practice of Karmada as cluster resource synchronization in disaster recovery systems
1 Karmada: What is it?
Karmada is a Kubernetes multi-cluster management system. It allows resources to be distributed across multiple clusters while maintaining the original way of using the API server. It offers features such as cross-cloud multi-cluster management, multi-policy multi-cluster scheduling, cross-cluster fault tolerance for applications, a global unified resource view, multi-cluster service discovery, and Federated Horizontal Pod Autoscaling (FederatedHPA) capabilities. Its design philosophy inherits from Cluster Federation v2 and is currently an open-source CNCF sandbox project. For more details, visit the official website at https://karmada.io/.
The karmada version used in this article is v1.6.2.
2 Background
Cluster disaster recovery scenario: one cluster serves as the production cluster providing services to the outside world, and another cluster serves as the standby cluster. When the production cluster experiences a failure, traffic is switched to the standby cluster.
To save costs, the standby cluster uses cloud provider serverless clusters, where the replicas of workloads that are not in use have a replica count of 0 (or no running pods), and the replica count is adjusted when workloads are enabled. Due to the use of cloud provider serverless services, some annotations need to be added to pods to modify some runtime configurations, and certain taints need to be tolerated.
3 Solution
3.1 Custom Solution
The requirements include:
- Scalability: The ability to add new Custom Resource Definitions (CRDs) without significant code changes.
- Support for resource whitelisting and blacklisting for resource filtering.
- Flexible configuration options for resource modification.
- Observability features to monitor the number of successfully and unsuccessfully synchronized resources.
Pros: Code control and customization, good for improving coding skills.
Cons: Reinventing the wheel, time-consuming.
3.2 Open Source Solution - Velero
Velero is a backup tool for cluster resources and data. During backup, data is stored in object storage, and during restoration, backups are downloaded from object storage and resources and data are restored.
Velero’s restore resource modifiers feature can be used to modify resources.
Pros: Simple and convenient to use.
Cons: Backup and restoration take time, with delays causing the cluster to not achieve near real-time status.
3.3 Open Source Solution - Karmada
ClusterPropagationPolicy and PropagationPolicy can distribute resources across multiple clusters, while ClusterOverridePolicy and OverridePolicy can override resources.
Blacklisting at the namespace level and API resource type level.
Pros: Feature-rich, can ensure near real-time resources between clusters.
Cons: Complex architecture, with some learning curve.
4 Final Choice: Karmada Solution
4.1 Reasons for Choosing Karmada
- Ensures near real-time resources between clusters, reducing differences between clusters as much as possible when switching traffic during cluster failures.
- No need to reinvent the wheel.
4.2 Transformation Costs
Karmada’s design architecture involves deploying Karmada components in a control plane cluster, including a separate API server, forming an independent Kubernetes cluster, similar to Kubernetes in Kubernetes.
To manage existing cluster resources using Karmada, resources need to be migrated to the Karmada control plane cluster. This is done using the karmadactl promote command. However, it only supports one resource at a time and doesn’t support batch migration. Migrating a large number of resources from existing clusters can be challenging.
Also, the original connection to the existing API server needs to be switched to the Karmada control plane cluster API server.
4.3 Reusing API Server
By using the existing cluster’s API server as the Karmada control plane cluster’s API server, resource migration is unnecessary, and there’s no need to switch API server addresses. This allows using Karmada capabilities without modifying the existing system.
Related Documentation: Can I install Karmada in a Kubernetes cluster and reuse the kube-apiserver as Karmada apiserver
4.4 Architecture
4.4.1 Architecture when Both Clusters Are Able to Communicate
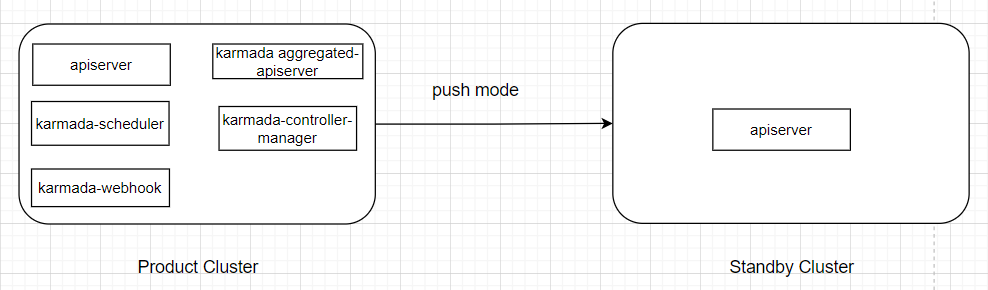
4.4.2 Architecture when Both Clusters Cannot Communicate
Using Proxy
Edit the cluster resource and add the proxy address to spec.proxyURL.
apiVersion: cluster.karmada.io/v1alpha1
kind: Cluster
metadata:
finalizers:
- karmada.io/cluster-controller
generation: 3
name: test-cluster
spec:
proxyURL: http://proxy-address # Add proxy address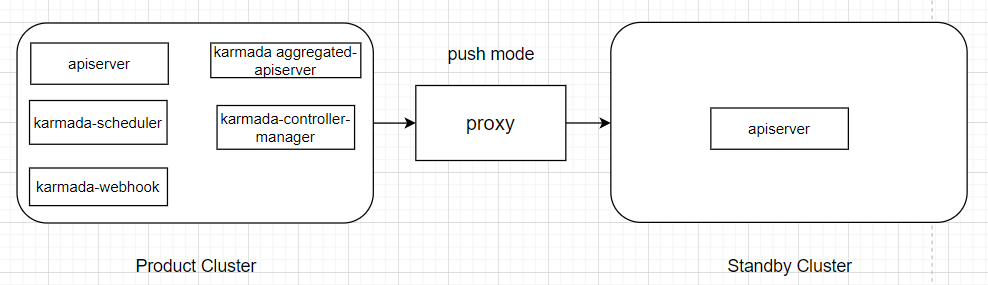
Deploying Karmada Controller Manager Independently (Only ensures resource synchronization functionality)
Deploy the Karmada-controller-manager separately in Cluster C, which can access both clusters.
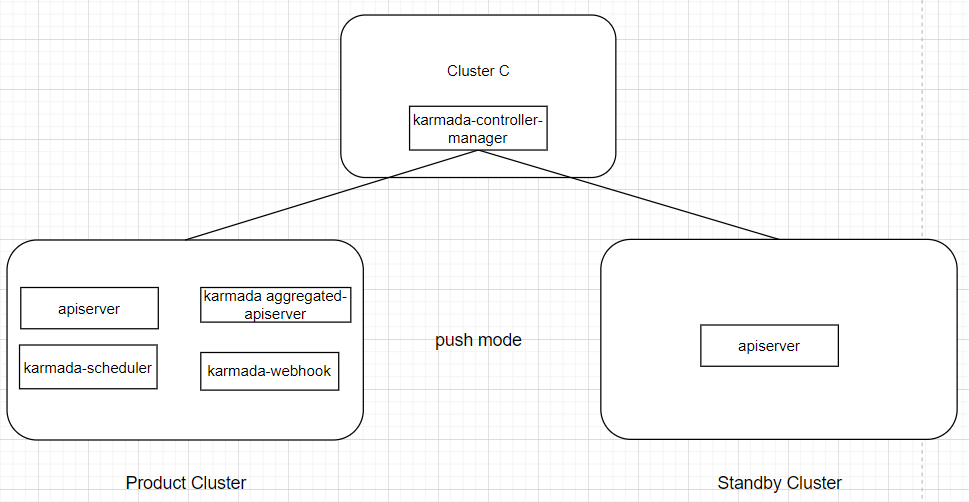
4.5 Blocking Cluster Component Resource Synchronization
Components in the cluster like monitoring, logging, ingress, etc., do not need to be synchronized, and resources under Kubernetes’ internal namespaces should not be synchronized.
Karmada-controller-manager can ignore resources in these namespaces using --skipped-propagating-namespaces.
--skipped-propagating-namespaces=velero,prometheus,default,kube-system,kube-public,kube-node-lease5 Troubleshooting Experience
5.1 Workload Names Longer Than 52 Characters Cannot Be Synchronized
Due to Karmada’s design, creating workloads in the standby cluster adds a label with key resourcebinding.karmada.io/name and value {workload name}-{workload kind}. The label’s key and value together should be no longer than 63 characters. For example, for deployment resources, the value has a suffix of “-deployment,” which is 11 characters long. Therefore, the deployment resource name must be 52 characters or less.
https://github.com/karmada-io/karmada/issues/3834
https://docs.google.com/document/d/1b-5EHUAQf8wIoCnerKTHiyiSIzsypqCNz0CWUzvUhnI/
5.2 Deleting PropagationPolicy and OverridePolicy Simultaneously Doesn’t Remove Workloads
In testing synchronization rules, deleting PropagationPolicy and OverridePolicy to remove synchronized resources in the standby cluster doesn’t remove the workloads. Instead, the workload properties become the same as those in the production cluster.
https://github.com/karmada-io/karmada/issues/3873
5.3 Product Cluster Workload Status Gets Modified by Karmada
Successfully synchronized workloads have their status modified by karmada-controller-manager in the product cluster. This leads to various issues, such as the removal of the status.capacity field in PVC, causing pod mounting failures.
The solution is to disable the bindingStatus controller in karmada-controller-manager.
--controllers=-bindingStatus,*https://github.com/karmada-io/karmada/issues/3907
5.4 Using overridePolicy’s plaintext Cannot Add Nonexistent Fields
Synchronized workloads in the standby cluster need some annotations added to spec.template.metadata.annotation. However, some workloads don’t have spec.template.metadata.annotation, causing synchronization failures.
https://github.com/karmada-io/karmada/issues/3923
6 Reference Configuration
My final configuration
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
- apiVersion: apps/v1
kind: StatefulSet
propagateDeps: true
placement:
clusterAffinity:
clusterNames:
- test
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterOverridePolicy
metadata:
name: workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
- apiVersion: apps/v1
kind: StatefulSet
overrideRules:
- overriders:
plaintext:
- path: /spec/replicas
operator: replace
value: 0
- path: /spec/template/spec/tolerations
operator: add
value:
- key: "eks.tke.cloud.tencent.com/eklet"
operator: "Exists"
effect: "NoSchedule"
- path: /spec/template/spec/schedulerName
operator: add
value: "tke-scheduler"
- path: /spec/template/spec/schedulerName
operator: replace
value: "tke-scheduler"
- path: /spec/template/metadata/annotations/AUTO_SCALE_EKS
operator: add
value: "true"
- path: /spec/template/metadata/annotations/eks.tke.cloud.tencent.com~1resolv-conf
operator: add
value: |
nameserver 10.10.248.248
nameserver 10.10.249.249
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterOverridePolicy
metadata:
name: pvc
spec:
resourceSelectors:
- apiVersion: v1
kind: PersistentVolumeClaim
overrideRules:
- overriders:
plaintext:
- path: /spec/volumeName
operator: remove
annotationsOverrider:
- operator: remove
value:
pv.kubernetes.io/bound-by-controller: "yes"
pv.kubernetes.io/bind-completed: "yes"
volume.kubernetes.io/selected-node: ""
pv.kubernetes.io/provisioned-by: ""
volume.kubernetes.io/storage-provisioner: ""
volume.beta.kubernetes.io/storage-provisioner: ""
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: network
spec:
resourceSelectors:
- apiVersion: v1
kind: Service
- apiVersion: networking.k8s.io/v1
kind: Ingress
- apiVersion: networking.k8s.io/v1
kind: IngressClass
propagateDeps: true
placement:
clusterAffinity:
clusterNames:
- test
