, the garbageCollector process removes the sandbox and the pod’s log directory:
I0731 17:16:51.742500 354472 kuberuntime_gc.go:171] "Removing sandbox" sandboxID="ae68335cc5733a4c2fc5c15baed083f94a2d05a6b360b1045c9b673e119f8538"
I0731 17:16:51.954568 354472 kuberuntime_gc.go:343] "Removing pod logs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:51.955194 354472 kubelet.go:1333] "Container garbage collection succeeded"Summary of the Pod Removal Process in this Example
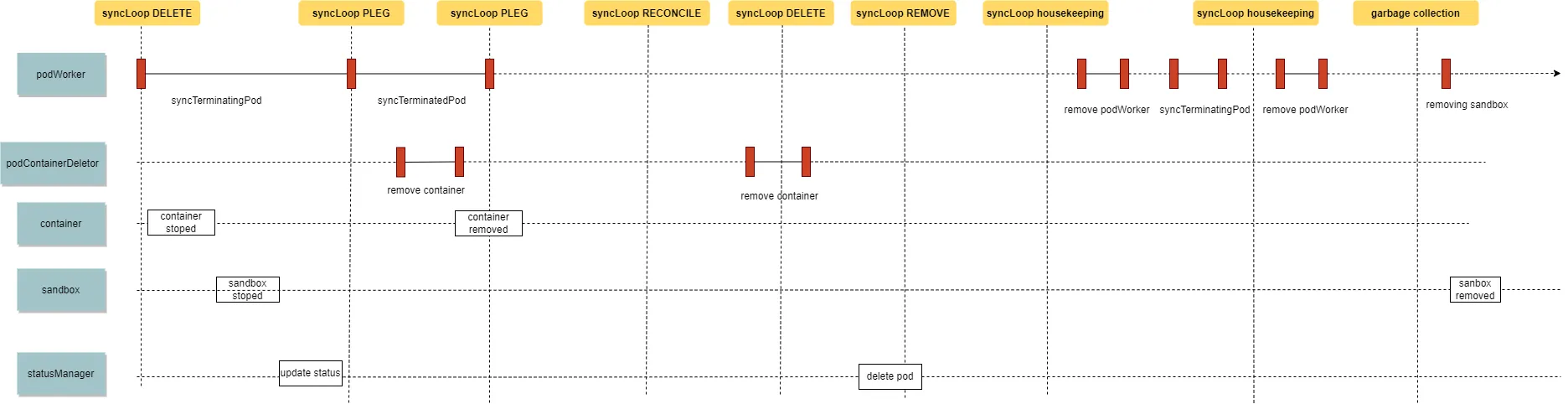
3.1 Handling Process for Pod Removal
Event Trigger:
podConfigreceives an event indicating the pod has been deleted from the API server.Termination Execution:
podWorkerreceives the notification and executes the termination of the pod. This includes stopping the containers and sandbox, as well as terminating and removing liveness, readiness, and startup probes. After completion,podWorkertransitions to the terminated state.Post-Termination Actions:
podWorkercontinues with actions related to the terminated pod, such as updating the pod status with container status set to Terminated, removing the pod’s cgroup, and waiting for the volume unmount of the pod to complete. After completion,podWorkertransitions to the finished state.Container Removal: The Pod Lifecycle Event Generator (
PLEG) detects the stopping of containers and executes the removal of containers.Status Update:
podConfigreceives an update on the pod status from the API server.Final Deletion Request:
kubelet’sstatusManagerinitiates the final deletion request.Second Deletion Event:
podConfigreceives another event indicating the pod’s deletion from the API server.Disappearance Detection:
podConfigdetects the pod’s disappearance from the API server and notifiespodWorkerto execute actions. However, sincepodWorkeris in the finished state, no actions are taken.Housekeeping Trigger: The
housekeepingprocess is triggered, removing the existingpodWorkerand creating a new one. It notifies the newpodWorkerto stop the pod’s containers with a graceful termination period of 1.Second Housekeeping Trigger: Another housekeeping trigger results in the removal of the newly created
podWorker.Garbage Collection: The
garbageCollectorprocess removes the sandbox and the pod’s log directory.
4 Analysis of Error Occurrences
Two instances of the error “an error occurred when trying to find the container” are observed in the logs.
4.1 First Occurrence
During the Pod Lifecycle Event Generator (PLEG) execution triggered by the exit of the container and sandbox, an attempt is made to remove the container twice. The error occurs during the second attempt:
I0731 17:16:32.393287 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393300 354472 scope.go:110] "RemoveContainer" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
E0731 17:16:32.398137 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when trying to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.398175 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e} err="failed to get container status \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": rpc error: code = NotFound desc = an error occurred when trying to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found"4.1.1 Analysis
When an event is triggered in PLEG, if the event type is “ContainerDied” (container exited), and the pod is evicted or “podWorker is in the terminated state,” it notifies podContainerDeletor to remove all exited containers under this pod. If the event type is “ContainerDied” (container exited), the pod is still in the running state, and the number of exited containers in the pod exceeds the kubelet’s configured threshold for retaining exited containers, then it removes these exited containers.
Since PLEG has already triggered container removal during the first attempt, the second attempt encounters the error as the container is no longer present.
pkg/kubelet/pod_container_deletor.go#L46-L55
func newPodContainerDeletor(runtime kubecontainer.Runtime, containersToKeep int) *podContainerDeletor {
buffer := make(chan kubecontainer.ContainerID, containerDeletorBufferLimit)
go wait.Until(func() {
for {
id := <-buffer
if err := runtime.DeleteContainer(id); err != nil {
klog.InfoS("DeleteContainer returned error", "containerID", id, "err", err)
}
}
}, 0, wait.NeverStop)pkg/kubelet/kuberuntime/kuberuntime_container.go#L962-L973
// removeContainerLog removes the container log.
func (m *kubeGenericRuntimeManager) removeContainerLog(containerID string) error {
// Use log manager to remove rotated logs.
err := m.logManager.Clean(containerID)
if err != nil {
return err
}
status, err := m.runtimeService.ContainerStatus(containerID)
if err != nil {
return fmt.Errorf("failed to get container status %q: %v", containerID, err)
}4.2 Second Occurrence
During the first housekeeping trigger, when podWorker attempts to stop the container, an error occurs:
E0731 17:16:33.822425 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when trying to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1f0b8612136c08030486ae1fde12238479b9e"4.2.1 Analysis
During the execution of housekeeping-related logic, podWorker is first removed, and then the running pod list is retrieved from the cache. If a pod is present in the list but not in podWorkers, or its podWorker state is not “SyncPod” or “Terminating,” podWorker is used to stop the container. In this case, the container has already been removed in earlier steps, leading to the “not found” error.
This inconsistency arises because the pod is still listed as running in the cache, even though it has been stopped. As a result, attempting to stop the container results in the error.
pkg/kubelet/kubelet_pods.go#L1129-L1199
workingPods := kl.podWorkers.SyncKnownPods(allPods)
allPodsByUID := make(map[types.UID]*v1.Pod)
for _, pod := range allPods {
allPodsByUID[pod.UID] = pod
}
// Identify the set of pods that have workers, which should be all pods
// from config that are not terminated, as well as any terminating pods
// that have already been removed from config. Pods that are terminating
// will be added to possiblyRunningPods, to prevent overly aggressive
// cleanup of pod cgroups.
runningPods := make(map[types.UID]sets.Empty)
possiblyRunningPods := make(map[types.UID]sets.Empty)
restartablePods := make(map[types.UID]sets.Empty)
// Categorize pods in podWorkers (removed pods not in kl.podManager)
// runningPods: pods in podWorkers in SyncPod state
// possiblyRunningPods: pods in podWorkers in SyncPod state and pods in TerminatingPod state
// restartablePods: pods in TerminatedAndRecreatedPod state in podWorkers
for uid, sync := range workingPods {
switch sync {
case SyncPod:
runningPods[uid] = struct{}{}
possiblyRunningPods[uid] = struct{}{}
case TerminatingPod:
possiblyRunningPods[uid] = struct{}{}
case TerminatedAndRecreatedPod:
restartablePods[uid] = struct{}{}
}
}
// Stop probing pods that are not running
klog.V(3).InfoS("Clean up probes for terminated pods")
// If pod UID in kl.probeManager.workers is not in possiblyRunningPods,
// send a signal to worker.stopCh to stop and delete periodic probes
kl.probeManager.CleanupPods(possiblyRunningPods)
// Terminate any pods that are observed in the runtime but not
// present in the list of known running pods from config.
// Get the running pod list from the runtime cache
runningRuntimePods, err := kl.runtimeCache.GetPods()
if err != nil {
klog.ErrorS(err, "Error listing containers")
return err
}
for _, runningPod := range runningRuntimePods {
switch workerState, ok := workingPods[runningPod.ID]; {
// If the pod worker is already in charge of this pod and in SyncPod state,
// or in charge of this pod and in TerminatingPod state, do nothing
case ok && workerState == SyncPod, ok && workerState == TerminatingPod:
continue
default:
// If the pod isn't in the set that should be running and isn't already terminating, terminate now.
// This termination is aggressive because all known pods should already be in a known state
// (i.e., a removed static pod should already be terminating), so these are pods that were
// orphaned due to kubelet restart or bugs. Since housekeeping blocks other config changes,
// we know that another pod wasn't started in the background so we are safe to terminate the
// unknown pods.
// If the pod is not in kl.podManager (API server), execute kl.podWorkers.UpdatePod
// (UpdateType: kubetypes.SyncPodKill) to let podWorker execute Terminating --> Terminated
if _, ok := allPodsByUID[runningPod.ID]; !ok {
klog.V(3).InfoS("Clean up orphaned pod containers", "podUID", runningPod.ID)
one := int64(1)
kl.podWorkers.UpdatePod(UpdatePodOptions{
UpdateType: kubetypes.SyncPodKill,
RunningPod: runningPod,
KillPodOptions: &KillPodOptions{
PodTerminationGracePeriodSecondsOverride: &one,
},
})
}
}
}5 Summary
The analysis identifies two instances of the error ‘an error occurred when trying to find the container. The first occurrence happens during the removal of the container, where the container was already removed in a prior step, causing the second attempt to fail since the container no longer exists. The second instance of this error takes place when the housekeeping process attempts to stop a container. The root cause of the second error is traced back to inconsistencies in the runtime cache, where a pod that has already stopped is still present in the cache.

