Taint Manager Source Code Analysis
The Taint Manager is triggered by pod and node events. It examines whether nodes bound to pods or nodes themselves have a “NoExecute” taint. If such taints are present, the Taint Manager proceeds to delete all pods on the affected node(s) or a specific pod.
In the previous article about the Node Lifecycle Controller, if the Taint Manager is enabled, it is initialized using NewNoExecuteTaintManager.
Within the Node Lifecycle Controller, handlers are defined for pod and node events. When the Taint Manager is enabled, these events are added to the nodeUpdateQueue and podUpdateQueue within the Taint Manager.
Additionally, a goroutine is launched in the Node Lifecycle Controller to execute taintManager.Run(stopCh).
The Kubernetes version used in this analysis is 1.18.6.
1 Initialization
NewNoExecuteTaintManager is defined in pkg\controller\nodelifecycle\scheduler\taint_manager.go.
nodeUpdateQueueandpodUpdateQueueare work queues.taintedNodesstores all nodes with “NoExecute” taints, andhandlePodUpdatequeries this list for nodes with “NoExecute” taints.taintEvictionQueueis aTimedWorkerQueuethat automatically executes tasks on a timed schedule. Further details will be explained later in the analysis.
// NewNoExecuteTaintManager creates a new NoExecuteTaintManager that will use passed clientset to
// communicate with the API server.
func NewNoExecuteTaintManager(c clientset.Interface, getPod GetPodFunc, getNode GetNodeFunc, getPodsAssignedToNode GetPodsByNodeNameFunc) *NoExecuteTaintManager {
eventBroadcaster := record.NewBroadcaster()
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "taint-controller"})
eventBroadcaster.StartLogging(klog.Infof)
if c != nil {
klog.V(0).Infof("Sending events to api server.")
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: c.CoreV1().Events("")})
} else {
klog.Fatalf("kubeClient is nil when starting NodeController")
}
tm := &NoExecuteTaintManager{
client: c,
recorder: recorder,
getPod: getPod,
getNode: getNode,
getPodsAssignedToNode: getPodsAssignedToNode,
taintedNodes: make(map[string][]v1.Taint),
nodeUpdateQueue: workqueue.NewNamed("noexec_taint_node"),
podUpdateQueue: workqueue.NewNamed("noexec_taint_pod"),
}
tm.taintEvictionQueue = CreateWorkerQueue(deletePodHandler(c, tm.emitPodDeletionEvent))
return tm
}Initialization taintEvictionQueue
func (tc *NoExecuteTaintManager) emitPodDeletionEvent(nsName types.NamespacedName) {
if tc.recorder == nil {
return
}
ref := &v1.ObjectReference{
Kind: "Pod",
Name: nsName.Name,
Namespace: nsName.Namespace,
}
tc.recorder.Eventf(ref, v1.EventTypeNormal, "TaintManagerEviction", "Marking for deletion Pod %s", nsName.String())
}
func deletePodHandler(c clientset.Interface, emitEventFunc func(types.NamespacedName)) func(args *WorkArgs) error {
return func(args *WorkArgs) error {
ns := args.NamespacedName.Namespace
name := args.NamespacedName.Name
klog.V(0).Infof("NoExecuteTaintManager is deleting Pod: %v", args.NamespacedName.String())
if emitEventFunc != nil {
emitEventFunc(args.NamespacedName)
}
var err error
for i := 0; i < retries; i++ {
err = c.CoreV1().Pods(ns).Delete(context.TODO(), name, metav1.DeleteOptions{})
if err == nil {
break
}
time.Sleep(10 * time.Millisecond)
}
return err
}
}
// CreateWorkerQueue creates a new TimedWorkerQueue for workers that will execute
// given function `f`.
func CreateWorkerQueue(f func(args *WorkArgs) error) *TimedWorkerQueue {
return &TimedWorkerQueue{
workers: make(map[string]*TimedWorker),
workFunc: f,
}
}2 Data Structures
NoExecuteTaintManager
// NoExecuteTaintManager listens to Taint/Toleration changes and is responsible for removing Pods
// from Nodes tainted with NoExecute Taints.
type NoExecuteTaintManager struct {
client clientset.Interface
recorder record.EventRecorder
getPod GetPodFunc // Function to retrieve pods from the informer
getNode GetNodeFunc // Function to retrieve nodes from the informer
getPodsAssignedToNode GetPodsByNodeNameFunc // Function to get pods assigned to a node from the informer
taintEvictionQueue *TimedWorkerQueue // TimedWorkerQueue type
taintedNodesLock sync.Mutex
taintedNodes map[string][]v1.Taint // Maps node names to their associated NoExecute taints
nodeUpdateChannels []chan nodeUpdateItem // Channels for node updates from nodeUpdateQueue
podUpdateChannels []chan podUpdateItem // Channels for pod updates from podUpdateQueue
nodeUpdateQueue workqueue.Interface // Node update work queue
podUpdateQueue workqueue.Interface // Pod update work queue
}The taintEvictionQueue is of type TimedWorkerQueue. The TimedWorkerQueue is defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go. It contains information such as the creation time of WorkArgs, the time it should be executed, a timer, and the function to execute when it expires.
// TimedWorkerQueue keeps a set of TimedWorkers that are still waiting for execution.
type TimedWorkerQueue struct {
sync.Mutex
// Map of workers keyed by string returned by 'KeyFromWorkArgs' from the given worker.
workers map[string]*TimedWorker
// Function to be executed when work item expires.
workFunc func(args *WorkArgs) error
}
// TimedWorker is responsible for executing a function no earlier than the FireAt time.
type TimedWorker struct {
WorkItem *WorkArgs
CreatedAt time.Time
FireAt time.Time
Timer *time.Timer
}
// WorkArgs keeps arguments that will be passed to the function executed by the worker.
type WorkArgs struct {
NamespacedName types.NamespacedName
}The NamespacedName structure is defined in staging\src\k8s.io\apimachinery\pkg\types\namespacedname.go.
// NamespacedName comprises a resource name, with a mandatory namespace,
// rendered as "<namespace>/<name>". Being a type captures intent and
// helps make sure that UIDs, namespaced names and non-namespaced names
// do not get conflated in code. For most use cases, namespace and name
// will already have been format validated at the API entry point, so we
// don't do that here. Where that's not the case (e.g. in testing),
// consider using NamespacedNameOrDie() in testing.go in this package.
type NamespacedName struct {
Namespace string
Name string
}3 Running
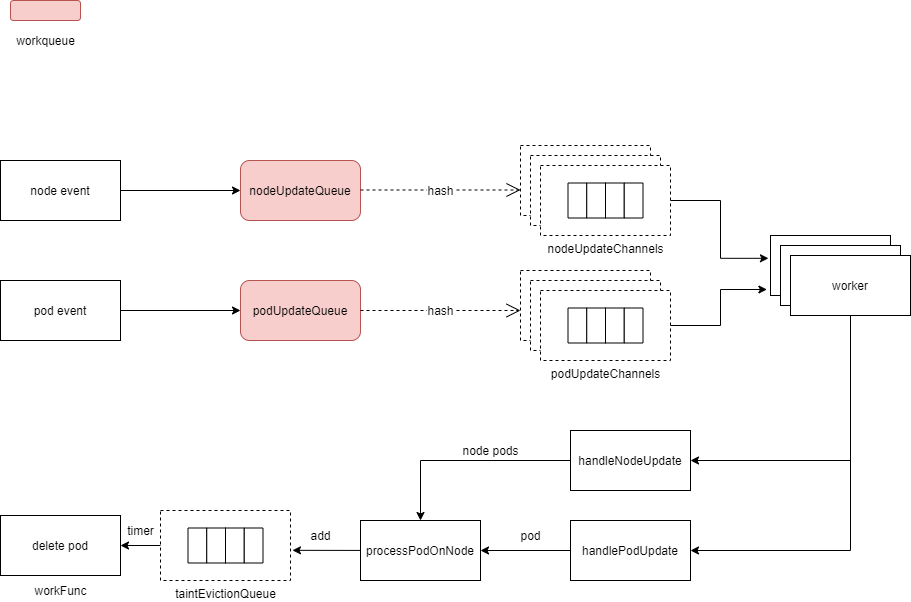
- Create
UpdateWorkerSizechannels of typenodeUpdateItemwith a buffer size of 10 each, and store them in thenodeUpdateChannelscollection. Similarly, createUpdateWorkerSizechannels of typepodUpdateItemwith a buffer size of 10 each, and store them in thepodUpdateChannelscollection. Here,UpdateWorkerSizeis set to 8,NodeUpdateChannelSizeis 10, andpodUpdateChannelSizeis 1. - Start a goroutine that retrieves a
nodeUpdateItemfromnodeUpdateQueueand puts it into one of thenodeUpdateChannels. The allocation algorithm is based on hashing the node name and taking the modulus with respect toUpdateWorkerSizeto determine the channel index. - Start a goroutine that retrieves a
podUpdateItemfrompodUpdateQueueand puts it into one of thepodUpdateChannels. The allocation algorithm is the same as for nodes. - Start
UpdateWorkerSizegoroutines, each executing the worker method, which contains the logic for processing events.
// Run starts NoExecuteTaintManager which will run in loop until `stopCh` is closed.
func (tc *NoExecuteTaintManager) Run(stopCh <-chan struct{}) {
klog.V(0).Infof("Starting NoExecuteTaintManager")
for i := 0; i < UpdateWorkerSize; i++ {
tc.nodeUpdateChannels = append(tc.nodeUpdateChannels, make(chan nodeUpdateItem, NodeUpdateChannelSize))
tc.podUpdateChannels = append(tc.podUpdateChannels, make(chan podUpdateItem, podUpdateChannelSize))
}
// Functions that are responsible for taking work items out of the workqueues and putting them
// into channels.
go func(stopCh <-chan struct{}) {
for {
item, shutdown := tc.nodeUpdateQueue.Get()
if shutdown {
break
}
nodeUpdate := item.(nodeUpdateItem)
hash := hash(nodeUpdate.nodeName, UpdateWorkerSize)
select {
case <-stopCh:
tc.nodeUpdateQueue.Done(item)
return
case tc.nodeUpdateChannels[hash] <- nodeUpdate:
// tc.nodeUpdateQueue.Done is called by the nodeUpdateChannels worker
}
}
}(stopCh)
go func(stopCh <-chan struct{}) {
for {
item, shutdown := tc.podUpdateQueue.Get()
if shutdown {
break
}
// The fact that pods are processed by the same worker as nodes is used to avoid races
// between node worker setting tc.taintedNodes and pod worker reading this to decide
// whether to delete pod.
// It's possible that even without this assumption this code is still correct.
podUpdate := item.(podUpdateItem)
hash := hash(podUpdate.nodeName, UpdateWorkerSize)
select {
case <-stopCh:
tc.podUpdateQueue.Done(item)
return
case tc.podUpdateChannels[hash] <- podUpdate:
// tc.podUpdateQueue.Done is called by the podUpdateChannels worker
}
}
}(stopCh)
wg := sync.WaitGroup{}
wg.Add(UpdateWorkerSize)
for i := 0; i < UpdateWorkerSize; i++ {
go tc.worker(i, wg.Done, stopCh)
}
wg.Wait()
}3.1 Worker
This worker consumes data from nodeUpdateChannels and podUpdateChannels and executes handleNodeUpdate and handlePodUpdate functions.
In terms of event processing priority, nodes take precedence over pods. In other words, if both node and pod events occur simultaneously, node events are processed first. After all node events are processed (i.e., nodeUpdateChannels is empty), pod events are then handled.
func (tc *NoExecuteTaintManager) worker(worker int, done func(), stopCh <-chan struct{}) {
defer done()
// When processing events we want to prioritize Node updates over Pod updates,
// as NodeUpdates that interest NoExecuteTaintManager should be handled as soon as possible -
// we don't want user (or system) to wait until PodUpdate queue is drained before it can
// start evicting Pods from tainted Nodes.
for {
select {
case <-stopCh:
return
case nodeUpdate := <-tc.nodeUpdateChannels[worker]:
tc.handleNodeUpdate(nodeUpdate)
tc.nodeUpdateQueue.Done(nodeUpdate)
case podUpdate := <-tc.podUpdateChannels[worker]:
// If we found a Pod update we need to empty Node queue first.
priority:
for {
select {
case nodeUpdate := <-tc.nodeUpdateChannels[worker]:
tc.handleNodeUpdate(nodeUpdate)
tc.nodeUpdateQueue.Done(nodeUpdate)
default:
break priority
}
}
// After Node queue is emptied we process podUpdate.
tc.handlePodUpdate(podUpdate)
tc.podUpdateQueue.Done(podUpdate)
}
}
}3.2 taintEvictionQueue - Scheduled Execution Queue
Previously, the data structure of taintEvictionQueue, which is of type TimedWorkerQueue, was introduced. Here, we explain how it works, which will help with understanding later.
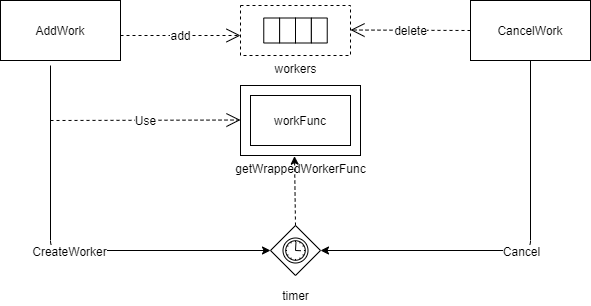
addWork: This function adds a pod to the queue and sets up a timer for automatic execution of the wrapped workFunc when the timer expires (i.e., scheduled pod eviction).
- It checks whether the pod is already in the queue based on the key, which is “podNamespace/podName.” If the pod is already in the queue, it returns early. This check prevents duplicate calls to
addWorkfor the same pod in case of node updates followed by subsequent update events. - It creates a worker using
CreateWorker, setting its creation time, execution time, timer, and the function to execute when the timer triggers. - It saves the created worker in the
workersmap.
This functionality is defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go.
// AddWork adds a work to the WorkerQueue which will be executed not earlier than `fireAt`.
func (q *TimedWorkerQueue) AddWork(args *WorkArgs, createdAt time.Time, fireAt time.Time) {
key := args.KeyFromWorkArgs()
klog.V(4).Infof("Adding TimedWorkerQueue item %v at %v to be fired at %v", key, createdAt, fireAt)
q.Lock()
defer q.Unlock()
if _, exists := q.workers[key]; exists {
klog.Warningf("Trying to add already existing work for %+v. Skipping.", args)
return
}
worker := CreateWorker(args, createdAt, fireAt, q.getWrappedWorkerFunc(key))
q.workers[key] = worker
}KeyFromWorkArgs() - This function generates a key for the given WorkArgs. The key is in the format “namespace/name,” representing “podNamespace/podName.”
// Defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go
// KeyFromWorkArgs creates a key for the given `WorkArgs`
func (w *WorkArgs) KeyFromWorkArgs() string {
return w.NamespacedName.String()
}
// Defined in staging\src\k8s.io\apimachinery\pkg\types\namespacedname.go
const (
Separator = '/'
)
// String returns the general-purpose string representation
func (n NamespacedName) String() string {
return fmt.Sprintf("%s%c%s", n.Namespace, Separator, n.Name)
}getWrappedWorkerFunc(key) returns a func(args *WorkArgs) error, which wraps the workFunc. The workFunc was defined during taint manager initialization for performing pod eviction (as explained in the initialization section above).
Here’s the execution logic of the wrapped function:
- Execute the
workFunc. - If the execution is successful, set the information saved under the key in the
workersmap to nil. This step prevents the key from being added to the queue again after successfully deleting the pod. Keys that have been successfully executed won’t be added again unlesscancelWorkWithEventis invoked. - If the execution fails, remove the key from the
workersmap. This allows the key to be added to the queue again in the future.
Defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go:
func (q *TimedWorkerQueue) getWrappedWorkerFunc(key string) func(args *WorkArgs) error {
return func(args *WorkArgs) error {
err := q.workFunc(args)
q.Lock()
defer q.Unlock()
if err == nil {
// To avoid duplicated calls we keep the key in the queue, to prevent
// subsequent additions.
q.workers[key] = nil
} else {
delete(q.workers, key)
}
return err
}
}CreateWorker - This function creates a worker and executes the wrapped workFunc.
If the fireAt time is before the createdAt time, it means the execution should happen immediately. In this case, a goroutine is started to execute the wrapped workFunc.
Otherwise, if the fireAt time is later than the createdAt time, a timer is set using time.AfterFunc. After the time duration of fireAt - createdAt, a goroutine is started to execute the wrapped workFunc. This is the key to self-executing queues and is why the TimedWorkerQueue doesn’t require a consuming function.
It returns a TimedWorker.
Defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go.
// CreateWorker creates a TimedWorker that will execute `f` not earlier than `fireAt`.
func CreateWorker(args *WorkArgs, createdAt time.Time, fireAt time.Time, f func(args *WorkArgs) error) *TimedWorker {
delay := fireAt.Sub(createdAt)
if delay <= 0 {
go f(args)
return nil
}
timer := time.AfterFunc(delay, func() { f(args) })
return &TimedWorker{
WorkItem: args,
CreatedAt: createdAt,
FireAt: fireAt,
Timer: timer,
}
}CancelWork - Removes a scheduled function execution from the queue. It returns true if the work was successfully canceled.
The function checks whether the given key exists in the workers map. If it exists and is not nil, it means the work hasn’t been executed yet. In this case, the function calls Cancel() to terminate the timer in the worker and removes the key from the workers map.
Defined in pkg\controller\nodelifecycle\scheduler\timed_workers.go:
// CancelWork removes scheduled function execution from the queue. Returns true if work was cancelled.
func (q *TimedWorkerQueue) CancelWork(key string) bool {
q.Lock()
defer q.Unlock()
worker, found := q.workers[key]
result := false
if found {
klog.V(4).Infof("Cancelling TimedWorkerQueue item %v at %v", key, time.Now())
if worker != nil {
result = true
worker.Cancel()
}
delete(q.workers, key)
}
return result
}
// Cancel cancels the execution of function by the `TimedWorker`
func (w *TimedWorker) Cancel() {
if w != nil {
w.Timer.Stop()
}
}3.3 handleNodeUpdate - Handling Node Events
This function iterates through the pods on a node, checks if the pod’s tolerations can tolerate the NoExecute taint on the node, and deletes the pod if it cannot tolerate it. If the pod can tolerate the taint, it waits for the minimum tolerationSeconds before deleting the pod.
- It fetches node information from the informer. If the node doesn’t exist (indicating it has been deleted), it removes the node from
taintedNodes. If there’s any other error, it returns. The reason for removing the node fromtaintedNodesis that later, inhandlePodUpdate, it fetches the NoExecute taints of nodes fromtaintedNodes. If the node doesn’t exist, it definitely has no taint. - It saves the NoExecute taints of the node in
taintedNodes. It checks if the node has NoExecute taints. If it doesn’t, it removes the node fromtaintedNodesand removes all pods on the node fromtaintEvictionQueueby executingcancelWorkWithEvent. Then, it returns, as there’s no need to process this node further. If the node has NoExecute taints, it saves them intaintedNodes. - It checks if there are any pods on the node. If there are no pods, it returns.
- It iterates through all the pods on the node and sequentially executes
processPodOnNode. This function checks if the NoExecute tolerations on the pods can tolerate the NoExecute taints on the node. If they cannot tolerate it, the pod is deleted. If they can tolerate it, the pod is scheduled for deletion after waiting for the minimum toleration time specified in the tolerations.
Defined in pkg\controller\nodelifecycle\scheduler\taint_manager.go.
func (tc *NoExecuteTaintManager) handleNodeUpdate(nodeUpdate nodeUpdateItem) {
node, err := tc.getNode(nodeUpdate.nodeName)
if err != nil {
if apierrors.IsNotFound(err) {
// Delete
klog.V(4).Infof("Noticed node deletion: %#v", nodeUpdate.nodeName)
tc.taintedNodesLock.Lock()
defer tc.taintedNodesLock.Unlock()
delete(tc.taintedNodes, nodeUpdate.nodeName)
return
}
utilruntime.HandleError(fmt.Errorf("cannot get node %s: %v", nodeUpdate.nodeName, err))
return
}
// Create or Update
klog.V(4).Infof("Noticed node update: %#v", nodeUpdate)
taints := getNoExecuteTaints(node.Spec.Taints)
func() {
tc.taintedNodesLock.Lock()
defer tc.taintedNodesLock.Unlock()
klog.V(4).Infof("Updating known taints on node %v: %v", node.Name, taints)
if len(taints) == 0 {
delete(tc.taintedNodes, node.Name)
} else {
tc.taintedNodes[node.Name] = taints
}
}()
// This is critical that we update tc.taintedNodes before we call getPodsAssignedToNode:
// getPodsAssignedToNode can be delayed as long as all future updates to pods will call
// tc.PodUpdated which will use tc.taintedNodes to potentially delete delayed pods.
pods, err := tc.getPodsAssignedToNode(node.Name)
if err != nil {
klog.Errorf(err.Error())
return
}
if len(pods) == 0 {
return
}
// Short circuit, to make this controller a bit faster.
if len(taints) == 0 {
klog.V(4).Infof("All taints were removed from the Node %v. Cancelling all evictions...", node.Name)
for i := range pods {
tc.cancelWorkWithEvent(types.NamespacedName{Namespace: pods[i].Namespace, Name: pods[i].Name})
}
return
}
now := time.Now()
for _, pod := range pods {
podNamespacedName := types.NamespacedName{Namespace: pod.Namespace, Name: pod.Name}
tc.processPodOnNode(podNamespacedName, node.Name, pod.Spec.Tolerations, taints, now)
}
}3.3.1 cancelWorkWithEvent
cancelWorkWithEvent - This function removes a pod’s work from the taintEvictionQueue. If the removal is successful, it sends a cancellation event for the pod eviction.
Defined in pkg\controller\nodelifecycle\scheduler\taint_manager.go:
func (tc *NoExecuteTaintManager) cancelWorkWithEvent(nsName types.NamespacedName) {
if tc.taintEvictionQueue.CancelWork(nsName.String()) {
tc.emitCancelPodDeletionEvent(nsName)
}
}
func (tc *NoExecuteTaintManager) emitCancelPodDeletionEvent(nsName types.NamespacedName) {
if tc.recorder == nil {
return
}
ref := &v1.ObjectReference{
Kind: "Pod",
Name: nsName.Name,
Namespace: nsName.Namespace,
}
tc.recorder.Eventf(ref, v1.EventTypeNormal, "TaintManagerEviction", "Cancelling deletion of Pod %s", nsName.String())
}3.3.2 processPodOnNode
processPodOnNode - This function compares taints and tolerations to determine if a pod can tolerate the node’s noExecute taint. If the pod cannot tolerate the taint, it is immediately deleted. Otherwise, it waits for the minimum tolerationSeconds from tolerations and then deletes the pod.
- It checks if there are any taints associated with the node. If there are no taints, it cancels the work associated with the pod and removes it from the queue. This is done to prevent the pod from being added to the queue again.
- It compares the taints and tolerations to determine if the pod can fully tolerate the taints. If not, it cancels the work associated with the pod, ensuring that it’s not in the queue, and then adds the work with
createdandfiredtimes set to the current time, effectively executing the deletion of the pod immediately. - It calculates the minimum
tolerationSecondsfrom the used tolerations. - It checks if there’s already a worker for the pod in the queue. If so, it compares the previous
createdtime to the current time. If the previouscreatedtime is in the past, it does nothing, preserving the original worker. If it’s not in the past, it cancels the previous work and creates a new one. - Finally, it adds the work to the queue with
createdset to the current time andfiredset to the current time plus the minimumtolerationSeconds.
Defined in pkg\controller\nodelifecycle\scheduler\taint_manager.go.
func (tc *NoExecuteTaintManager) processPodOnNode(
podNamespacedName types.NamespacedName,
nodeName string,
tolerations []v1.Toleration,
taints []v1.Taint,
now time.Time,
) {
// Check if there are any taints on the node. If not, cancel the pod's work.
if len(taints) == 0 {
tc.cancelWorkWithEvent(podNamespacedName)
}
// Check if all taints are tolerated by the pod's tolerations.
allTolerated, usedTolerations := v1helper.GetMatchingTolerations(taints, tolerations)
if !allTolerated {
klog.V(2).Infof("Not all taints are tolerated after an update for Pod %v on %v", podNamespacedName.String(), nodeName)
// We're canceling scheduled work (if any), as we're going to delete the Pod right away.
// First, remove the pod from the taintEvictionQueue because AddWork checks if it's in the queue and won't add it again.
// We need to reset the `created` and `fired` times to execute the deletion immediately.
tc.cancelWorkWithEvent(podNamespacedName)
// The taintEvictionQueue contains timers, so we don't need other functions to handle this queue.
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), time.Now(), time.Now())
return
}
// Calculate the minimum toleration time from the tolerations.
minTolerationTime := getMinTolerationTime(usedTolerations)
// Check if the calculated toleration time is negative, indicating infinite toleration.
if minTolerationTime < 0 {
klog.V(4).Infof("New tolerations for %v allow infinite toleration. Scheduled deletion won't be canceled if it's already scheduled.", podNamespacedName.String())
return
}
startTime := now
triggerTime := startTime.Add(minTolerationTime)
// Check if there's already a scheduled eviction for the pod in the taintEvictionQueue.
scheduledEviction := tc.taintEvictionQueue.GetWorkerUnsafe(podNamespacedName.String())
if scheduledEviction != nil {
startTime = scheduledEviction.CreatedAt
// If the `startTime` is before the current time, it means the work was created in the past and eviction was triggered earlier.
// In this case, it's a valid state, and we don't perform any action to maintain the original work.
if startTime.Add(minTolerationTime).Before(triggerTime) {
return
}
// If the `startTime` is in the future or the present, cancel the original work and create a new one.
tc.cancelWorkWithEvent(podNamespacedName)
}
// Add the work to the taintEvictionQueue with the `startTime` and `triggerTime`.
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), startTime, triggerTime)
}3.4 handlePodUpdate
The handlePodUpdate function is responsible for processing updates to pods. Here’s a breakdown of its logic:
- It starts by fetching information about the pod from the informer. If the pod doesn’t exist, which means it has already been deleted, it cancels any pending work related to the pod and returns.
- Next, it checks if the pod’s assigned node has changed. If the node assignment has changed, there’s no need to process the pod further, so it returns.
- If the node name is empty, it means the pod hasn’t been scheduled to a node yet, so there’s no need to process it, and it returns.
- It then checks if the node where the pod is assigned has any
noExecutetaints. If the node doesn’t have anynoExecutetaints or if the node has been removed, it cancels any pending work related to the pod and returns. - Finally, it calls the
processPodOnNodefunction to process the pod based on the taints and tolerations. This function determines whether the pod’s tolerations can tolerate thenoExecutetaint on the node. If the tolerations are insufficient, the pod is scheduled for immediate deletion. If the tolerations are sufficient, the function schedules the deletion of the pod after waiting for the minimumtolerationSecondsspecified in its tolerations.

