深度解析descheduler的highNodeUtilization和lowNodeUtilization插件的原理
最近在研究descheduler,主要为了解决node节点出现cpu热点问题,即节点的cpu使用率相差特别大,而节点的request分布均匀。我们知道kube-scheduler将pod调度到节点上,而descheduler将pod进行移除,让workload控制器重新生成pod,并再次触发pod调度流程将pod调度到节点。通过这个方法达到pod重调度和节点的平衡目的。
社区的descheduler项目为了解决以下场景:
- 部分节点利用率过高,需要平衡节点的利用率
- 在pod调度之后,节点的label、taint不满足pod的pod/node affinity,需要将pod移动到符合的节点
- 新节点加入集群,需要平衡节点的利用率
- pod处于failed状态但是没有清理
- 同一个workload的pod集中在同一节点上
descheduler利用插件机制来扩展它的能力,插件分为Balance(节点平衡)和Deschedule(pod重调度)两个类型。
它提供了这些插件:
| Name | Extension Point Implemented | Description |
|---|---|---|
| RemoveDuplicates | Balance | Spreads replicas 让相同workload的pod打散在不同节点 |
| LowNodeUtilization | Balance | Spreads pods according to pods resource requests and node resources available 平衡目标的节点的利用率 |
| HighNodeUtilization | Balance | Spreads pods according to pods resource requests and node resources available 让pod集中在几个节点上 |
| RemovePodsViolatingInterPodAntiAffinity | Deschedule | Evicts pods violating pod anti affinity 驱逐pod违背了pod anti affinity |
| RemovePodsViolatingNodeAffinity | Deschedule | Evicts pods violating node affinity 驱逐pod违背了node affinity |
| RemovePodsViolatingNodeTaints | Deschedule | Evicts pods violating node taints 驱逐pod不能容忍节点的污点 |
| RemovePodsViolatingTopologySpreadConstraint | Balance | Evicts pods violating TopologySpreadConstraints 驱逐pod违背了TopologySpreadConstraints |
| RemovePodsHavingTooManyRestarts | Deschedule | Evicts pods having too many restarts 驱逐pod有太多次重启 |
| PodLifeTime | Deschedule | Evicts pods that have exceeded a specified age limit pod生存一段时间后执行驱逐 |
| RemoveFailedPods | Deschedule | Evicts pods with certain failed reasons 驱逐处于failed的pod |
这篇文章研究平衡节点的利用率插件HighNodeUtilization和LowNodeUtilization,但是它们都是基于request来统计节点的利用率的,所以并不能真正解决节点cpu过热(部分节点利用率过高)。但是研究这两个插件的执行逻辑,有助于自己开发插件解决节点cpu过热问题。
1 HighNodeUtilization插件介绍
HighNodeUtilization它是将利用率低的节点上的pod移动到利用率高的节点,结合clusterAutoScaler将空闲的节点移出集群并进行销毁(回收),即目的是提高节点的利用率。
这里的利用率等同于节点request的使用率,节点request的使用率为node上所有pod的request之和占node上可以分配资源比值,即NodeUtilization=PodsRequestsTotal * 100 / nodeAllocatable
低利用率underutilizedNodes和高利用率节点overutilizedNodes是根据thresholds进行区分,节点request的使用率大于thresholds为高利用率节点(合理利用率节点),节点request的使用率小于等于thresholds为低利用率节点。
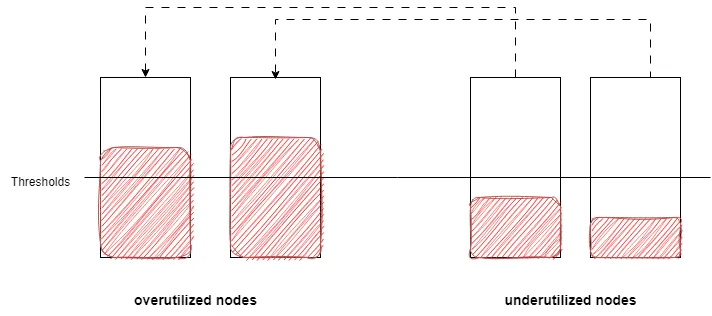
1.1 HighNodeUtilization配置项
这里的thresholds是HighNodeUtilization插件的配置项,同时它还有numberOfNodes和evictableNamespaces两个配置项,numberOfNodes代表低利用率节点数量小于等于这个数量不进行驱逐,evictableNamespaces代表忽略这些命名空间下的pod。
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "HighNodeUtilization"
args:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
evictableNamespaces:
exclude:
- "kube-system"
- "namespace1"
plugins:
balance:
enabled:
- "HighNodeUtilization"2 lowNodeUtilization插件介绍
lowNodeUtilization插件它是将高利用率的节点上的pod移动到低利用率的节点上,目标是平衡节点的利用率。
同样这里的利用率等同于节点request的使用率,节点request的使用率为node上所有pod的request之和占node上可以分配资源比值,即NodeUtilization=PodsRequestsTotal * 100 / nodeAllocatable
这个插件将节点分为高利用率节点overutilizedNodes、低利用率节点underutilizedNodes、合理利用率节点targetutilizedNodes。它是根据thresholds 和targetThresholds和useDeviationThresholds进行区分,这里跟highNodeUtilization不一样它有两个阈值,即低水位阈值lowResourceThreshold和高水位阈值highResourceThreshold,而useDeviationThresholds代表阈值水位线是否基于所有节点的request平均利用率。
当useDeviationThresholds不启用的时候,thresholds为低水位阈值lowResourceThreshold,targetThresholds为高水位阈值highResourceThreshold。节点所有资源类型request的利用率都小于等于低水位阈值lowResourceThreshold(不包括不可调度节点)为低利用率节点underutilizedNodes,节点有一个资源类型的request的利用率大于高水位阈值highResourceThreshold(包括不可调度节点)为高利用率节点overutilizedNodes,节点request的利用率介于lowResourceThreshold和highResourceThreshold之间为合理利用率节点targetutilizedNodes。
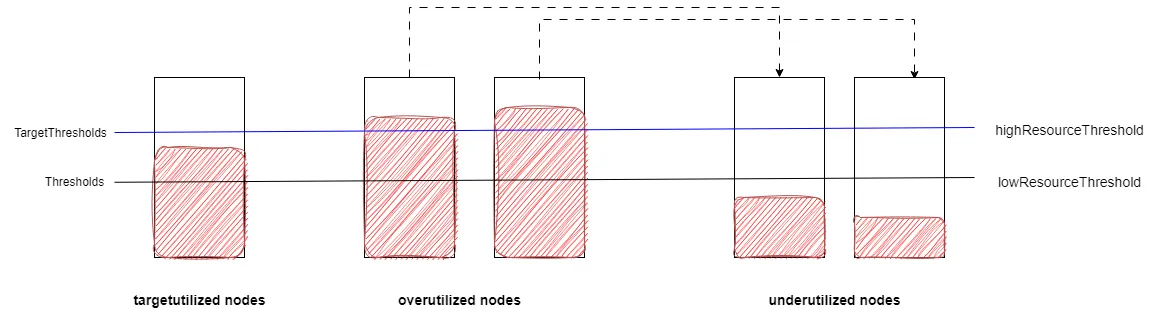
当useDeviationThresholds启用的时候,先计算所有节点的request平均使用率averageResourceUsagePercent,低水位阈值lowResourceThreshold为thresholds - averageResourceUsagePercent,高水位阈值highResourceThreshold为targetThresholds + averageResourceUsagePercent。节点的分类规则跟不启用useDeviationThresholds一样。
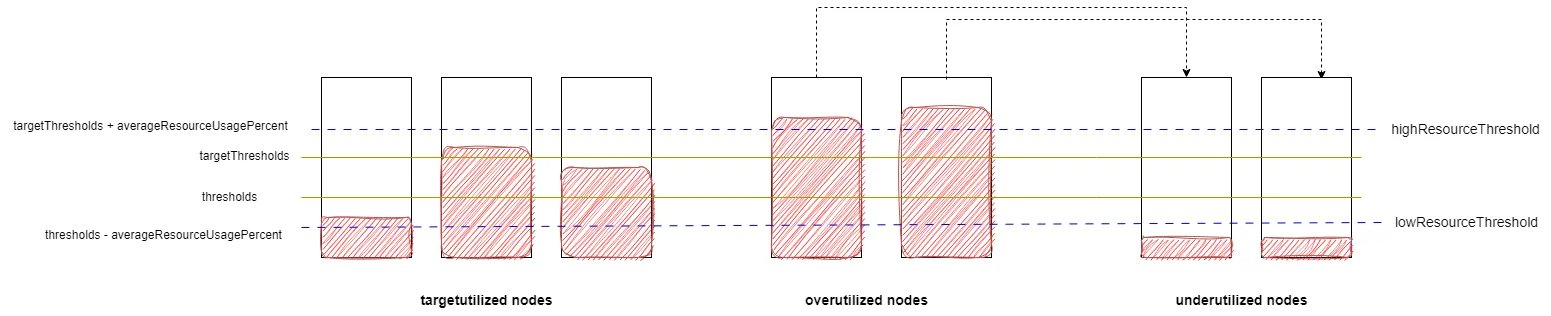
2.1 lowNodeUtilization配置项
配置项有useDeviationThresholds、thresholds、targetThresholds、numberOfNodes、evictableNamespaces。
thresholds用来决定节点是否为低利用率节点。
targetThresholds用来决定节点是否为高利用率节点。
useDeviationThresholds代表阈值水位线是否基于所有节点的request平均利用率。
numberOfNodes代表低利用率节点数量小于等于这个数量不进行驱逐。
evictableNamespaces代表忽略这些命名空间下的pod。
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "LowNodeUtilization"
args:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
plugins:
balance:
enabled:
- "LowNodeUtilization"3 其他配置项
下面配置项为descheduler的全局配置
| Name | type | Default Value | Description |
|---|---|---|---|
nodeSelector | string | nil | limiting the nodes which are processed. Only used when nodeFit=true and only by the PreEvictionFilter Extension Point这个用于PreEvictionFilter扩展点,default Evictor实现了这个扩展点,当default Evictor配置里的nodeFit启用时候,用于过滤出目标节点,并判断能否从这些节点里找到能够容纳被驱逐pod的节点 |
maxNoOfPodsToEvictPerNode | int | nil | maximum number of pods evicted from each node (summed through all strategies) 节点已经驱逐pod累计数量大于这个值,则停止执行这个node的pod驱逐 |
maxNoOfPodsToEvictPerNamespace | int | nil | maximum number of pods evicted from each namespace (summed through all strategies) 每个namespace下最大驱逐的pod数量,达到这个数量则忽略这个namespace下的pod |
default Evictor配置项
| Name | type | Default Value | Description |
|---|---|---|---|
nodeSelector | string | nil | limiting the nodes which are processed 筛选出的节点才会执行重调度 |
evictLocalStoragePods | bool | false | allows eviction of pods with local storage 是否驱逐带有本地存储的pod |
evictSystemCriticalPods | bool | false | [Warning: Will evict Kubernetes system pods] allows eviction of pods with any priority, including system pods like kube-dns 是否驱逐优先级为SystemCritical的pod |
ignorePvcPods | bool | false | set whether PVC pods should be evicted or ignored 有pvc的pod是否驱逐 |
evictFailedBarePods | bool | false | allow eviction of pods without owner references and in failed phase 孤儿pod且为failed状态是否驱逐 |
labelSelector | metav1.LabelSelector | (see label filtering) pod匹配这个LabelSelector才会被驱逐 | |
priorityThreshold | priorityThreshold | (see priority filtering) pod的优先级小于这个级别才会被驱逐 | |
nodeFit | bool | false | (see node fit filtering) nodeFit启用时候,使用全局配置中的nodeSelector过滤出目标节点,并判断能否从这些节点里找到能够容纳被驱逐pod的节点 |
4 执行流程
lowNodeUtilization和highNodeUtilization插件的执行流程都一样,只是pod移动的源节点和目标节点不一样,即选择那些节点(进行pod驱逐)的标准不一样。
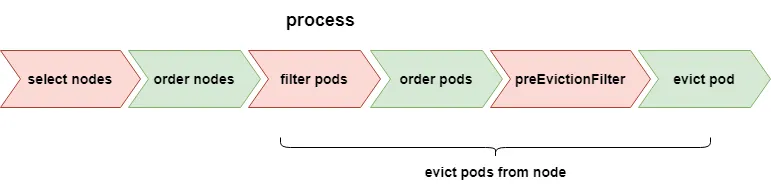
执行流程:
- select nodes:选择需要执行驱逐pod的节点
- order nodes:对node进行排序
- filter pods:筛选出node上能够被驱逐的pod列表
- order pods:pod排序
- preEvictionFilter:检测pod是否满足限制条件
- evict pod:执行驱逐
4.1 select nodes
从集群所有节点筛选出满足下面两个条件的节点:
- 节点匹配descheduler全局配置里nodeSelect
- lowNodeUtilization插件里节点为高利用率节点
highResourceThreshold,highNodeUtilization插件里节点为低利用率节点underutilizedNodes。
然后对node节点进行分类,分类方法在前面的插件的介绍中已经讲了。这里进行分类的目的是为了判断是否需要执行后续步骤,比如没有节点符合驱逐条件,那么不需要执行后面步骤。
是否执行后续步骤,根据下面的条件进行判断:
lowNodeUtilization插件,满足下面任意一个条件的不执行后续步骤。
- 低利用率节点数量为0
- 低利用率节点的数量小于等于lowNodeUtilization插件配置里NumberOfNodes
- 高利用率节点的数量为0
- 低利用率节点数量等于上面筛选出的节点数量
highNodeUtilization插件,满足下面任意一个条件的不执行后续步骤。
- 低利用率节点数量为0(说明筛选出的节点全都是高利用率节点)
- 低利用率节点数量小于等于highNodeUtilization插件配置里NumberOfNodes
- 低利用率节点数量等于上面筛选出的节点数量(说明筛选出的节点全都是高利用率节点)
- 高利用率节点数量为0(说明筛选出的节点全都是低利用率节点)
4.2 order nodes
对上面筛选后的node执行排序。对于lowNodeUtilization插件里所有资源类型的request之和,越大的节点排在前面。对于highNodeUtilization插件里所有资源类型的request之和,越小的节点排在前面。
4.3 evict pod from node
按照上面的node顺序,执行node上pod驱逐。后面的流程都是执行node上pod驱逐的子流程,包括filter pods、order pods、preEvictionFilter、evict pod流程。
4.3.1 filter pods
筛选出节点上能够被驱逐的pod,包括主动标记需要驱逐的pod和符合条件的其他pod。主动标记的pod为该pod的annotations里有"descheduler.alpha.kubernetes.io/evict"。
符合条件的其他pod为匹配下面的所有规则:
- 不是daemonset生成的pod
- 不是static pod
- 不是mirror pod
- pod未被删除
- 当default Evictor的配置项里EvictFailedBarePods为true,则pod有ownerReference,或pod没有ownerReference且pod的phase为Failed状态
- 当default Evictor的配置项里EvictFailedBarePods为false,则pod有ownerReference
- 当default Evictor的配置项里EvictSystemCriticalPods为false且没有配置PriorityThreshold,则pod的优先级小于systemCritical(优先级为200000000)
- 当default Evictor的配置项里EvictSystemCriticalPods为false且配置了PriorityThreshold,则pod的优先级小于PriorityThreshold里定义优先级(优先读取priorityThreshold.Value,如果没有设置,则读取priorityThreshold.Name)
- 当default Evictor的配置项里EvictLocalStoragePods为false,则pod的volume里没有HostPath和EmptyDir
- 当default Evicor的配置项里的IgnorePvcPods为true,则pod的volume里没有PersistentVolumeClaim
- 当default Evicor的配置项里设置了LabelSelector,则pod匹配这个LabelSelector
4.3.2 order pods
对上面筛选出来的pods进行排序,排序规则为:第一排序字段为pod的优先级,第二排序字段为pod的qos class。即首先根据pod优先级进行排序,没有优先级的pod排在前面,有优先级的pod排在后面。如果两个pod都有优先级,按照从小到大排序。如果优先级一样(都没有优先级的两个pod,也认为它们优先级一样),则按照besfEffort、Burstable、Guaranteed顺序进行排序。如果qos一样,则顺序不变。
4.3.3 preEvictionFilter
这个步骤主要是检测是否有节点可以调度,pod是否匹配命名空间白名单。主要为了考虑驱逐pod之后应用的稳定性,比如说不会出现驱逐后pod没有节点可以调度,比如为了维护应用的可用性,限制命名空间pod驱逐数量。
当Default Evictor的配置项里NodeFit为true,则会检测pod是否有节点可以调度,下面是执行逻辑。
- 根据Default Evictor的配置项里NodeSelector,获得所有node列表(如果NodeSelector为空,则为集群中所有节点),然后过滤出所有ready node。
- 查找是否有满足下面所有条件的node。这个就是kube-scheduler里的predicates算法,通过跟调度器使用一样算法保证被驱逐的pod后,新生的pod一定有node可以调度,这也是插件使用request来计算节点资源使用的原因(kube-scheduler也是基于request进行调度)。
- 满足pod的Spec.NodeSelector和Spec.Affinity.RequiredDuringSchedulingIgnoredDuringExecution
- pod.Spec.Tolerations能够容忍node.Spec.Taints(只考虑NoSchedule and NoExecute的taint)
- 非pod所在node,且node剩余资源满足pod的request
- node是可以调度状态
如果通过上面的算法找到了可以调度的节点,则进行白名单过滤(检测pod的namespace是否匹配插件配置项里evictableNamespaces.exclude)。否则不对这个pod执行驱逐。
当pod的namespace匹配“lowNodeUtilization、highNodeUtilization配置项里evictableNamespaces.exclude”,则不对这个pod执行驱逐。即当没有找到可以调度的节点,或pod的namespace命中了lowNodeUtilization、highNodeUtilization的namespace白名单,则pod不会被驱逐。
4.3.4 evict pod
先执行descheduler的全局策略,限制单节点的驱逐pod数量和限制每个namespace的pod驱逐数量。其中全局配置maxNoOfPodsToEvictPerNode为单节点的驱逐pod数量限制,maxNoOfPodsToEvictPerNamespace为每个namespace的pod驱逐数量限制。
如果pod的通过了上面的策略限制,则执行最终的驱逐pod动作。否则,不执行驱逐这个pod。
4.3.5 何时停止驱逐节点上pod
在每次对pod执行驱逐之后,都会检测这次驱逐后节点是否达到合理(期望)的利用率。如果达到合理的利用率,那么这个节点的驱逐流程就结束,继续节点的下一个pod驱逐。
对于lowNodeUtilization插件达到合理的利用率:node达到期望利用率(即所有资源类型的request的使用率都小于等于高水位阈值highResourceThreshold,node节点从高利用率节点overutilizedNodes变为合理利用率节点targetutilizedNodes),或所有低利用率nodes总剩余(未分配)资源里至少有一种资源(cpu、memory、pods等)的request为小于等于0(即低利用率节点没有资源可以分配了)。
对于highNodeUtilization插件达到合理的利用率:所有高利用率nodes的剩余资源里有一个resource的request值为小于等于0,即高利用率节点总剩余(未分配)资源里至少有一种资源(cpu、memory、pods等)的request小于等于0。
这里还有一个情况也会让节点的驱逐流程结束,某个节点的驱逐的pod数量达到了descheduler全局策略限制(全局配置里的maxNoOfPodsToEvictPerNode),这个对于highNodeUtilization和lowNodeUtilization插件都生效。
5 存在的问题
但是由于使用request来统计资源使用量,这个并不能真实的反应节点真实资源使用,所以并不适合在生产上使用。目前社区里有issue “Use actual node resource utilization in the strategy “LowNodeUtilization”” 跟踪这个问题,并有两个PR实现来解决这个问题,分别是“real utilzation descheduler #1092” “feat: support TargetLoadPacking strategy”。
descheduler依赖于workload controller和scheduler机制,保证驱逐一个pod后,这个pod属于的workload的能够重新生成新的pod,然后调度器将这个新pod调度到理想的目标节点。但是实际上调度器并不一定将新pod调度到理想的目标节点,而且还有可能新生的pod又调度到原先的节点,社区里就有人反馈“LowNodeUtilization does not take into account podAntiAffinity when choosing a pod to evict”。虽然descheduler里有nodeFit的功能(检测pod是否有节点可以调度),但是这个代码并没有覆盖所有kube-scheduler逻辑,而且即使实现了全部scheduler逻辑,用户自定义的scheduler逻辑和修改kube-scheduler配置,descheduler都无法感知到这些逻辑(目前nodeFit不能配置启用功能项、不能扩展)。比如在highNodeUtilization文档里要求跟kube-scheduler的MostAllocated打分策略一起使用。
关于nodeFit扩展问题有这些相关issue:
- NodeFit Specification
- Consider implementing pod (anti)affinity checks in NodeFit
- The getTargetNodes in RemoveDuplicates does not respect node resources and can mistakenly evict pods
- nodeFit doesn’t handle preferredDuringSchedulingIgnoredDuringExecution (RemovePodsViolatingNodeAffinity)
- NodeFit logic is incompatible with “includeSoftConstraints” option.
- NodeFit doesn’t skip checking of resources which are configured as ignoredByScheduler
- nodeFit = false doesn’t work as expected with RemovePodsViolatingNodeAffinity
还有一个问题就是执行驱逐pod后,多个新生pod又集中在部分节点(对于lowNodeUtilization插件),这个可能会导致死循环(pod被驱逐–>pod生成–>pod调度–>pod被驱逐)。
如果在驱逐pod时刻,同时有非驱逐导致(比如扩容)新生的pod占用了目标节点的资源,可能出现“新生成的pod”没有节点可以调度现象。这是因为descheduler是读取完所有节点信息之后再做决策(节点信息是固定的,而实际上是动态变化的),即descheduler基于过时的节点信息,进行驱逐pod。koordinator的descheduler解决了这个问题。
对于想下线节点的需求,利用highNodeUtilization插件将pod集中在部分节点,然后空闲节点下线。这个需求在集群中没有高利用率节点的情况下是实现不了的,社区里的有这个issue “HighNodeUtilization does nothing when all nodes are underutilized”。
需要注意对于workload副本数为1的pod也会执行驱逐,可以设置PodDisruptionBudget避免这种情况发生。相关issue “descheduler when ReplicaSet=1”
对于增加插件和自定义filter,需要将代码放在对descheduler项目里(in tree),而且缺少一些扩展点,比如无法对节点的pod排序算法进行扩展(issue Introduce sort and preEvictionSort extension points)。所以社区正在实现调度器框架,以解决这些需要侵入代码进行扩展情况,Descheduler Framework Proposal。但是目前进展缓慢,Descheduling framework wrap up。
6 总结
highNodeUtilization和lowNodeUtilization插件,通过request来计算节点的利用率,目标都是平衡节点的利用率。highNodeUtilization让节点尽量在高利用率,而lowNodeUtilization让节点尽量在低利用率。
由于使用request统计资源使用,导致lowNodeUtilization插件无法解决节点cpu过热的问题。解决cpu过热的问题,可以通过基于节点真实负载进行调度和descheduler一起使用,平衡节点资源使用。节点真实负载的调度器或插件有 Trimaran、crane、koordinator。基于真实负载的反调度器koordinator load-aware-descheduling,它同时利用koord-scheduler调度器的资源预留机制,保证驱逐后pod有节点可以调度。
descheduler目前存在策略不能满足各种各样的需求,而且扩展这些策略需要侵入式的修改代码等问题,社区正在实现调度器框架来解决这些问题。


![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)