算力自由:用Tailscale将你的K8s GPU集群扩展至‘无限’

在人工智能浪潮席卷全球的今天,GPU算力是一关键生产要素。然而,一个普遍的痛点是:GPU资源既稀缺又昂贵。
以主流云厂商为例,不仅GPU实例常常“一卡难求”,其价格也令人望而却步。我们来看一组直观的对比:
- Google Cloud (GCP): 一块 H100 GPU 的价格高达 $11/小时。
- RunPod: 同等算力价格仅为 $3/小时。
- Hyperstack / Voltage Park: 价格更是低至 $1.9/小时。
差价高达数倍!这引出了一个核心问题:
我们能否设计一种方案,既能享受到第三方提供商的低成本GPU,又能复用云厂商成熟、弹性的基础设施(如托管K8s、对象存储、负载均衡等)?
答案是肯定的。本文将详细介绍一种基于 Tailscale 和 Kubernetes 的混合云方案,经济高效地构建和扩展AI基础设施。
1 方案总览:构建跨网络的统一K8s集群
核心思路是:将 Kubernetes 作为统一的AI基础设施底座,并利用VPN技术将分散在各处的廉价GPU节点,无缝地“并入”到云上的主K8s集群中。
这样,外部GPU节点就如同云上的普通Worker节点一样,可以由统一的控制面进行调度和管理。架构示意图如下:
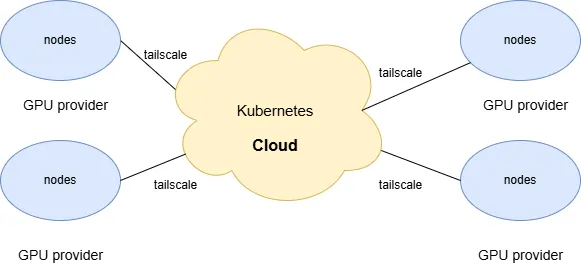
在这个架构中,无论节点身处GCP、AWS,还是RunPod的数据中心,它们都在一个逻辑上的大内网中,网络互通,为上层应用提供了透明的算力资源池。
1.1 方案选型与思考
在动手前,你可能会想:
1.1.1 1. 为何不采用多集群(Multi-Cluster)方案?
为每个GPU提供商单独搭建一个Kubernetes集群,再通过多集群管理工具(如 Karmada, Clusterlink)进行互联,这是一种常见的思路。但对于这个场景,它存在以下弊端:
- 资源浪费:每个独立的K8s集群都需要额外的控制面(Control Plane)和各类管理组件,这会消耗宝贵的CPU和内存资源。
- 管理开销:GPU提供商的节点数量通常较少(可能只有几个到十几个),为其维护一套完整的集群,投入产出比不高。
1.1.2 2. 为何不选择 K3s?
K3s 是一个优秀的轻量级Kubernetes发行版,非常适合边缘计算场景。但在此处,我们并未采用,原因如下:
- 资源并非瓶颈:这个场景中,无论是云端节点还是GPU节点,硬件性能都相当强劲,并不追求K3s极致的低资源开销。
- 网络复杂性:K3s为了简化部署,自带了网络方案。但在跨云、跨数据中心场景下,直接使用更底层的网络打通方案(如Tailscale)比在K3s之上再做一层网络配置要更加直接和可控。
1.2 如何解决跨网络互联问题?
最直接的办法,就是让两个网络之间建立VPN连接,让所有节点感觉就像在同一个局域网里。
Tailscale 就是一个能简单、低成本实现这个目标的利器。它是一个基于开源协议 WireGuard® 构建的VPN服务,可以轻松地将不同网络中的设备连接成一个Mesh网络,设备互访就像在内网一样方便。
它最大的好处是大大降低了WireGuard的使用门槛,无需复杂的配置,还提供了NAT穿透、网络ACL等高级功能。更棒的是,它的个人免费套餐支持100个设备,对于绝大多数中小型企业和个人开发者来说,完全够用。
2 架构方案
这里我们利用Tailscale的subnet router功能,让Tailscale相当于路由器,在Tailscale网络中能对宣告的subnet进行路由。
2.1 直连
为了减少Tailscale之间的网络延迟,我们希望Tailscale设备之间的连接是直连,而不是通过中继服务器。
在kubernetes中直连需要的条件:
- 运行Tailscale节点需要有公网ip
- Tailscale运行在host网络模式下
- 同时开放udp 41641(Tailscale之间的通信端口)的入向访问
- 开放 出向tcp 80、443的访问
2.2 不使用Tailscale operator
Tailscale针对kubernetes场景开发了Tailscale operator简化Tailscale的部署和管理,但是它的设计场景比较少,比如集群外访问集群内service,集群内访问集群外的服务,本地连入kubernetes网络等。对于我们的需求场景它都不符合。
而Tailscale operator的subnet router功能也不符合我们需求
- 它生成的subnet connector的实例是只有一个副本的statefulset的pod,并且不能修改
- 它的网络模式是pod网络,并且不能修改
它不符合我们高可用的要求,部署多个实例、而且需要host网络。
2.3 其他要求
- 所有区域节点的子网IP(Node CIDR)和Pod的子网IP(Pod CIDR)不能有重叠。
- 不同的子网区域可以使用不同的cni,只要保证不同区域的pod网络能够互通
- 所有运行Tailscale 客户端节点的系统必须是linux
2.4 方案一:节点粒度连接(Per-Node Subnet Router)
- 每个node分配一个Pod的子网(Pod CIDR)
- 每个节点都运行一个Tailscale客户端,并宣告自己节点上的Pod子网。
- 不同区域node子网的间的通信,需要每个区域运行tailscale客户端来宣告这个区域节点子网。这个tailscale客户端可以单独部署也可以复用已有tailscale客户端。
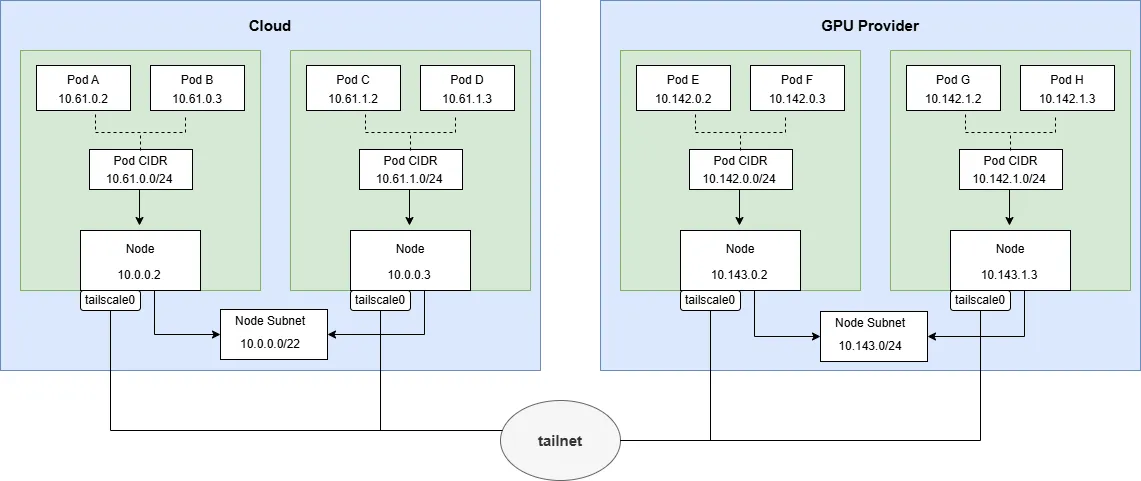
优点:
- 故障隔离性好:爆炸面比较小,一个节点的tailscale挂掉,只影响该节点上的pod通信,不会影响其他节点的上pod的网络通信。
缺点:
- 网络开销大:跨节点的pod之间的通信需要通过tailscale,增加了网络开销。
- 设备数量限制:tailscale设备数量随着节点的数量增加而增加,容易超过tailscale免费版100个限制。
这个方案跟K3s集成的Tailscale方案类似。
2.5 方案二:区域网关连接(Regional Subnet Gateway)
- 在每个网络区域(如一个VPC或一个数据中心)内部署一个或多个(作为高可用的failover)的Tailscale实例,作为该区域的子网路由器(Subnet Router)。宣告这个区域的节点子网和pod子网。
- 需要在节点或网关上配置访问其他区域的pod子网和节点子网路由,它的下一跳是运行tailscale的节点。为了高可用,可以配置多条等价路由。
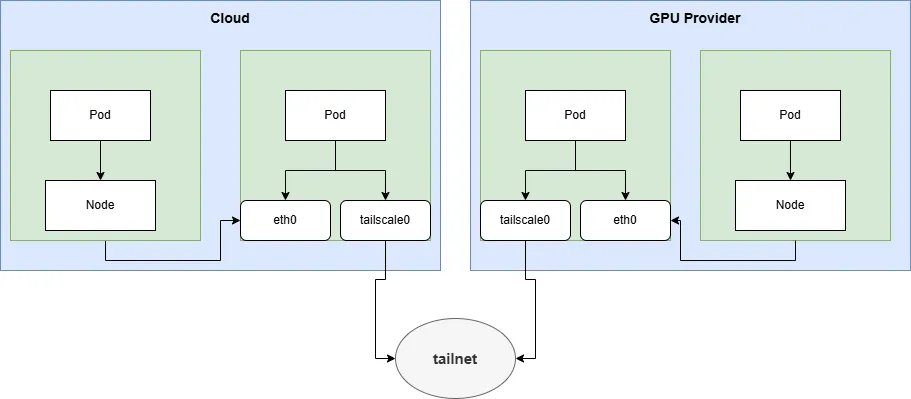
优点:
- 网络性能高:只有跨区域的流量才会经过Tailscale网关,区域内的流量直接走底层网络,性能接近原生。
- 配置简单,设备数少:每个区域只需部署少量网关实例,极大地节省了Tailscale设备配额。
缺点:
- 故障影响面大:如果一个网关实例宕机,整个区域的跨网通信都会中断。虽然可以通过部署多个实例实现高可用,但故障切换(Failover)通常需要约15秒的时间。
我的选择:
综合考虑配置复杂度、网络性能和扩展性,我最终选择方案二。它更符合生产环境中对性能和可维护性的要求。
2.6 实战演练:分步指南
下面,将一步步搭建方案二。本文使用的软件版本为:
- Tailscale: v1.84.3
- Kubernetes: v1.33.1
- Cilium: v1.17.4
2.6.1 1.生成 Tailscale OAuth 客户端
点击"Generate OAuth client",在弹出窗口中,在 Keys 栏中,给 OAuth Keys 勾选 Write 权限。
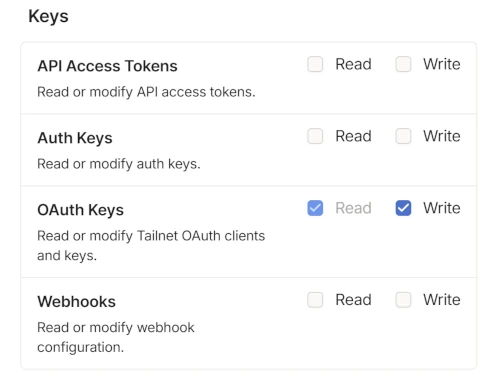
generate-oauth-client 点击"Generate client",然后立即保存好生成的Client Secret,这个窗口关了就找不回来了!
generated-oauth-client
2.6.2 2. 配置Tailscale ACL
- 访问Tailscale ACL配置页面
- 在JSON配置中,添加 tagOwners 和 autoApprovers 字段。定义一个 tag:k8s,并允许拥有此标签的设备自动宣告我们规划好的子网。
"tagOwners": {
"tag:k8s": [],
},
"autoApprovers": {
"routes": {
# pod cidr 1
"10.61.0.0/16": ["tag:k8s"],
# node cidr 1
"10.0.0.0/22": ["tag:k8s"],
# pod cidr 2
"10.142.0.0/20": ["tag:k8s"],
# node cidr 2
"10.143.0.0/24": ["tag:k8s"],
},
}2.6.3 3. 在云端区域部署Tailscale网关 (DaemonSet)
在云端(控制节点所在)区域中选择几个节点(设置lable为tailscale: “true”)作为网关,用DaemonSet部署Tailscale。
这样会生成临时节点,且key永不过期,且tag为tag:k8s
apiVersion: v1
kind: Secret
metadata:
name: tailscale-oauth
namespace: tailscale
stringData:
TS_AUTHKEY: tskey-client-abcd-edfgh # replace to your client Secret
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: tailscale
namespace: tailscale
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: tailscale
namespace: tailscale
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["secrets"]
# Create can not be restricted to a resource name.
verbs: ["create"]
- apiGroups: [""] # "" indicates the core API group
resources: ["secrets"]
verbs: ["get", "update", "patch"]
- apiGroups: [""] # "" indicates the core API group
resources: ["events"]
verbs: ["get", "create", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: tailscale
namespace: tailscale
subjects:
- kind: ServiceAccount
name: "tailscale"
roleRef:
kind: Role
name: tailscale
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: subnet-router
namespace: tailscale
labels:
app: tailscale
spec:
selector:
matchLabels:
app: tailscale
template:
metadata:
labels:
app: tailscale
spec:
tolerations:
- key: node.kubernetes.io/not-ready
effect: NoSchedule
- key: node-role.kubernetes.io/master
effect: NoSchedule
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
nodeSelector:
tailscale: "true"
serviceAccountName: "tailscale"
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: tailscale
imagePullPolicy: IfNotPresent
image: "ghcr.io/tailscale/tailscale:v1.84.3"
command:
- /bin/sh
- -c
# Set environment variable TS_KUBE_SECRET to the name of the k8s secret
# that will store the Tailscale state.
- TS_KUBE_SECRET=tailscale-$(HOST_IP) /usr/local/bin/containerboot
env:
- name: TS_USERSPACE
value: "false"
- name: TS_DEBUG_FIREWALL_MODE
value: auto
- name: TS_AUTHKEY
valueFrom:
secretKeyRef:
name: tailscale-oauth
key: TS_AUTHKEY
optional: true
# advertise the routes for the node subnet and the pod subnet
- name: TS_ROUTES
value: "10.61.0.0/16,10.0.0.0/22"
# set tags for the node and accept routes and disable SNAT for the subnet routes
- name: TS_EXTRA_ARGS
value: "--advertise-tags=tag:k8s --snat-subnet-routes=false --accept-routes"
- name: PORT
value: "41641"
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_UID
valueFrom:
fieldRef:
fieldPath: metadata.uid
- name: HOST_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
# - name: HOST_NAME
# valueFrom:
# fieldRef:
# fieldPath: spec.nodeName
securityContext:
privileged: true这里配置的关键点:
nodeSelector:确保DaemonSet只在打了tailscale-router: “true"标签的节点上运行,这些节点通常是具有公网IP的边缘节点。
hostNetwork: true: 必须使用主机网络模式,这样tailscale之间能够直连
PORT:设置tailscale监听的端口,用于tailscale之间连接
TS_KUBE_SECRET:将Tailscale的状态(如设备密钥和设备ID)持久化到Kubernetes Secret中,避免Pod重启后身份丢失。我这里设置为tailscale-$(HOST_IP)
TS_ROUTES:此网关负责的子网范围,多个子网用逗号分隔
TS_EXTRA_ARGS:用于设置额外的命令行参数
- –advertise-tags=tag:k8s: 设置节点的tag
- –snat-subnet-routes=false: 对于通过它访问tailnet网络的ip不启用SNAT,至关重要。这样目标Pod看到的源IP就是发起请求的真实Pod IP,而不是网关的IP。这对网络策略和日志审计至关重要。
- –accept-routes: 接受来自其他Tailscale节点的路由宣告,并自动在节点上配置路由。
2.6.4 4. 在外部GPU节点部署Tailscale (Static Pod)
外部GPU节点在加入集群需要连上apiserver,连接apiserver必须通过Tailscale网络,这就有“鸡和蛋”的问题。为了解决这个“鸡生蛋,蛋生鸡”的问题,我们使用**静态Pod(Static Pod)**来启动第一个网关。
# This is to solve the problem of external node connection to apiserver
apiVersion: v1
kind: Pod
metadata:
name: apiserver-connector
namespace: tailscale
labels:
app: apiserver-connector
spec:
hostNetwork: true
containers:
- name: tailscale
imagePullPolicy: IfNotPresent
image: "ghcr.io/tailscale/tailscale:v1.84.3"
env:
- name: TS_USERSPACE
value: "false"
- name: TS_DEBUG_FIREWALL_MODE
value: auto
- name: TS_AUTHKEY
value: tskey-client-abcd-edfgh # replace to your client Secret
# advertise the routes for the node subnet and the pod subnet
- name: TS_ROUTES
value: "10.142.0.0/20, 10.143.0.0/24"
- name: TS_EXTRA_ARGS
value: "--advertise-tags=tag:k8s --snat-subnet-routes=false --accept-routes"
- name: PORT
value: "41641"
# When running on Kubernetes, containerboot defaults to storing state in the
# "tailscale" kube secret. To store state on local disk instead, set
# TS_KUBE_SECRET="" and TS_STATE_DIR=/path/to/storage/dir. The state dir should
# be persistent storage.
# to avoid chicken and egg problem, we need to store to host path
- name: TS_STATE_DIR
value: /var/lib/tailscale
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_UID
valueFrom:
fieldRef:
fieldPath: metadata.uid
securityContext:
privileged: true
volumeMounts:
- name: tailscale-state
mountPath: /var/lib/tailscale
volumes:
- name: tailscale-state
hostPath: /data/tailscale-state这里配置关键点:
- 这里TS_AUTHKEY直接设置value,而不是从secret获取,所以不需要连接apiserver。
- 设置TS_STATE_DIR,将状态持久化到节点本地磁盘(而不保存在secret里),同样是为了摆脱对ApiServer的依赖。
2.6.5 5. 配置 MSS Clamping
WireGuard会为数据包增加额外的头部,这可能导致数据包大小超过MTU(最大传输单元),从而造成网络问题,特别是对于TCP连接。我们需要在所有Tailscale网关节点上设置MSS Clamping。
iptables -t mangle -A FORWARD -o tailscale0 -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu3 踩的坑
但是不要高兴太早,还有很多坑等着你踩。说说我踩过的坑:
3.1 坑1:Kubernetes多网卡与Cilium网络策略
由于tailscale会在节点上创建tailscale0网卡并配置CGNAT 100.64.0.0/10网段的ip,这个网卡负责跨区域的网络访问。
但K8s和Cilium不认这个网卡上的IP,在Node的status.addresses里不包含这个网卡的ip,而且CiliumNode里spec.addresses也不会包含这个网卡的ip。
在CiliumNetworkPolicy中这个ip不属于"remote-node"这个Entities中。
问题表现:在启用CiliumNetworkPolicy规则–只允许”node“和"remote-node"的ingress流量。在运行tailscale的节点上访问跨区域的node或pod,由于源IP(来自tailscale0网卡)不被Cilium识别为合法的remote-node,流量会被策略拒绝。
相关Issue:具体请看cilium/cilium#40192
3.2 坑2:Tailscale与Calico、Cilium的fwmark冲突
Tailscale和Calico/Cilium都用了fwmark来标记数据包,而且不幸的是,它们用了相同的标记值,这会导致莫名其妙的网络异常。
Calico冲突:tailscale使用fmark 0x80000来标记自身产生的流量,使用0x40000来标记来自网卡的流量,而calico也使用同样的fmark。具体请看tailscale/tailscale#591。
Cilium冲突:从tailscale的1.58.2版本开始,tailscale使用nftable模式下,它会使用0x400来标记来自网卡的流量。而cilium会用0x400来标记overlay网络的流量。具体请看tailscale/tailscale#11803 cilium/cilium#36104
3.3 坑3:Tailscale 默认网段冲突
tailscale默认使用100.64.0.0/10,但是一些公有云(比如阿里云)也使用这些地址,这个就会导致网络冲突。
虽然可以使用IP Pool功能来指定tailnet的网络范围,但是tailscale还是会使用内部保留网段:
100.100.0.0/24
100.100.100.0/24
100.115.92.0/23同时即使你使用IP Pool手动指定网段,但是它在nftable/iptables中写死了100.64.0.0/10网段,具体请看 tailscale/tailscale#12828
4 总结
通过采用Kubernetes + Tailscale的组合,该方案不仅大幅降低了AI模型训练和推理的成本,还保持了云原生架构的弹性和统一管理能力。但是这个方案也面临一些挑战,比如何跨区域使用存储资源、跨区域的ingress的流量调度。
Tailscale对kubernetes支持还不够成熟、目前只是可用。Tailscale operator适用的场景比较少,还存在很多问题,目前beta状态。
5 Reference
https://tailscale.com/kb/1185/kubernetes
https://tailscale.com/blog/kubernetes-direct-connections
https://tailscale.com/kb/1015/100.x-addresses
https://tailscale.com/kb/1381/what-is-quad100
https://tailscale.com/kb/1304/ip-pool
https://tailscale.com/kb/1215/oauth-clients#registering-new-nodes-using-oauth-credentials
https://tailscale.com/kb/1019/subnets
https://tailscale.com/kb/1214/site-to-site#configure-the-subnet-router
https://tailscale.com/kb/1115/high-availability#subnet-router-high-availability
https://tailscale.com/blog/docker-tailscale-guide
https://tailscale.com/kb/1282/docker
https://tailscale.com/kb/1337/policy-syntax#autoapprovers
https://tailscale.com/kb/1028/key-expiry
https://tailscale.com/kb/1085/auth-keys
https://tailscale.com/kb/1080/cli
https://tailscale.com/kb/1278/tailscaled#flags-to-tailscaled
https://tailscale.com/kb/1411/device-connectivity
https://tailscale.com/blog/how-nat-traversal-works
https://tailscale.com/kb/1257/connection-types
https://tailscale.com/kb/1082/firewall-ports
https://tailscale.com/kb/1181/firewalls
https://tailscale.com/learn/managing-access-to-kubernetes-with-tailscale#subnet-router-deployments
https://tailscale.com/kb/1018/acls
https://tailscale.com/kb/1081/magicdns
https://tailscale.com/kb/1236/kubernetes-operator
https://github.com/tailscale/tailscale/blob/main/k8s-operator/api.md#container

![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)