为什么kubelet日志出现an error occurred when try to find container
大概4个月前在排查cni插件bug导致pod移除失败问题时,梳理了一下kubernetes 1.23版本pod的删除流程。在kubelet日志里遇到经常看到的报错"an error occurred when try to find container",以前看到这样的错误直接忽略,这次下定决心分析一下这个报错的原因。
这篇文章会从这几个方面进行剖析
- 介绍在kubelet里pod生命周期管理的几个核心组件
- 实际pod移除过程分析–根据Pod在kuebelet中移除过程输出的日志进行分析
在开始之前,如果你问我这个报错严重么,会有什么影响? 我的回答是无所谓这是由于异步和缓存信息不一致导致的问题,不影响pod删除和清理的流程的执行。 要是你想知道原因继续往下看,不想知道原因可以直接关闭这篇文章,因为这篇文章很长,不适合排查故障时候阅读。
pod移除流程系列文章
- 深入探索Kubernetes中的mirror Pod删除过程及其对static Pod 的影响
- 深度解析Static Pod在kubelet中的移除流程
- Kubelet Bug:sandbox残留问题 - 探寻sandbox无法被清理的根源
这里只分析pod移除过程中遇到的"an error occurred when try to find container"错误,其他情况遇到这个错误,原因可能不一样。 环境:kubelet版本为1.23.10 日志级别为4
1 日志报错样例
PLEG执行两次删除导致
E0731 17:20:16.176440 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": not found" containerID="248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a"
I0731 17:20:16.176478 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a} err="failed to get container status \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": rpc error: code = NotFound desc = an error occurred when try to find container \"248fef457ea64c3bffe8f2371626a5a96c14f148f768d947d9b3057c17e89e7a\": not found"housekeeping重新生成podworker执行移除报错
E0731 17:16:43.822332 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"cb2bbdc9ae26e1385e012072a4e0208d91fc027ae1af89cf1432ff3173014d32\": not found" containerID="cb2bbdc9ae26e1385e012072a4e0208d91fc027ae1af89cf1432ff3173014d32"2 kubelet中影响pod删除的组件
kubelet会启动一个goroutine用来执行pod生命周期管理,它从podConfig中获取pod的最新状态,控制pod的创建删除的执行、pod的健康检测管理。
这个goroutine执行的是(*Kubelet).syncLoop这个方法,它包含podConfig、sync、housekeeping、pleg、livenessManager、readinessManager、startupManager这几个select分支。
podWorkers:所有对pod的操作都通过podWorker来执行,podWorker控制pod生成和销毁的执行,维护了podWorker的各种状态和以及状态转换需要执行逻辑。每个pod对应一个podWorker,它有一个单独的goroutine执行podWorkerLoop,当收到消息通知时,会根据当前的状态,执行不同的逻辑。
- 当podWorker处于syncPod状态,则执行syncPod(执行创建pod和更新pod status)。
- 当podWorker处于terminating状态,则执行syncTerminatingPod(执行停止pod的容器),然后将状态转成terminated。
- 当podWorker处于terminated状态,则执行syncTerminatedPod(更新pod status和等待volume卸载和pod的cgroup目录的移除),然后状态转成finished。
- 当podWokre处于finished状态,不执行任何事情。等待housekeeping执行podWorker回收删除。
podConfig:汇聚apiserver、file、http渠道提供的pod,可以访问之前文章kubelet podConfig–提供kubelet运行pod)。syncLoop收到podConfig发出的ADD、UPDATE、DELETE、RECONCILE、REMOVE类型的事件,根据不同的事件会采取相应的action。
- ADD事件:发送SyncPodCreate类型的事件,通知podWorker执行podWorkerLoop逻辑,执行syncPod(执行创建pod和更新pod status)。
- UPDATE事件:发送SyncPodUpdate类型事件,通知podWorker执行podWorkerLoop逻辑,执行syncPod(调谐pod是否达到期望的状态,并更新pod status)。
- DELETE事件:发送SyncPodUpdate类型事件,通知podWorker执行podWorkerLoop逻辑,执行syncTerminatingPod(执行停止pod的容器)和syncTerminatedPod(更新pod status和等待volume卸载和pod的cgroup目录的移除)。
- REMOVE事件:发送SyncPodKill类型的事件,通知podWorker执行podWorkerLoop逻辑,如果podWorker处于finished状态不执行任何事情,否则执行syncTerminatingPod。
- RECONCILE:如果pod status里有ReadinessGates的condition,则发送SyncPodSync类型事件,通知podWorker执行podWorkerLoop逻辑,执行syncPod(调谐pod是否达到期望的状态,并更新pod status)。如果pod被evicted,则移除pod里的所有退出容器。
sync:每一秒执行一次,让podWorkers中已经执行完成(包括已经完成或执行出错)的podWorker重新执行。
housekeeping:进行一些清理工作,比如不存在pod的podWorker的移除,停止和删除已经终止的pod的probe worker,移除已经删除但是还在运行的pod的container(通知podWorker执行terminaing且优雅停止时间为1),清理不存在的pod的cgroup目录,移除不存在pod的volume和pod目录,删除mirror pod(对应的static pod不存在)等。
pleg:监听pod的容器的各种事件(容器启动、删除、停止等事件)。当有容器的启动、停止事件,通知容器对应的pod的podWorker重新执行。容器的停止事件,还会通知podContainerDeletor执行退出容器的清理。
podContainerDeletor:它启动一个goroutine接收通知来执行container的移除任务。
livenessManager、readinessManager、startupManager这几个不影响pod删除的行为,这里忽略不做介绍。
garbageCollector:单独的一个goroutine每一分钟执行一次,包括镜像清理和退出容器(包括sandbox)的清理。
statusManager:负责周期性的更新pod status,并在pod处于terminated状态且cgroup不存在和volume已经umount时候,执行最终的删除(将pod的DeletionGracePeriodSeconds设置为0)
syncLoop就像一个餐馆,菜相当于pod,podConfig提供客户订单,sync负责上菜进度管理(对慢的菜品进行催促),housekeeping进行餐桌收拾清理,pleg响应加水、结账等客户需求,livenessManager、readinessManager、startupManager对菜进行检查(不好的进行重做)。
而podWorkers就餐厅里的厨师和服务员,负责菜品的制作和收拾餐具和处理剩余食物。
garbageCollector就像垃圾清理站,清理厨余垃圾。
3 pod移除过程分析
上面概念介绍完了,下面通过pod删除过程中kubelet输出的日志来分析pod删除流程。这里只是其中一种删除流程,由于存在异步和缓存和select随机等原因,实际上还有很多流程。
完整的日志在 kubelet log and watch pod output
首先podConfig接收到pod被删除事件(pod的DeletionTimestamp不为nil和DeletionGracePeriodSeconds不为0)
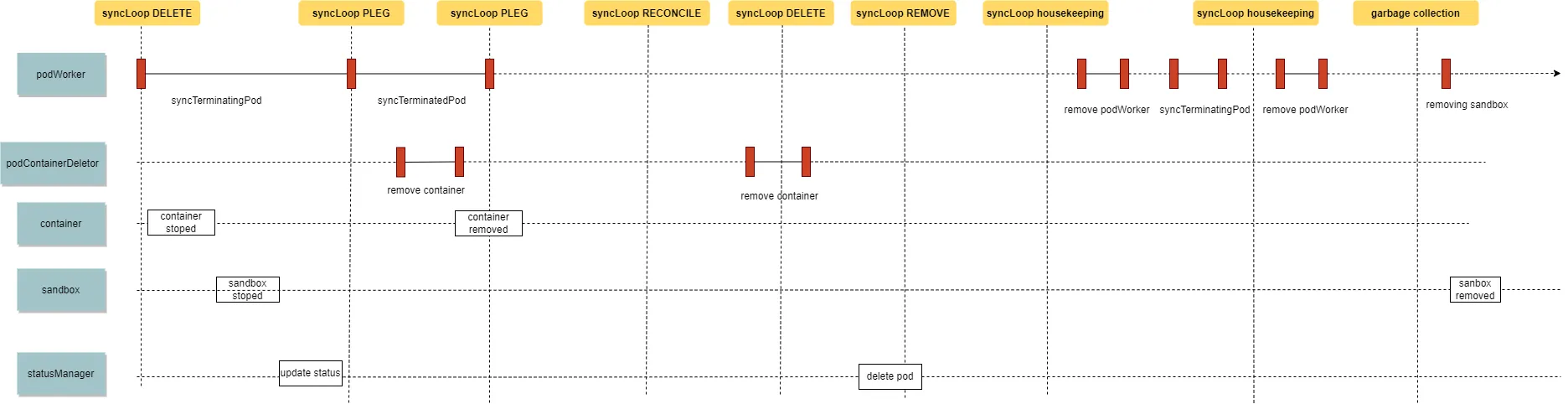
I0731 17:16:31.865371 354472 kubelet.go:2130] "SyncLoop DELETE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]podWorker执行停止pod的容器和sandbox
I0731 17:16:31.865402 354472 pod_workers.go:625] "Pod is marked for graceful deletion, begin teardown" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:31.865427 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1
I0731 17:16:31.865457 354472 pod_workers.go:1005] "Pod worker has observed request to terminate" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:31.865468 354472 kubelet.go:1795] "syncTerminatingPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
.......
I0731 17:16:32.257408 354472 kubelet.go:1873] "Pod termination stopped all running containers" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257421 354472 kubelet.go:1875] "syncTerminatingPod exit" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257432 354472 pod_workers.go:1050] "Pod terminated all containers successfully" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.257468 354472 pod_workers.go:988] "Processing pod event done" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1podWorker执行terminated pod
I0731 17:16:32.257476 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=2
......
I0731 17:16:32.372412 354472 kubelet.go:1883] "syncTerminatedPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
.....
I0731 17:16:32.372533 354472 volume_manager.go:446] "Waiting for volumes to unmount for pod" pod="default/test-nginx-976fbbd77-m2tqs"
I0731 17:16:32.372851 354472 volume_manager.go:473] "All volumes are unmounted for pod" pod="default/test-nginx-976fbbd77-m2tqs"
I0731 17:16:32.372863 354472 kubelet.go:1896] "Pod termination unmounted volumes"
.....
I0731 17:16:32.380794 354472 kubelet.go:1917] "Pod termination removed cgroups" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.380871 354472 kubelet.go:1922] "Pod is terminated and will need no more status updates" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:32.380883 354472 kubelet.go:1924] "syncTerminatedPod exit" container和sanbox退出触发PLEG,并执行两次移除container
I0731 17:16:32.372899 354472 kubelet.go:2152] "SyncLoop (PLEG): event for pod" pod="default/test-nginx-976fbbd77-m2tqs" event=&{ID:5011243d-6324-41e3-8ee8-9e8bb33f04b0 Type:ContainerDied Data:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e}
I0731 17:16:32.372929 354472 kubelet.go:2152] "SyncLoop (PLEG): event for pod" pod="default/test-nginx-976fbbd77-m2tqs" event=&{ID:5011243d-6324-41e3-8ee8-9e8bb33f04b0 Type:ContainerDied Data:ae68335cc5733a4c2fc5c15baed083f94a2d05a6b360b1045c9b673e119f8538}
I0731 17:16:32.372946 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393287 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393300 354472 scope.go:110] "RemoveContainer" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
E0731 17:16:32.398137 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.398175 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e} err="failed to get container status \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found"podConfig再次接收到pod被删除(由kubelet里的statusManager执行删除,DeletionGracePeriodSeconds设置为0),这次由于podWorker是finished状态,没有触发podWorker执行
I0731 17:16:32.394625 354472 kubelet.go:2130] "SyncLoop DELETE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]
I0731 17:16:32.394654 354472 pod_workers.go:611] "Pod is finished processing, no further updates" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0podConfig感知到pod从apiserver中的移除
I0731 17:16:32.398009 354472 kubelet.go:2124] "SyncLoop REMOVE" source="api" pods=[default/test-nginx-976fbbd77-m2tqs]
I0731 17:16:32.398032 354472 kubelet.go:1969] "Pod has been deleted and must be killed" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0housekeeping执行移除podWorker和再次创建podWorker,执行terminating pod
I0731 17:16:33.810883 354472 kubelet.go:2202] "SyncLoop (housekeeping)"
I0731 17:16:33.820842 354472 kubelet_pods.go:1082] "Clean up pod workers for terminated pods"
I0731 17:16:33.820869 354472 pod_workers.go:1258] "Pod has been terminated and is no longer known to the kubelet, remove all history" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
......
I0731 17:16:33.820908 354472 kubelet_pods.go:1134] "Clean up orphaned pod containers" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.820927 354472 pod_workers.go:571] "Pod is being synced for the first time" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.820938 354472 pod_workers.go:620] "Pod is orphaned and must be torn down" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
0731 17:16:33.821092 354472 pod_workers.go:888] "Processing pod event" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1
I0731 17:16:33.821127 354472 pod_workers.go:1005] "Pod worker has observed request to terminate" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
........
I0731 17:16:33.821138 354472 kubelet.go:1795] "syncTerminatingPod enter" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.821149 354472 kubelet.go:1804] "Pod terminating with grace period" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 gracePeriod=1
I0731 17:16:33.821198 354472 kuberuntime_container.go:719] "Killing container with a grace period override" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e" gracePeriod=1
I0731 17:16:33.821212 354472 kuberuntime_container.go:723] "Killing container with a grace period" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e" gracePeriod=1
I0731 17:16:33.821305 354472 event.go:294] "Event occurred" object="default/test-nginx-976fbbd77-m2tqs" kind="Pod" apiVersion="v1" type="Normal" reason="Killing" message="Stopping container nginx"
E0731 17:16:33.822425 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:33.822479 354472 kuberuntime_container.go:732] "Container exited normally" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 containerName="nginx" containerID="containerd://c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
.......
I0731 17:16:33.892542 354472 kubelet.go:1815] "syncTerminatingPod exit" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.892552 354472 pod_workers.go:1081] "Pod terminated all orphaned containers successfully and worker can now stop" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:33.892567 354472 pod_workers.go:969] "Processing pod event done" pod="default/test-nginx-976fbbd77-m2tqs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0 updateType=1housekeeping再次触发,移除podWorker
I0731 17:16:35.810945 354472 kubelet.go:2202] "SyncLoop (housekeeping)"
I0731 17:16:35.820522 354472 kubelet_pods.go:1082] "Clean up pod workers for terminated pods"
I0731 17:16:35.820564 354472 pod_workers.go:1258] "Pod has been terminated and is no longer known to the kubelet, remove all history" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0garbageCollector执行移除sandbox和pod日志目录
I0731 17:16:51.742500 354472 kuberuntime_gc.go:171] "Removing sandbox" sandboxID="ae68335cc5733a4c2fc5c15baed083f94a2d05a6b360b1045c9b673e119f8538"
I0731 17:16:51.954568 354472 kuberuntime_gc.go:343] "Removing pod logs" podUID=5011243d-6324-41e3-8ee8-9e8bb33f04b0
I0731 17:16:51.955194 354472 kubelet.go:1333] "Container garbage collection succeeded"根据上面的分析,总结一下这个例子中的pod移除过程(这里只提关键的逻辑,不等于实际pod移除逻辑,还有很多没有打日志的逻辑需要自己查阅代码)
3.1 pod的移除的处理流程
- podConfig从apiserver接收到pod被删除的事件
- podWorker收到通知执行terminating pod(停止container和sandbox、停止并移除liveness readiness startup probe),执行完成后podWorker进入terminated状态
- podWorker继续执行terminated pod(更新pod status里container status为Terminated状态、移除pod的cgroup、等待pod的volume umount完成),执行完成后podWorker进入finished状态
- PLEG感知到container的停止,执行container移除
- podConfig从apiserver接收到pod status更新
- kubelet的statusManager发起最终删除请求
- podConfig再次从apiserver接收pod到删除
- podConfig感知到pod从apiserver中消失,再次通知podWorker执行,由于podWorker已经处于finished所以不执行任何动作。
- housekeeping触发,先移除podWorker,再次创建podWorker并通知podWorker停止pod的container(通知podWorker执行terminaing优雅停止时间为1)
- housekeeping再次触发,再次移除podWorker
- garbageCollector移除sanbox和pod的日志目录
4 报错原因分析
可以看到上面有两个地方出现了"an error occurred when try to find container"
4.1 第一次出现
container和sanbox退出触发PLEG,并执行两次移除container,第二次移除container出现报错
I0731 17:16:32.393287 354472 kuberuntime_container.go:947] "Removing container" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.393300 354472 scope.go:110] "RemoveContainer" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
E0731 17:16:32.398137 354472 remote_runtime.go:597] "ContainerStatus from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"
I0731 17:16:32.398175 354472 pod_container_deletor.go:52] "DeleteContainer returned error" containerID={Type:containerd ID:c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e} err="failed to get container status \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found"4.2 原因分析
在PLEG有事件触发的时候,如果event类型是"ContainerDied"(容器退出),且pod被驱逐或"podWorker处于terminated状态",则通知podContainerDeletor移除这个pod下所有退出的容器。如果event类型是"ContainerDied"(容器退出)且pod还在运行状态,且pod里退出的容器数量超过kubelet设置保留退出容器数量,则移除这个退出容器。
由于第一次PLEG已经触发了移除container,所以第二次PLEG触发移除就没有这个container。
pkg/kubelet/pod_container_deletor.go#L46-L55
func newPodContainerDeletor(runtime kubecontainer.Runtime, containersToKeep int) *podContainerDeletor {
buffer := make(chan kubecontainer.ContainerID, containerDeletorBufferLimit)
go wait.Until(func() {
for {
id := <-buffer
if err := runtime.DeleteContainer(id); err != nil {
klog.InfoS("DeleteContainer returned error", "containerID", id, "err", err)
}
}
}, 0, wait.NeverStop)pkg/kubelet/kuberuntime/kuberuntime_container.go#L962-L973
// removeContainerLog removes the container log.
func (m *kubeGenericRuntimeManager) removeContainerLog(containerID string) error {
// Use log manager to remove rotated logs.
err := m.logManager.Clean(containerID)
if err != nil {
return err
}
status, err := m.runtimeService.ContainerStatus(containerID)
if err != nil {
return fmt.Errorf("failed to get container status %q: %v", containerID, err)
}4.3 第二次出现
在第一次housekeeping触发时候,podWorker执行停止container时候。
E0731 17:16:33.822425 354472 remote_runtime.go:479] "StopContainer from runtime service failed" err="rpc error: code = NotFound desc = an error occurred when try to find container \"c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e\": not found" containerID="c234646fffe772e4979bc11398e1b0b8612136c08030486ae1fde12238479b9e"4.4 原因分析
housekeeping执行相关部分逻辑:先执行podWorker移除,然后从缓存中获取正在运行的pod列表,如果列表里存在pod不在podWorkers里或”podWorker状态不为SyncPod或Terminating状态“,则利用podWorker机制执行停止容器。
从日志可以推断出”从缓存中获取运行的pod的列表“里包含这个pod,所以存在了不一致的现象,pod明显已经停止运行了,但是在缓存中还是运行的。因为容器已经再前面的步骤中被移除了,所以这里就会报错"not found"。
pkg/kubelet/kubelet_pods.go#L1129-L1199
workingPods := kl.podWorkers.SyncKnownPods(allPods)
allPodsByUID := make(map[types.UID]*v1.Pod)
for _, pod := range allPods {
allPodsByUID[pod.UID] = pod
}
// Identify the set of pods that have workers, which should be all pods
// from config that are not terminated, as well as any terminating pods
// that have already been removed from config. Pods that are terminating
// will be added to possiblyRunningPods, to prevent overly aggressive
// cleanup of pod cgroups.
runningPods := make(map[types.UID]sets.Empty)
possiblyRunningPods := make(map[types.UID]sets.Empty)
restartablePods := make(map[types.UID]sets.Empty)
// 对podWorkers中pod进行分类(移除了不在kl.podManager的pod)
// runningPods包含在podWorkers中处于syncPod状态的pod
// possiblyRunningPods包含在podWorkers中处于syncPod状态的pod和TerminatingPod状态的pod
// restartablePods包含在podWorkers中处于TerminatedAndRecreatedPod的pod
for uid, sync := range workingPods {
switch sync {
case SyncPod:
runningPods[uid] = struct{}{}
possiblyRunningPods[uid] = struct{}{}
case TerminatingPod:
possiblyRunningPods[uid] = struct{}{}
case TerminatedAndRecreatedPod:
restartablePods[uid] = struct{}{}
}
}
// Stop probing pods that are not running
klog.V(3).InfoS("Clean up probes for terminated pods")
// kl.probeManager.workers中的key的pod uid不在possiblyRunningPods中,则发送信号给worker.stopCh,让周期执行的probe停止并删除
kl.probeManager.CleanupPods(possiblyRunningPods)
// Terminate any pods that are observed in the runtime but not
// present in the list of known running pods from config.
// 从runtime缓存中获取running pod列表
runningRuntimePods, err := kl.runtimeCache.GetPods()
if err != nil {
klog.ErrorS(err, "Error listing containers")
return err
}
for _, runningPod := range runningRuntimePods {
switch workerState, ok := workingPods[runningPod.ID]; {
// runtime中运行的pod也在podWorker中且"在podWorker中处于SyncPod状态",或runtime中运行的pod也在podWorker中且"在podWorker中处于TerminatingPod状态"
case ok && workerState == SyncPod, ok && workerState == TerminatingPod:
// if the pod worker is already in charge of this pod, we don't need to do anything
continue
default:
// If the pod isn't in the set that should be running and isn't already terminating, terminate
// now. This termination is aggressive because all known pods should already be in a known state
// (i.e. a removed static pod should already be terminating), so these are pods that were
// orphaned due to kubelet restart or bugs. Since housekeeping blocks other config changes, we
// know that another pod wasn't started in the background so we are safe to terminate the
// unknown pods.
// runtime中运行的pod不在kl.podManager中(apiserver中),则执行kl.podWorkers.UpdatePod(UpdateType为kubetypes.SyncPodKill,让podWorker执行Terminating-->terminated)
if _, ok := allPodsByUID[runningPod.ID]; !ok {
klog.V(3).InfoS("Clean up orphaned pod containers", "podUID", runningPod.ID)
one := int64(1)
kl.podWorkers.UpdatePod(UpdatePodOptions{
UpdateType: kubetypes.SyncPodKill,
RunningPod: runningPod,
KillPodOptions: &KillPodOptions{
PodTerminationGracePeriodSecondsOverride: &one,
},
})
}
}
}

![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)