利用aws nlb平滑滚动更新ingress controller-不中断服务
1 概述
在云上让集群外部流量访问k8s,通常的做法是使用loadbalance类型的service,让外部流量通过loadbalance进入到ingress controller,然后分发到各个pod。
ingress controller是需要要更新版本或者变更配置的,一般变更配置都需要程序进行重启。那么在ingress controller需要滚动更新时候会发生什么,ingress访问会不会中断?
下面在aws上自建kubernetes集群,使用traefik 2作为ingress controller,并且部署了aws loadbalance controller 2.2.0,使用官方的helm仓库 9.19.1版本安装的traefik2。nlb使用3个可用区,使用ip模式的target,不使用loadbalce类型,直接使用headless clusterIP类型service–aws loadbalancer controller支持,网络插件使用amazon vpc cni插件。
2 为什么这么设计?
2.1 为什么不使用loadbalancer类型的service,为什么要使用nlb,而不用alb?
nlb基于4层直接进行转发,不需要解析http协议,性能好、延迟低。
如果target type是instance类型,则kubernetes service类型必须是NodePort或LoadBalancer。
如果target type是ip类型,则nlb必须跟pod直通,不需要进行nat,但是必须使用amazon vpc cni网络插件。
k8s中默认的loadbalancer类型service会分配node port, 如果targert type是instance类型,nlb的流量会通过node port转发到pod,增加了响应延迟。而targert type是ip,默认也会分配node port,但是nlb直接将流量转发到pod,不需要经过node port转发。
aws loadbalancer controller支持target type为ip类型和instance类型,而内嵌在controller-mananger中的cloud controller只支持instance类型。
使用headless service,因为不分配node port和cluster ip,节约ip和node port端口资源。在1.20版本开始支持loadbalancer类型service不分配node port,lb直接与pod进行通行,开启这个功能需要开启ServiceLBNodePortControl feature gate,且设置spec.allocateLoadBalancerNodePorts为false。
sevice yaml
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: traefik2
meta.helm.sh/release-namespace: kube-system
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: /ping
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-name: k8s-traefik2-ingress
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internal
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: deregistration_delay.timeout_seconds=120,
preserve_client_ip.enabled=true
service.beta.kubernetes.io/aws-load-balancer-type: external
creationTimestamp: "2021-06-04T14:37:20Z"
finalizers:
- service.k8s.aws/resources
labels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: traefik
helm.sh/chart: traefik-9.19.1
name: traefik2
namespace: kube-system
resourceVersion: "734023"
uid: 65312c00-99dd-4713-869d-8b3cba4032bb
spec:
clusterIP: None
clusterIPs:
- None
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: web
port: 80
protocol: TCP
targetPort: web #这个对应pod里的3080
- name: websecure
port: 443
protocol: TCP
targetPort: websecure #这个对应pod里的3443
selector:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefik
sessionAffinity: None
type: ClusterIP
status:
loadBalancer:
ingress:
- hostname: k8s-traefik2-ingress-5d6f374f2146c85a.elb.us-east-1.amazonaws.com3 优化参数
3.1 保留客户端ip
target type是ip类型,nlb默认不会保留客户端ip,需要手动开启保留客户端ip功能,nlb保留ip前提条件是所有的target在同一vpc中,即traefik pod在同一vpc中。
同时traefik 2支持 proxy protocol v1和v2版本(traefik v1版本只支持proxy protocol v1版本)来获取客户端ip,可以开启nlb的proxy-protocol。
3.2 配置readiness gate避免pod创建和lb的注册和反注册不是同步
3.2.1 traefik2进行滚动更新过程与target注册反注册
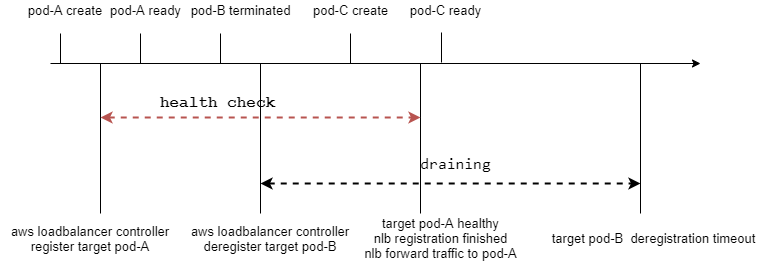
图中可以发现在deployment的滚动更新和lb的注册和反注册不是同步的,如果健康检查周期内可用区没有可用的target–可用区内的target健康检查都未完成,那么这个可用区的ip就会从nlb域名解析中移除。如果健康检查周期内所有可用区都没有可用的target–所有可用区内的target健康检查都未完成,那么整个nlb不可用。
aws loadbalancer controller创建target的健康配置–HealthCheckTimeoutSeconds为6、HealthCheckIntervalSeconds为10、HealthyThresholdCount为3,UnhealthyThresholdCount为3,从pod生成到健康检查通过接收流量大约需要3分钟。也就是说如果3分钟内,deployment滚动更新完,那么这个nlb就处于不可用状态。如果3分钟内,一个可用区的pod都处于健康检测未完成,那么这个可用区的nlb实例ip会从域名解析中移除。
3.2.2 配置readiness gate
在aws loadbalance controller支持设置nlb为pod的readiness gate,这样当pod生成之后,必须readiness probe通过和readiness gate通过,这样deployment才会进行终止pod,这样保证了滚动更新一定有可用的target接收流量。经过测试从pod生成到readiness gate通过大约需要5分钟。
配置readiness gate之后的流程图
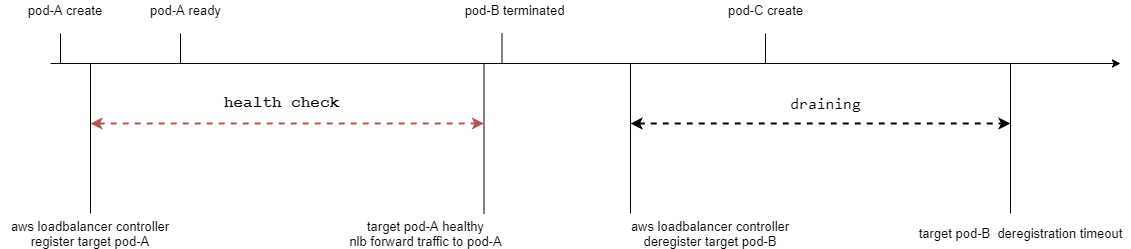
配置readiness gate
#编辑mutatingwebhookconfigurations
kubectl edit mutatingwebhookconfigurations aws-load-balancer-controller-webhook
objectSelector:
name: mpod.elbv2.k8s.aws
namespaceSelector:
matchExpressions:
- key: elbv2.k8s.aws/pod-readiness-gate-inject
operator: In
values:
- enabled
objectSelector:
#添加下面这两行
matchLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
#给kube-system namespace添加标签
kubectl label namespace kube-system elbv2.k8s.aws/pod-readiness-gate-inject=enabled
#设置traefik pod label,这个在values.yaml里设置
deployment:
podLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled3.3 解决aws loadbalancer controller收到pod delete事件延迟问题
由于删除pod是由replicaset控制,将请求发给apiserver,aws loadbalancer controller收到事件之后,通知nlb进行target deregister,所以pod删除和nlb的deregister是不同步的,有可能出现pod已经被删掉但是在target上还是可用状态,这样流量转发到这个pod的ip就会出现问题。
如何解决这个问题呢?
可以在pod lifecyle里添加prestop hook进行sleep 10秒,防止在pod terminal过程中,有新的连接进入。10秒基本能保证,nlb已经停止转发新的连接到这个pod的ip,aws loadbalance controller接收到pod delete事件,在target group中进行反注册–在target group中,处于draining或unused。
目前helm chart 9.19.1还不支持设置pod的lifecycle,你需要手动配置:(。或者利用traefik自身的参数transport.lifeCycle.requestAcceptGraceTimeout=10,在执行优雅关闭之前继续接收连接。注意traefik helm chart里pod的terminationGracePeriodSeconds为60s–在helm chart hard code,所以requestAcceptGraceTimeout +graceTimeOut要小于terminationGracePeriodSeconds, 默认的transport.lifeCycle.graceTimeOut(traefik等待未关闭连接时间)为10s。
但是配置完之后,发现aws load balancer controller里显示了已经deRegistered target–基本秒级别操作,但是删除的pod还能收到新的连接。 这是由于nlb还需要30到90s才能成功deRegistered target(在这期间nlb继续转发新连接到target,然后才停止转发新连接直到connection_termination,在connection_termination之前已经建立的连接会继续转发)–相关#issue1064,所以至少需要设置requestAcceptGraceTimeout或sleep为90s,且需要手动调大terminationGracePeriodSeconds,但是目前traefik helm chart不支持设置terminationGracePeriodSeconds这个值–需要等待PR411合并。
aws load balancer controller 秒级deRegistered target
{"level":"info","ts":1623221227.4900389,"msg":"deRegistering targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-3e41e3e1b5/74840e00b5fce25f","targets
":[{"AvailabilityZone":"us-east-1f","Id":"10.52.79.105","Port":3080}]}
{"level":"info","ts":1623221227.4903376,"msg":"deRegistering targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-5ce7e766f7/6e7b481251bf928e","targets
":[{"AvailabilityZone":"us-east-1f","Id":"10.52.79.105","Port":3443}]}
{"level":"info","ts":1623221227.524495,"msg":"deRegistered targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-3e41e3e1b5/74840e00b5fce25f"}
{"level":"info","ts":1623221227.5618162,"msg":"deRegistered targets","arn":"arn:aws:elasticloadbalancing:us-east-1:474981795240:targetgroup/k8s-kubesyst-traefik2-5ce7e766f7/6e7b481251bf928e"}相应的配置
#pod里配置
lifecycle:
preStop:
exec:
command:
- /bin/bash
- -c
- sleep 90
#或者traefik配置
--entryPoints.web.transport.lifeCycle.requestAcceptGraceTimeout=90
#在deployment里修改terminationGracePeriodSeconds
terminationGracePeriodSeconds: 120设置prestop之后的流程
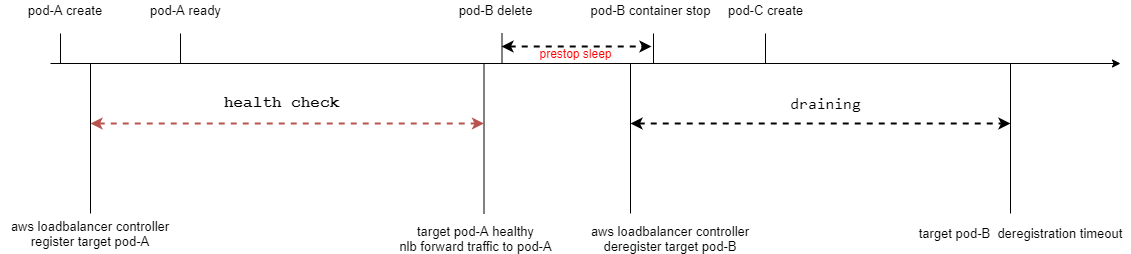
同时需要nlb设置deregistration_delay.timeout_seconds来等待未关闭的连接关闭,然后再将target从target group移除。nlb的deregistration_delay.timeout_seconds必须大于等于pod退出的时间,官方推荐的值为120s。当traefik退出的时候会关闭所有的连接,所以这个值只要大于等于120秒就可以了。为了防止pod有可能一直处于terminaled状态,导致已经建立连接一直hang着,还可以配置deregistration_delay.connection_termination.enabled在移除之前强制关闭已经建立的连接。
3.4 健康检测配置
traefik2在程序退出的时候,处于graceful shutting down,包括request Accept Grace阶段–这个时候接受新的连接请求,和termination GracePeriod阶段–结束已经建立的连接。
如果nlb使用tcp端口进行健康检测,则在traefik graceful shutting down时候,在request Accept Grace阶段依然是健康检测通过,这显然不准确。
traefik的health-check /ping接口,就能真实的反应treafik的运行状态,因为在graceful shutting down时候,接口会返回503。
nlb配置健康检测类型为HTTP,健康检测url为/ping,健康检测端口为traefik entrypoint端口。
chart values.yaml配置为
service:
annotations:
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: "/ping"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-protocol: "HTTP"3.5 避免可用区里无可用pod
在滚动更新过程中,如果deployment的maxunavailable设置大于某个可用区内的traefik pod数量,或者这个区域的pod数量为1, 有可能出现这个可用区没有可用的pod(pod被terminate),那么nlb在这个可用区的ip会从域名解析中移除,如果客户端程序,访问的时候依然访问这个ip(可能dns缓存还未刷新,或者直接使用缓存的解析),那么这个连接会直接被reset。
为了防止这种情况发生,需要设置maxunavailable小于所有可用区中traefik pod最小数量,maxSurge小于等于所有可用区中traefik pod最小数量, 我这里spec为6,所以设置maxunavailable为0,maxSurge设置为1, 且每个区pod数量必须大于等于2。这个是由于replicaset scale down时候,没有考虑pod topology spread #issue96748,有可能会导致可用区所有的pod都被scale down。
同时配合topologySpreadConstraints(1.18之前版本需要启用EvenPodsSpread feature gate,1.18之后包含1.18默认启用),均衡每个可用区的traefik pod数量。1.20版本中内置的defaultConstraints就能满足大部分需求,每个主机的pod数量最多差3个,zone之间的pod数量 最多差5个。
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway如果需要更严格的均衡,在deployment里的sepc.template.spec里配置,traefik helm chart 9.19.1版本还没有合并支持topologySpreadConstraints PR,可以手动配置。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefik
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app.kubernetes.io/instance: traefik2
app.kubernetes.io/name: traefik同时也可以利用aws的autoscale group或者cluster scale,增加node节点资源可用性。
4 总结
1.使用readiness gate,解决滚动更新速度快于健康检测完成,导致target group里target可用数量减少或没有target可用的。
2.使用pod的prestop lifecycle或traefik配置requestAcceptGraceTimeout,解决deployment和aws loadbalance controller步调不一致的问题。
3.使用topologySpreadConstraints和maxunavailable解决可用区里无健康target。
4.开启nlb保留客户端ip功能,保留客户端ip。
配置文件
The helm chart file values.yaml
deployment:
replicas: 6
podLabels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
additionalArguments:
- "--providers.kubernetesingress.ingressclass=traefik2"
- "--providers.kubernetescrd.ingressclass=traefik2"
- "--entryPoints.web.forwardedHeaders.insecure"
#- "--entryPoints.web.proxyProtocol.insecure"
- "--api.insecure=true"
- "--metrics.prometheus=true"
- "--entryPoints.web.transport.lifeCycle.requestAcceptGraceTimeout=90"
globalArguments:
- "--global.sendanonymoususage=false"
ports:
traefik:
port: 8082
web:
port: 3080
websecure:
port: 3443
service:
type: ClusterIP
spec:
clusterIP: None
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
service.beta.kubernetes.io/aws-load-balancer-scheme: "internal"
service.beta.kubernetes.io/aws-load-balancer-name: "k8s-traefik2-ingress"
#service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: "*"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8082"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-path: "/ping"
service.beta.kubernetes.io/aws-load-balancer-healthcheck-protocol: "HTTP"
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: "deregistration_delay.timeout_seconds=120, preserve_client_ip.enabled=true"
#service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: "eregistration_delay.timeout_seconds=120, preserve_client_ip.enabled=true, deregistration_delay.connection_termination.enabled=true"
podDisruptionBudget:
enabled: true
minAvailable: 1
rollingUpdate:
maxUnavailable: 0
maxSurge: 1参考资料
https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/guide/service/annotations
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/target-group-health-checks.html
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/network-load-balancers.html
https://stackoverflow.com/a/51471388/6059840
https://github.com/kubernetes/kubernetes/issues/45509
https://github.com/kubernetes/kubernetes/pull/99212
https://github.com/kubernetes/kubernetes/pull/101080
https://github.com/kubernetes/enhancements/issues/2255
https://stackoverflow.com/a/67203212/6059840
https://aws.amazon.com/premiumsupport/knowledge-center/elb-fix-failing-health-checks-alb/
https://stackoverflow.com/questions/33617090/kubernetes-scale-down-specific-pods


![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)