Source Code Analysis of Node Lifecycle Controller Manager
The Node Lifecycle Controller Manager decides whether to evict pods on a node or set taints based on node leases and node status update times. It also sets the node ready condition to “unknown” when needed. Additionally, it adjusts the node eviction rate based on the overall cluster state and the number of unready nodes in a zone, enabling it to add taints or execute pod evictions as necessary.
This analysis is based on Kubernetes version 1.18.6.
1 Startup Process
The controller manager creates a goroutine to start the Node Lifecycle Controller. The start function for the Node Lifecycle Controller is startNodeLifecycleController, located in cmd\kube-controller-manager\app\core.go.
func startNodeLifecycleController(ctx ControllerContext) (http.Handler, bool, error) {
lifecycleController, err := lifecyclecontroller.NewNodeLifecycleController(
ctx.InformerFactory.Coordination().V1().Leases(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.InformerFactory.Core().V1().Nodes(),
ctx.InformerFactory.Apps().V1().DaemonSets(),
// The node lifecycle controller uses an existing cluster role from node-controller.
ctx.ClientBuilder.ClientOrDie("node-controller"),
ctx.ComponentConfig.KubeCloudShared.NodeMonitorPeriod.Duration, // Default is 5s (depends on --node-monitor-period)
ctx.ComponentConfig.NodeLifecycleController.NodeStartupGracePeriod.Duration, // Default is 1min (depends on --node-startup-grace-period)
ctx.ComponentConfig.NodeLifecycleController.NodeMonitorGracePeriod.Duration, // Default is 40s (depends on --node-monitor-grace-period)
ctx.ComponentConfig.NodeLifecycleController.PodEvictionTimeout.Duration, // Default is 5min (depends on --pod-eviction-timeout)
ctx.ComponentConfig.NodeLifecycleController.NodeEvictionRate, // Default is 0.1 (depends on --node-eviction-rate)
ctx.ComponentConfig.NodeLifecycleController.SecondaryNodeEvictionRate, // Default is 0.01 (depends on --secondary-node-eviction-rate)
ctx.ComponentConfig.NodeLifecycleController.LargeClusterSizeThreshold, // Default is 50 (depends on --large-cluster-size-threshold)
ctx.ComponentConfig.NodeLifecycleController.UnhealthyZoneThreshold, // Default is 0.55 (depends on --unhealthy-zone-threshold)
ctx.ComponentConfig.NodeLifecycleController.EnableTaintManager, // Default is true (depends on --enable-taint-manager)
)
if err != nil {
return nil, true, err
}
go lifecycleController.Run(ctx.Stop)
return nil, true, nil
}2 Relevant Command-Line Parameters
The Node Lifecycle Controller Manager has several command-line parameters:
--enable-taint-manager(Beta Feature):- If set to true, it enables NoExecute Taints and evicts all non-tolerating Pods running on nodes tainted with such Taints. (default is true)
- Enabling this feature allows the manager to add Taints when nodes are unready and remove them when nodes become ready, as well as execute pod evictions for nodes that can’t tolerate NoExecute Taints.
--large-cluster-size-threshold(int32):- The number of nodes at which the Node Controller treats the cluster as “large” for eviction logic purposes.
- The
--secondary-node-eviction-rateis implicitly set to 0 for clusters of this size or smaller. (default is 50) - This parameter determines how many nodes are considered “large” in a cluster.
--node-eviction-rate(float32):- The number of nodes per second on which pods are deleted in case of node failure when a zone is healthy (see
--unhealthy-zone-thresholdfor the definition of healthy/unhealthy). - In a healthy zone (where the number of unhealthy nodes is below
--unhealthy-zone-threshold), this parameter controls the node eviction rate. (default is 0.1)
- The number of nodes per second on which pods are deleted in case of node failure when a zone is healthy (see
--node-monitor-grace-period(duration):- The amount of time for which a running node is allowed to be unresponsive before it’s marked as unhealthy.
- It should be N times greater than the kubelet’s
nodeStatusUpdateFrequency, where N represents the number of retries allowed for the kubelet to post node status. (default is 40s)
--node-startup-grace-period(duration):- The amount of time for which a starting node is allowed to be unresponsive before it’s marked as unhealthy. (default is 1m0s)
--pod-eviction-timeout(duration):- The grace period for deleting pods on failed nodes. (default is 5m0s)
- This timeout is effective only when the Taint Manager is not enabled.
--secondary-node-eviction-rate(float32):- The number of nodes per second on which pods are deleted in case of node failure when a zone is unhealthy (see
--unhealthy-zone-thresholdfor the definition of healthy/unhealthy). - This parameter is implicitly set to 0 if the cluster size is smaller than
--large-cluster-size-threshold. (default is 0.01)
- The number of nodes per second on which pods are deleted in case of node failure when a zone is unhealthy (see
--unhealthy-zone-threshold(float32):- The fraction of nodes in a zone that need to be “Not Ready” (minimum 3 nodes) for the zone to be treated as unhealthy. (default is 0.55)
- This parameter determines what proportion of unhealthy nodes is considered unhealthy for a zone.
--node-monitor-period(duration):- The period for syncing NodeStatus in NodeController. (default is 5s)
- This controls how often the Node Lifecycle Controller actively scans all nodes.
3 Data Structures
Here are some important data structures used by the Node Lifecycle Controller:
type Controller struct {
..........
// A map storing known nodes that are periodically actively scanned. It is used to compare newly added nodes and deleted nodes.
knownNodeSet map[string]*v1.Node
// A per-node map storing the last observed health along with the local time when it was observed.
// Periodically scanned nodes and their statuses are saved here.
nodeHealthMap *nodeHealthMap
// Lock to protect zonePodEvictor and zoneNoExecuteTainter.
// TODO(#83954): API calls shouldn't be executed under the lock.
evictorLock sync.Mutex
// Workers responsible for evicting pods from unresponsive nodes.
// Used when Taint Manager is not enabled. Stores the status of whether pods on nodes have been evicted or are to be evicted.
nodeEvictionMap *nodeEvictionMap
// Used when Taint Manager is not enabled. Lists nodes in zones that require pod eviction.
zonePodEvictor map[string]*scheduler.RateLimitedTimedQueue
// Workers responsible for tainting nodes.
// Used when Taint Manager is enabled. Stores the list of unready nodes that need taint updates. It uses a token bucket queue.
zoneNoExecuteTainter map[string]*scheduler.RateLimitedTimedQueue
// Stores the health status of each zone, including stateFullDisruption, statePartialDisruption, stateNormal, and stateInitial.
zoneStates map[string]ZoneState
// Value controlling the Controller's node health monitoring period, i.e., how often the Controller checks node health signals posted by kubelet. This value should be lower than nodeMonitorGracePeriod.
// TODO: Change node health monitor to watch based.
// The period for actively scanning all nodes.
nodeMonitorPeriod time.Duration
// Grace period for nodes that have just been created, e.g., during cluster bootstrap or node creation. During this period, nodes are considered unready.
// Timeout for considering a newly registered node as unready.
nodeStartupGracePeriod time.Duration
// The Controller does not proactively sync node health but monitors node health signals updated by kubelet. These signals include NodeStatus and NodeLease. If no updates are received for this duration, the Controller starts posting "NodeReady==ConditionUnknown". The duration before which the Controller starts evicting pods is controlled via the 'pod-eviction-timeout' flag.
// Note: When changing this constant, be cautious, as it must work with nodeStatusUpdateFrequency in kubelet and renewInterval in the NodeLease controller. The node health signal update frequency is the minimum of the two.
// There are constraints to consider:
// 1. nodeMonitorGracePeriod must be N times greater than the node health signal update frequency, where N represents the number of retries allowed for kubelet to post node status/lease. It is pointless to make nodeMonitorGracePeriod less than the node health signal update frequency since fresh values from the kubelet are only available at intervals determined by the node health signal update frequency. The constant must also be less than podEvictionTimeout.
// 2. nodeMonitorGracePeriod cannot be too large for the sake of user experience, as a larger value would delay the visibility of up-to-date node health.
// The duration of node health signal unresponsiveness before considering the node as unhealthy.
nodeMonitorGracePeriod time.Duration
// The duration for pod eviction after a node becomes unhealthy.
// The duration before pods are removed from an unhealthy node. This is effective only when Taint Manager is not enabled.
podEvictionTimeout time.Duration
// The number of nodes per second for eviction in a normal zone (where the number of unhealthy nodes is below unhealthyZoneThreshold).
// Controls the node eviction rate when the zone is healthy.
evictionLimiterQPS float32
// The number of nodes per second for eviction in an unhealthy zone (where the number of unhealthy nodes is above unhealthyZoneThreshold).
// Controls the node eviction rate when the zone is unhealthy.
secondaryEvictionLimiterQPS float32
// The number of nodes that are considered part of a "large" cluster. If the cluster size is smaller than this threshold, the secondary eviction rate is set to 0.
largeClusterThreshold int32
// The threshold for the proportion of unhealthy nodes that, when exceeded, considers a zone as "partial disruption."
unhealthyZoneThreshold float32
// If set to true, the Controller starts the TaintManager, which evicts Pods from tainted nodes if they cannot tolerate the Taints.
runTaintManager bool
// An unsynchronized workqueue.
nodeUpdateQueue workqueue.Interface
// A workqueue with rate limiting and exponential back-off strategy.
podUpdateQueue workqueue.RateLimitingInterface
}4 Queues
The queues used here are:
workqueue
- nodeUpdateQueue
- podUpdateQueue
RateLimitedTimedQueue
- zonePodEvictor
- zoneNoExecuteTainter
We will delve into these queues in more detail later.
5 Controller Initialization
Initialization involves the following steps:
- Initializing data structures and setting various field values.
- Setting up the handler to listen for pod events and adding pod items to the podUpdateQueue (if taint manager is enabled, taint manager-related handlers are also added to put pods into the taint manager’s podUpdateQueue).
- Adding new indexers to the pod shared informer to find all pods on nodes.
- Initializing an event recorder for sending events to the API server.
- If taint manager is enabled, initializing the taint manager and adding a handler for node events (handled by the taint manager).
- Adding a handler for node events to put nodes into the nodeUpdateQueue.
// NewNodeLifecycleController returns a new taint controller.
func NewNodeLifecycleController(
leaseInformer coordinformers.LeaseInformer,
podInformer coreinformers.PodInformer,
nodeInformer coreinformers.NodeInformer,
daemonSetInformer appsv1informers.DaemonSetInformer,
kubeClient clientset.Interface,
nodeMonitorPeriod time.Duration,
nodeStartupGracePeriod time.Duration,
nodeMonitorGracePeriod time.Duration,
podEvictionTimeout time.Duration,
evictionLimiterQPS float32,
secondaryEvictionLimiterQPS float32,
largeClusterThreshold int32,
unhealthyZoneThreshold float32,
runTaintManager bool,
) (*Controller, error) {
if kubeClient == nil {
klog.Fatalf("kubeClient is nil when starting Controller")
}
// Initialize event recorder.
eventBroadcaster := record.NewBroadcaster()
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "node-controller"})
eventBroadcaster.StartLogging(klog.Infof)
klog.Infof("Sending events to API server.")
eventBroadcaster.StartRecordingToSink(
&v1core.EventSinkImpl{
Interface: v1core.New(kubeClient.CoreV1().RESTClient()).Events(""),
})
if kubeClient.CoreV1().RESTClient().GetRateLimiter() != nil {
ratelimiter.RegisterMetricAndTrackRateLimiterUsage("node_lifecycle_controller", kubeClient.CoreV1().RESTClient().GetRateLimiter())
}
nc := &Controller{
kubeClient: kubeClient,
now: metav1.Now,
knownNodeSet: make(map[string]*v1.Node),
nodeHealthMap: newNodeHealthMap(), // Store health data for discovered nodes
nodeEvictionMap: newNodeEvictionMap(),
recorder: recorder,
nodeMonitorPeriod: nodeMonitorPeriod, // Default is 5s
nodeStartupGracePeriod: nodeStartupGracePeriod, // Default is one minute
nodeMonitorGracePeriod: nodeMonitorGracePeriod, // Default is 40s
zonePodEvictor: make(map[string]*scheduler.RateLimitedTimedQueue), // For zones without taints management, list of nodes in need of pod eviction with rate-limited token bucket queue
zoneNoExecuteTainter: make(map[string]*scheduler.RateLimitedTimedQueue), // For taints management, list of unhealthy nodes in need of taint update with rate-limited token bucket queue
nodesToRetry: sync.Map{},
zoneStates: make(map[string]ZoneState), // Store state for each zone
podEvictionTimeout: podEvictionTimeout, // Default is 5 minutes
evictionLimiterQPS: evictionLimiterQPS, // Default is 0.1
secondaryEvictionLimiterQPS: secondaryEvictionLimiterQPS, // Default is 0.01
largeClusterThreshold: largeClusterThreshold, // Default is 50
unhealthyZoneThreshold: unhealthyZoneThreshold, // Default is 0.55
runTaintManager: runTaintManager, // Default is true
nodeUpdateQueue: workqueue.NewNamed("node_lifecycle_controller"), // When a node changes, it is added to the queue for taint addition or update
podUpdateQueue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "node_lifecycle_controller_pods"), // Queue with rate limiting for pod changes, used for pod eviction or changing pod condition to ready=false
}
nc.enterPartialDisruptionFunc = nc.ReducedQPSFunc
nc.enterFullDisruptionFunc = nc.HealthyQPSFunc
nc.computeZoneStateFunc = nc.ComputeZoneState
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
pod := obj.(*v1.Pod)
nc.podUpdated(nil, pod)
if nc.taintManager != nil {
nc.taintManager.PodUpdated(nil, pod)
}
},
UpdateFunc: func(prev, obj interface{}) {
prevPod := prev.(*v1.Pod)
newPod := obj.(*v1.Pod)
nc.podUpdated(prevPod, newPod)
if nc.taintManager != nil {
nc.taintManager.PodUpdated(prevPod, newPod)
}
},
DeleteFunc: func(obj interface{}) {
pod, isPod := obj.(*v1.Pod)
// We can get DeletedFinalStateUnknown instead of *v1.Pod here and we need to handle that correctly.
if !isPod {
deletedState, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
klog.Errorf("Received unexpected object: %v", obj)
return
}
pod, ok = deletedState.Obj.(*v1.Pod)
if !ok {
klog.Errorf("DeletedFinalStateUnknown contained non-Pod object: %v", deletedState.Obj)
return
}
}
nc.podUpdated(pod, nil)
if nc.taintManager != nil {
nc.taintManager.PodUpdated(pod, nil)
}
},
})
nc.podInformerSynced = podInformer.Informer().HasSynced
// Add new indexers to the shared informer.
podInformer.Informer().AddIndexers(cache.Indexers{
nodeNameKeyIndex: func(obj interface{}) ([]string, error) {
pod, ok := obj.(*v1.Pod)
if !ok {
return []string{}, nil
}
if len(pod.Spec.NodeName) == 0 {
return []string{}, nil
}
return []string{pod.Spec.NodeName}, nil
},
})
podIndexer := podInformer.Informer().GetIndexer()
nc.getPodsAssignedToNode = func(nodeName string) ([]*v1.Pod, error) {
objs, err := podIndexer.ByIndex(nodeNameKeyIndex, nodeName)
if err != nil {
return nil, err
}
pods := make([]*v1.Pod, 0, len(objs))
for _, obj := range objs {
pod, ok := obj.(*v1.Pod)
if !ok {
continue
}
pods = append(pods, pod)
}
return pods, nil
}
nc.podLister = podInformer.Lister()
if nc.runTaintManager {
podGetter := func(name, namespace string) (*v1.Pod, error) { return nc.podLister.Pods(namespace).Get(name) }
nodeLister := nodeInformer.Lister()
nodeGetter := func(name string) (*v1.Node, error) { return nodeLister.Get(name) }
nc.taintManager = scheduler.NewNoExecuteTaintManager(kubeClient, podGetter, nodeGetter, nc.getPodsAssignedToNode)
nodeInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: nodeutil.CreateAddNodeHandler(func(node *v1.Node) error {
nc.taintManager.NodeUpdated(nil, node)
return nil
}),
UpdateFunc: nodeutil.CreateUpdateNodeHandler(func(oldNode, newNode *v1.Node) error {
nc.taintManager.NodeUpdated(oldNode, newNode)
return nil
}),
DeleteFunc: nodeutil.CreateDeleteNodeHandler(func(node *v1.Node) error {
nc.taintManager.NodeUpdated(node, nil)
return nil
}),
})
}
klog.Infof("Controller will reconcile labels.")
nodeInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: nodeutil.CreateAddNodeHandler(func(node *v1.Node) error {
nc.nodeUpdateQueue.Add(node.Name)
nc.nodeEvictionMap.registerNode(node.Name)
return nil
}),
UpdateFunc: nodeutil.CreateUpdateNodeHandler(func(_, newNode *v1.Node) error {
nc.nodeUpdateQueue.Add(newNode.Name)
return nil
}),
DeleteFunc: nodeutil.CreateDeleteNodeHandler(func(node *v1.Node) error {
nc.nodesToRetry.Delete(node.Name)
nc.nodeEvictionMap.unregisterNode(node.Name)
return nil
}),
})
nc.leaseLister = leaseInformer.Lister()
nc.leaseInformerSynced = leaseInformer.Informer().HasSynced
nc.nodeLister = nodeInformer.Lister()
nc.nodeInformerSynced = nodeInformer.Informer().HasSynced
nc.daemonSetStore = daemonSetInformer.Lister()
nc.daemonSetInformerSynced = daemonSetInformer.Informer().HasSynced
return nc, nil
}6 Running
First, it waits for leaseInformer, nodeInformer, podInformerSynced, and daemonSetInformerSynced to complete syncing.
If the taint manager is enabled, a goroutine continuously runs nc.taintManager.Run(stopCh) to run the taint manager, which is explained in the next section.
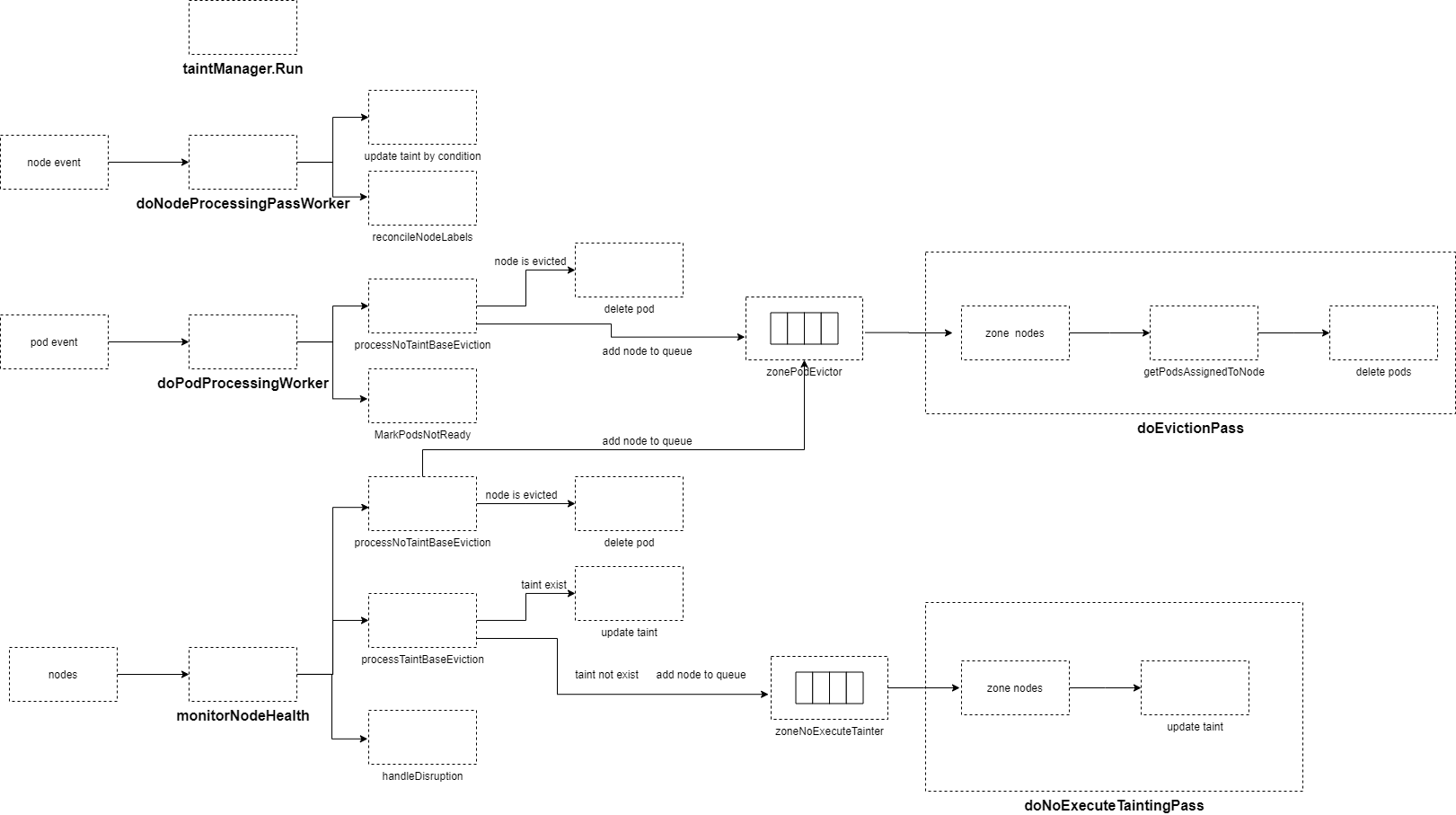
It starts 8 goroutines that execute nc.doNodeProcessingPassWorker every second to consume the nodeUpdateQueue, updating node NoSchedule taints and labels.
It starts 4 goroutines that execute doPodProcessingWorker every second to consume the podUpdateQueue. When a pod’s node is unready, it sets the pod’s condition to Ready=False. If the taint manager is not enabled and the node remains unready for longer than pod-evicted-timeout, the node is added to zonePodEvictor.
If the taint manager is enabled, it starts a goroutine that executes doNoExecuteTaintingPass every 100 milliseconds to consume the zoneNoExecuteTainter queue. It updates node NoExecute taints based on the node’s ready condition.
If the taint manager is not enabled, it starts a goroutine that executes doEvictionPass every 100 milliseconds to consume the zonePodEvictor queue. This removes all pods from nodes and marks nodes as “evicted” in the nodeEvictionMap.
It starts a goroutine every --node-monitor-period time to execute monitorNodeHealth, which periodically checks the health status of all nodes. If the kubelet hasn’t updated status.condition ready.lastHeartbeatTime or the lease’s renew time exceeds nodeMonitorGracePeriod, it updates the node’s status to “Unknown” and takes action based on the number of unready nodes in each zone, either evicting pods or adding taints to nodes.
// Run starts an asynchronous loop that monitors the status of cluster nodes.
func (nc *Controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
klog.Infof("Starting node controller")
defer klog.Infof("Shutting down node controller")
// Wait for informer caches to sync
if !cache.WaitForNamedCacheSync("taint", stopCh, nc.leaseInformerSynced, nc.nodeInformerSynced, nc.podInformerSynced, nc.daemonSetInformerSynced) {
return
}
// Start the taint manager if enabled
if nc.runTaintManager {
go nc.taintManager.Run(stopCh)
}
// Clean up node update and pod update queues when done
defer nc.nodeUpdateQueue.ShutDown()
defer nc.podUpdateQueue.ShutDown()
// Start workers to reconcile labels and/or update NoSchedule taint for nodes
for i := 0; i < scheduler.UpdateWorkerSize; i++ {
// Each worker retrieves items from the queue and processes them. Thanks to "workqueue," each item is flagged when it's retrieved from the queue, ensuring that no more than one worker handles the same item and no events are missed.
go wait.Until(nc.doNodeProcessingPassWorker, time.Second, stopCh)
}
for i := 0; i < podUpdateWorkerSize; i++ {
go wait.Until(nc.doPodProcessingWorker, time.Second, stopCh)
}
if nc.runTaintManager {
// Handle taint-based evictions: We rate limit adding taints because we don't want dedicated logic in TaintManager for NC-originated taints, and we normally don't rate limit evictions caused by taints.
go wait.Until(nc.doNoExecuteTaintingPass, scheduler.NodeEvictionPeriod, stopCh)
} else {
// Manage eviction of nodes: When we delete pods from a node, if the node was not empty at the time, we queue an eviction watcher. If we encounter an error, we retry the deletion.
go wait.Until(nc.doEvictionPass, scheduler.NodeEvictionPeriod, stopCh)
}
// Incorporate the results of node health signals pushed from kubelet to the master
go wait.Until(func() {
if err := nc.monitorNodeHealth(); err != nil {
klog.Errorf("Error monitoring node health: %v", err)
}
}, nc.nodeMonitorPeriod, stopCh)
<-stopCh
}6.1 doNodeProcessingPassWorker
The doNodeProcessingPassWorker function is responsible for processing updates and additions of nodes in the cluster. It works as follows:
- Nodes’ updates and additions are added to the
nodeUpdateQueue. - The worker function retrieves a node from the
nodeUpdateQueue. - Based on the conditions in the node’s status, different actions are taken regarding taints and node labels.
- The function executes
doNoScheduleTaintingPassbased on the node’s status conditions, which involves setting taints:- If there is a
readycondition innode.status.Conditions, and itscondition.statusisfalse, it sets a taint with the keynode.kubernetes.io/not-readyandEffectasNoSchedule. If thecondition.statusisunknown, it sets a taint with the keynode.kubernetes.io/unreachableandEffectasNoSchedule. - If there is a
MemoryPressurecondition, and itscondition.statusistrue, it sets a taint with the keynode.kubernetes.io/memory-pressureandEffectasNoSchedule. - Similarly, it checks for
DiskPressure,NetworkUnavailable, andPIDPressureconditions and sets corresponding taints. - If the
node.Spec.Unschedulablefield is set, it sets a taint with the keynode.kubernetes.io/unschedulableandEffectasNoSchedule.
- If there is a
- It executes
reconcileNodeLabelsto ensure consistency betweenbeta.kubernetes.io/osandkubernetes.io/oslabels and betweenbeta.kubernetes.io/archandkubernetes.io/archlabels. - Once the processing is done, the node is removed from the work queue.
In summary, this function processes node updates and additions, sets taints based on node conditions, and reconciles node labels.
6.2 doPodProcessingWorker
The doPodProcessingWorker function is responsible for processing newly created pods or pods with updated node bindings. It works as follows:
- Newly created pods or pods with updated node bindings are added to the
podUpdateQueue. - The worker function retrieves a pod from the
podUpdateQueue. - If the pod is bound to an “unready” node, it sets the pod’s
readycondition tofalseand updates thetransitionTimestamp. If the taint manager is not enabled, it evicts the pod and adds the node to thezonePodEvictor. - If the
ReadyConditionof the node is nottrue, it takes specific actions based on whether the taint manager is enabled or not:- If the taint manager is enabled, it processes taint-based evictions by adding or removing taints on the node based on the
ReadyCondition. - If the taint manager is not enabled, it processes non-taint-based evictions. If the
ReadyConditionisfalseorunknown, and theReadyTransitionTimestamphas passed thepodEvictionTimeout, it evicts the pods from the node. If theReadyConditionistrue, it cancels any ongoing pod eviction for the node.
- If the taint manager is enabled, it processes taint-based evictions by adding or removing taints on the node based on the
- If the node’s
ReadyConditionis nottrue, and if the taint manager is not enabled, it marks the pods on the node as not ready by setting theirreadycondition tofalseand updating theLastTransitionTimestamp. - The node and pod processing is completed, and the pod is removed from the work queue.
In summary, this function handles pod updates, checks node readiness, manages taints (if the taint manager is enabled), and evicts pods from unready nodes when necessary.
6.3 Executing Pod Eviction
In the context of the Taint Manager, the process of executing pod eviction involves two main steps: doNoExecuteTaintingPass for tainting nodes and doEvictionPass for actual pod eviction. Here’s a breakdown:
6.3.1 When Taint Manager is Enabled
1. doNoExecuteTaintingPass (Tainting Nodes)
- It operates as a token-bucket rate-limited queue.
- It iterates over the
zoneNoExecuteTainter, obtaining a queue of nodes within a zone, and processes one node at a time. - For each node:
- It retrieves node information from the cache.
- If the node’s ready condition is
false, it removes the existing “node.kubernetes.io/unreachable” taint and adds a “node.kubernetes.io/not-ready” taint with the Effect set to NoExecute. - If the node’s ready condition is
unknown, it removes the existing “node.kubernetes.io/not-ready” taint and adds a “node.kubernetes.io/unreachable” taint with the Effect set to NoExecute.
6.3.2 When Taint Manager is disabled
- It also operates as a token-bucket rate-limited queue.
- Nodes added to this queue are those with a
Readycondition status set tofalseand a duration of unavailability exceeding thepodEvictionTimeout. - For each node in the
zonePodEvictorqueue within a zone:- It retrieves the node’s UID.
- Retrieves all pods running on the node from the cache.
- Performs
DeletePods, which involves deleting all non-daemonset pods on the node while retaining daemonset pods.- Iterates through all pods and checks if they are bound to the node. If not, it skips that pod.
- Sets the pod’s
Status.ReasontoNodeLostandStatus.Messageto"Node %v which was running pod %v is unresponsive". Then, it updates the pod’s status. - If the pod has
DeletionGracePeriodSecondsset, it indicates that the pod has already been deleted, so it skips the pod. - Checks if the pod is a daemonset pod; if it is, it skips the pod.
- Deletes the pod.
- Sets the node’s status to “evicted” in
nodeEvictionMap.
6.3.3 Proactive Node Health Monitoring (monitorNodeHealth)
At intervals defined by nodeMonitorPeriod, the monitorNodeHealth function is executed to maintain node status and zone status. It also updates unresponsive nodes by setting their status to unknown and adjusts zone rates based on the cluster’s state.
6.3.4 Node Categorization and Initialization
The process begins by categorizing nodes into three groups: newly added nodes (add), deleted nodes (deleted), and nodes representing new zones (newZoneRepresentatives). This categorization is based on information obtained from the cache and is used to keep track of changes.
For newly discovered zones, initialization occurs. When the Taint Manager is enabled, it sets the rate at which nodes in the zone will have taints added (in the zoneNoExecuteTainter queue) to evictionLimiterQPS. When the Taint Manager is not enabled, it sets the rate at which nodes in the zone will be scheduled for pod eviction (in the zonePodEvictor queue) to evictionLimiterQPS. The zoneStates map is updated to set the zone’s status to stateInitial.
For newly discovered nodes, they are added to the knownNodeSet, and the zone’s status in zoneStates is set to stateInitial. If the node’s zone has not been initialized yet, it goes through the initialization process. If the Taint Manager is enabled, it marks the node as healthy by removing any unreachable and not-ready taints (if they exist) from the node and removes it from the zoneNoExecuteTainter queue if present. If the Taint Manager is not enabled, it initializes the nodeEvictionMap (used to track eviction progress for nodes), setting the node’s status to unmarked and removing it from the zonePodEvictor queue if present.
For deleted nodes, a “RemovingNode” event is sent, and they are removed from the knownNodeSet.
6.3.5 Handling Node Status
Timeout Duration
Nodes are assigned a timeout duration based on their Ready condition status. If the node’s Ready condition is empty, indicating a newly registered node, its timeout duration is set to nodeStartupGracePeriod. Otherwise, it is set to nodeMonitorGracePeriod.
Heartbeat Timestamps
Heartbeat timestamps, probeTimestamp and readyTransitionTimestamp, are updated based on the following rules:
- If the node was just registered, both timestamps are set to the node’s creation time.
- If the node is not found in the
nodeHealthMap, both timestamps are set to the current time. - If the node’s
Readycondition was not found in thenodeHealthMap, but it is found in the current status, both timestamps are set to the current time, and the status is updated accordingly. - If the node’s
Readycondition was found in thenodeHealthMap, and it is still present in the current status, and theLastHeartbeatTimeis different from the current time, theprobeTimestampis set to the current time, and the status is updated. - If the current lease exists, and its
RenewTimeis later than the one saved in thenodeHealthMapor the node is not found in thenodeHealthMap, theprobeTimestampis set to the current time, and the current lease is saved in thenodeHealthMap.
Attempting to Update Node Status
If the probeTimestamp plus the timeout duration is earlier than the current time, indicating that the status update has timed out, an update to the node is attempted.
Updating conditions for Ready, MemoryPressure, DiskPressure, and PIDPressure:
If the corresponding condition does not exist:
v1.NodeCondition{
Type: nodeConditionType, // One of the four condition types mentioned above
Status: v1.ConditionUnknown, // Unknown status
Reason: "NodeStatusNeverUpdated",
Message: "Kubelet never posted node status.",
LastHeartbeatTime: node.CreationTimestamp, // Node creation time
LastTransitionTime: nowTimestamp, // Current time
}If the corresponding condition exists:
currentCondition.Status = v1.ConditionUnknown
currentCondition.Reason = "NodeStatusUnknown"
currentCondition.Message = "Kubelet stopped posting node status."
currentCondition.LastTransitionTime = nowTimestampIf the node is different from the previous node after updating, an update to the node is executed successfully. Simultaneously, the status in nodeHealthMap is updated, with readyTransitionTimestamp changed to the current time, and the status changed to the current node status.
Handling Unready Nodes - Pod Eviction
The node’s current ReadyCondition is the condition of the node after attempting to update the node status. The node’s last discovered ReadyCondition is the condition before attempting to update the node status.
If the current ReadyCondition is not empty, the following operations are performed:
- Retrieve the list of pods on the node from the cache.
- If the Taint Manager is enabled, execute
processTaintBaseEvictionto manipulate the node’s taints based on the last discoveredReadyConditionof the node:- If the last discovered
ReadyConditionwasfalseand there is already a “node.kubernetes.io/unreachable” taint, remove that taint and add a “node.kubernetes.io/not-ready” taint. Otherwise, add the node to thezoneNoExecuteTainterqueue, awaiting taint addition. - If the last discovered
ReadyConditionwasunknownand there is already a “node.kubernetes.io/not-ready” taint, remove that taint and add a “node.kubernetes.io/unreachable” taint. Otherwise, add the node to thezoneNoExecuteTainterqueue, awaiting taint addition. - If the last discovered
ReadyConditionwastrue, remove the “node.kubernetes.io/not-ready” and “node.kubernetes.io/unreachable” taints (if they exist) and remove the node from thezoneNoExecuteTainterqueue if present.
- If the last discovered
- If the Taint Manager is not enabled, execute
processNoTaintBaseEviction:- If the last discovered
ReadyConditionwasfalseand thereadyTransitionTimestampinnodeHealthMapplus thepodEvictionTimeoutduration is in the past (indicating that theReadyConditionhas beenfalsefor at leastpodEvictionTimeout), executeevictPods. - If the last discovered
ReadyConditionwasunknownand thereadyTransitionTimestampinnodeHealthMapplus thepodEvictionTimeoutduration is in the past (indicating that theReadyConditionhas beenunknownfor at leastpodEvictionTimeout), executeevictPods. - If the last discovered
ReadyConditionwastrue, executecancelPodEviction:- Set the node’s status in
nodeEvictionMapto “unmarked.” - Remove the node from the
zonePodEvictorqueue.
- Set the node’s status in
evictPods:- If the node’s eviction status in
nodeEvictionMapis “evicted” (indicating that the node has already been evicted), delete all pods on the node. - Otherwise, set the status to “toBeEvicted,” and add the node to the
zonePodEvictorqueue, awaiting pod eviction.
- If the node’s eviction status in
- If the last discovered
Here’s a question:
Why use observedReadyCondition instead of currentReadyCondition when observedReadyCondition and currentReadyCondition might not always be the same?
For example, if a node goes down and currentReadyCondition becomes unknown, but observedReadyCondition is ready, there’s an obvious issue. In this cycle, no eviction or tainting will be done. In the next cycle, when both observedReadyCondition and currentReadyCondition are unknown, pod eviction or tainting will definitely occur.
It might be considered that if the nodeMonitorPeriod is very short, not immediately performing eviction or tainting isn’t a significant issue.
6.3.6 Handling Cluster Health States
Each zone has four states: stateInitial (just joined zone), stateFullDisruption (all nodes down), statePartialDisruption (percentage of nodes down exceeds unhealthyZoneThreshold), and stateNormal (all other cases).
allAreFullyDisrupted represents that currently, all zones are in the stateFullDisruption (all nodes down) state.
allWasFullyDisrupted being true represents that in the past, all zones were in the stateFullDisruption (all nodes down) state.
There are four possible cluster health states:
allAreFullyDisruptedistrue, andallWasFullyDisruptedistrue.allAreFullyDisruptedistrue, andallWasFullyDisruptedisfalse.allAreFullyDisruptedisfalse, andallWasFullyDisruptedistrue.allAreFullyDisruptedisfalse, andallWasFullyDisruptedisfalse.
Calculating the Current Cluster State
Iterate through all zones currently and for each zone, iterate through the ready conditions of all nodes to calculate the zone’s state. Based on the zone’s state, set the value of allAreFullyDisrupted.
If a zone is not in zoneStates, add it to zoneStates and set its state to stateInitial.
Calculating the Past Cluster State
Retrieve the saved zone list from zoneStates. If a zone is not in the current zone list, remove it from zoneStates. Set the value of allWasFullyDisrupted based on the zone states saved in zoneStates
Configuring How Many Nodes to Schedule for Tainting or Eviction per Second in a Zone
When
allAreFullyDisruptedisfalseandallWasFullyDisruptedistrue(indicating that zones were not entirely down previously, but now all zones are fully down):- Iterate through all nodes and set them to a normal state.
- If the taint manager is enabled, execute
markNodeAsReachable– remove the taints “node.kubernetes.io/not-ready” and “node.kubernetes.io/unreachable” if they exist on the node. Also, remove the node from thezoneNoExecuteTainterqueue if it’s present. - If the taint manager is not enabled, execute
cancelPodEviction– set the status innodeEvictionMapto “unmarked,” and remove the node from thezonePodEvictorqueue.
- If the taint manager is enabled, execute
- Iterate through all nodes and set them to a normal state.
Retrieve the saved zone list from
zoneStatesand configure how many nodes per second should be scheduled for tainting or eviction in each zone.- If the taint manager is enabled, set the rate for
zoneNoExecuteTainterto 0. - If the taint manager is not enabled, set the rate for
zonePodEvictorto 0.
- If the taint manager is enabled, set the rate for
Set the state of all zones in
zoneStatestostateFullDisruption.
Configuring How Many Nodes to Schedule for Tainting or Eviction per Second in a Zone
When allAreFullyDisrupted is true and allWasFullyDisrupted is false (indicating that all zones were fully down in the past, but currently, all zones are not fully down):
- Iterate through all nodes and update the
probeTimestampandreadyTransitionTimestampinnodeHealthMapto the current timestamp. - Iterate through
zoneStatesto reevaluate how many nodes should be scheduled per second for tainting or eviction in each zone:- When the zone’s status is
stateNormal, if the taint manager is enabled, set the rate forzoneNoExecuteTaintertoevictionLimiterQPS; otherwise, set the rate forzonePodEvictorto theevictionLimiterQPSrate. - When the zone’s status is
statePartialDisruption, if the taint manager is enabled, adjust the rate forzoneNoExecuteTainterbased on the number of nodes in the zone. If the number of nodes is greater thanlargeClusterThreshold, set thezoneNoExecuteTainterrate toSecondEvictionLimiterQPS; if it’s less than or equal tolargeClusterThreshold, set thezoneNoExecuteTainterrate to 0. If the taint manager is not enabled, adjust the rate forzonePodEvictorsimilarly based on the number of nodes. - When the zone’s status is
stateFullDisruption, if the taint manager is enabled, set the rate forzoneNoExecuteTaintertoevictionLimiterQPS; otherwise, set the rate forzonePodEvictorto theevictionLimiterQPSrate.
- When the zone’s status is
This doesn’t handle zones in the stateInitial status because in the next cycle, those zones will transition to a non-stateInitial status. The following section addresses this scenario.
Handling the Case When not all Zones Were Fully Disrupted
Apart from the two scenarios mentioned earlier, there is one more case to consider when allAreFullyDisrupted is false, and allWasFullyDisrupted is false, meaning not all zones in the cluster were fully down. In this case, zones may transition to different states, so the rates for each zone need to be reevaluated.
- Iterate through
zoneStatesand reevaluate the rates for each zone when the saved state and the new state are different, indicating a change in zone status:- When the zone’s status is
stateNormal, if the taint manager is enabled, set the rate forzoneNoExecuteTaintertoevictionLimiterQPS; otherwise, set the rate forzonePodEvictorto theevictionLimiterQPSrate. - When the zone’s status is
statePartialDisruption, if the taint manager is enabled, adjust the rate forzoneNoExecuteTainterbased on the number of nodes in the zone. If the number of nodes is greater thanlargeClusterThreshold, set thezoneNoExecuteTainterrate toSecondEvictionLimiterQPS; if it’s less than or equal tolargeClusterThreshold, set thezoneNoExecuteTainterrate to 0. If the taint manager is not enabled, adjust the rate forzonePodEvictorsimilarly based on the number of nodes. - When the zone’s status is
stateFullDisruption, if the taint manager is enabled, set the rate forzoneNoExecuteTaintertoevictionLimiterQPS; otherwise, set the rate forzonePodEvictorto theevictionLimiterQPSrate.
- When the zone’s status is
- Update the status in
zoneStatesto the new state.
In cases where allAreFullyDisrupted is true, and allWasFullyDisrupted is true, indicating that the cluster has consistently been in a fully disrupted state, there is no need to handle this because the zone status remains unchanged.
6.3.7 Summary
Queue rates will only be adjusted under the following circumstances:
- When all zones in the cluster are fully disrupted, the zone’s rate is set to 0.
- When the cluster is not fully disrupted, and the percentage of unready nodes in a zone exceeds the
unhealthyZoneThreshold, and the number of nodes in the zone is greater thanlargeClusterThreshold, the zone’s rate is set toSecondEvictionLimiterQPS.
In cases where not all zones in the cluster are fully disrupted but a specific zone experiences a full disruption, the zone’s rate remains at evictionLimiterQPS.

