Koordinator Descheduler的MigrationController插件:确保驱逐后Pod成功调度
由于调度器和descheduler是两个独立工作的组件,两个组件之间并没有任何通讯和协商机制,在descheduler执行pod驱逐后,由驱逐生成pod的调度和非驱逐原因生成的pod的调度(后面简称正常的pod)会存在资源抢占的问题。比如正常的pod和驱逐后生成的新pod需要相同的资源,且集群的剩余可以调度的资源紧张(或者资源碎片),且正常的pod在驱逐后生成的新pod之前调度,会出现pod驱逐后新生成的pod重新调度到原先的节点或无法调度的问题。
MigrationController插件通过Reservation资源跟koordinator scheduler进行通信,让koordinator scheduler进行资源预留,然后再执行驱逐pod,来解决上面这个问题。
仲裁机制是一种干预pod的驱逐过程的机制,它在 v1.4.0 版本中引入。它解决了应用变更维护过程中临时暂停应用pod的驱逐,比如deployment滚动更新的过程中同时descheduler执行pod的驱逐,会对这个应用的稳定性产生影响,甚至没有一个ready的pod。仲裁机制提供了一个方式,在驱逐pod时候增加一道审批的流程,能够进行批准、拒绝等操作。
1 MigrationController插件
koordinator descheduler里的MigrationController插件,它实现了filter和evict插件的扩展点。它包含了资源保留和仲裁机制的功能。
名词说明:
Reservation:koordinator自定义资源,启用资源预留之后,每个被驱逐的pod关联一个reservation。用于koordinator-scheduler跟踪资源预留的状态,同时koordinator-descheduler根据这个reservation更新PodMigrationJob状态。
PodMigrationJob:koordinator自定义资源,每次MigrationController执行驱逐pod都会为这个pod创建一个PodMigrationJob。它用于跟踪pod的驱逐状态。
arbitrator:MigrationController插件内部的一个模块,负责对pod驱逐进行过滤,决定这个pod是否执行驱逐。
1.1 如何启用MigrationController插件
在koordinator-descheduler的配置文件里,分别在profiles[*].plugins.evict和profiles[*].plugins.pluginConfig添加下面配置
profiles:
- name: koord-descheduler
plugins:
........
evict:
disabled:
- name: "*"
enabled:
- name: MigrationController
pluginConfig:
- name: MigrationController
args: 1.2 如何启用资源保留功能
资源保留功能默认开启,即在MigrationController插件配置中设置defaultJobMode: ReservationFirst。
pluginConfig:
- name: MigrationController
args:
defaultJobMode: ReservationFirst对于手动创建PodMigrationJob,默认启用资源保留功能。
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: PodMigrationJob
metadata:
name: migrationjob-demo
spec:
mode: ReservationFirst当然你也可以关闭资源保留功能,在MigrationController插件中配置defaultJobMode: EvictDirectly
pluginConfig:
- name: MigrationController
args:
defaultJobMode: EvictDirectly对于手动创建PodMigrationJob,关闭资源保留功能。
apiVersion: scheduling.koordinator.sh/v1alpha1
kind: PodMigrationJob
metadata:
name: migrationjob-demo
spec:
mode: EvictDirectly1.3 资源保留机制
koordinator-scheduler将reservation看作像pod一样的调度单位,它会根据里reservation的信息进行调度(可以认为reservation是用来占坑的虚拟pod),分配一个满足需要的节点,对这个节点进行预留资源。等待相关的reservation相关的新pod生成,则将预留的资源分配给这个新的pod。
2 MigrationController是如何运行的呢?
我们以同时启用了LowNodeLoad和MigrationController两个插件为例,下面是koordinator-descheduler的配置,LowNodeLoad做为balance类型插件和MigrationController做为evict类型插件。
profiles:
- name: koord-descheduler
plugins:
deschedule:
disabled:
- name: "*"
disable LowNodeLoad by default
balance:
enabled:
- name: LowNodeLoad
evict:
disabled:
- name: "*"
enabled:
- name: MigrationController
pluginConfig:
- name: MigrationController
args:
apiVersion: descheduler/v1alpha2
kind: MigrationControllerArgs
evictionPolicy: Eviction
namespaces:
exclude:
- kube-system
evictQPS: "10"
evictBurst: 1
- name: LowNodeLoad
args:
apiVersion: descheduler/v1alpha2
kind: LowNodeLoadArgs
evictableNamespaces:
exclude:
- kube-system
useDeviationThresholds: false
lowThresholds:
cpu: 45
memory: 55
highThresholds:
cpu: 75
memory: 802.1 MigrationController插件执行流程
在LowNodeLoadArgs插件执行节点上的pod驱逐阶段,会调用evicted插件(这里配置的是MigrationController)执行驱逐。
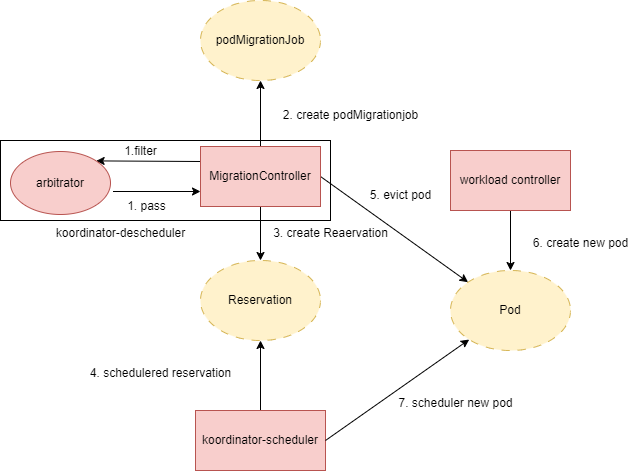
MigrationController执行evict时候做的事情:
调用arbitrator,让arbitrator决定是否要执行后续的驱逐流程(仲裁机制)
创建PodMigrationJob(自定义cr)资源,用于记录pod迁移处理状态。
如果MigrationController配置里启用了资源保留功能(defaultJobMode为ReservationFirst,这个是默认启用),则创建Reservation(自定义cr)资源,用于koordinator-scheduler进跟踪资源保留的状态,让koordinator-scheduler对新生成的pod进行资源保留。同时等待koordinator-scheduler成功预留了资源,koordinator-descheduler会同步Reservation状态到PodMigrationJob。
执行pod驱逐。
如果MigrationController启用了资源保留功能,则等待新pod调度完成(即成功为新pod分配了预留的资源)。
2.2 arbitrator
在创建job之前和之后arbitrator都会进行仲裁(决定pod是否继续执行后续驱逐)。
它包括了一些内置驱逐的限制,同时提供了一个可以人工干预的方法,让pod不被驱逐(即pod的annotation里添加"scheduling.koordinator.sh/eviction-cost"的值等于int32最大值)
内置限制(符合任意一个条件的不进行驱逐)包括:
annotation里"scheduling.koordinator.sh/eviction-cost"的值等于int32最大值
defaultJobMode为ReservationFirst,且需要被驱逐的pod的Spec.SchedulerName不在MigrationController插件的SchedulerNames配置项里。即如果MigrationController配置里启用了资源保留功能,则当pod的调度器不在MigrationController插件配置调度器列表里不进行驱逐。
节点上不能被驱逐的pod(跟官方descheduler一样,具体规则请查看descheduler插件过滤规则)
pod的namespace不在MigrationController配置项Namespaces.Include里
pod的namespace在MigrationController配置项Namespaces.Exclude里
MaxMigratingPerWorkload和MaxMigratingPerWorkload超过pod对应的workload的副本数,或workload下的pod数量为1
pod的annotation里没有"descheduler.alpha.kubernetes.io/evict",且满足下面任一个条件
整个descheduler驱逐达到了MigrationController配置里ObjectLimiters里的速率限制
这个节点上通过仲裁的pod数量大于MigrationController配置里MaxMigratingPerNode
pod的所在的namespace下已经通过仲裁的PodMigrationJob数量超过了MigrationController配置里MaxMigratingPerNamespace限制
pod的workload下迁移的pod超过MaxMigratingPerWorkload,或正在迁移的pod数量加workload下不可用的pod数量超过了MaxUnavailablePerWorkload
在创建PodMigrationJob之后,还会进行再次检查上面条件(这个是为了检查手动创建的podMigrationJob)
比如手动迁移指定的pod,会人为的为这个pod创建PodMigrationJob
2.3 三种执行驱逐的方法
MigrationController最终执行驱逐操作,支持三种驱逐动作。
- 调用Delete方法执行删除–MigrationController的配置参数EvictionPolicy配置为"Delete"
- 调用Evict方法执行删除–MigrationController的配置参数EvictionPolicy配置为"Eviction"
- 不进行pod移除操作,而是pod的annotation里添加key为"scheduling.koordinator.sh/soft-eviction"]",值为记录了驱逐的原因、谁触发的、时间和DeleteOptions的json字符串–MigrationController的配置参数EvictionPolicy配置为"SoftEviction"
3 MigrationController插件配置参数
| 参数 | 说明 | 默认值 |
|---|---|---|
| dryRun | 执行驱逐流程,但是不创建Reservation和不执行驱逐pod | false |
| evictFailedBarePods | 孤儿pod且为failed状态是否驱逐 | false |
| evictLocalStoragePods | 是否驱逐带有本地存储的pod | false |
| evictSystemCriticalPods | 是否驱逐优先级为SystemCritical的pod | false |
| IgnorePvcPods | 有pvc的pod是否驱逐 | false |
| labelSelector | pod匹配这个LabelSelector才会被驱逐 | nil |
| priorityThreshold | pod的优先级小于这个级别才会被驱逐 | nil |
| maxConcurrentReconciles | 最大并发Reconciles数量 | 1 |
| namespaces.include | 代表忽略这些命名空间下的pod。 首先检查include,然后再检查exclude。 | nil |
| namespaces.exclude | 代表只考虑这些命名空间下的pod。 首先检查include,然后再检查exclude。 | nil |
| nodeFit | 是否有合适的节点调度新的pod,包括检查NodeAffinity和Taint容忍(目前这个参数在v1.4版本没有作用) | false |
| nodeSelector | 用于过滤出目标节点,并判断能否从这些节点里找到能够容纳被驱逐pod的节点(目前这个参数在v1.4版本没有作用) | false |
| maxMigratingPerNode | 每个节点上最大可以迁移的pod数量(0代表不限制) | 2 |
| maxMigratingPerNamespace | 每个namespace下最多可以迁移的pod数量(0代表不限制) | 0 |
| maxMigratingPerWorkload | 每个pod所属的workload下最多可以迁移的pod数量 其中0代表:副本数大于10,则为10%的workload副本数 副本数大于等于4小于等于10,则为2 其他情况(副本数小于4),为1 | 0 |
| maxUnavailablePerWorkload | 在pod迁移时候,所属的workload最大不可用pod数量 其中0代表:副本数大于10,则为10%的workload副本数 副本数大于等于4小于等于10,则为2 其他情况(副本数小于4),为1 | 0 |
| skipCheckExpectedReplicas | 如果为false,则检查maxMigratingPerWorkload和maxUnavailablePerWorkload配置应该小于当前workload的期望的副本数 | false |
| objectLimiters | 配置驱逐速率限制,目前只支持workload维度的驱逐速率限制。 每个维度下面可以设置的参数为maxMigrating和duration,代表在duration窗口内最大可以迁移pod数量为maxMigrating 这个功能和上面maxMigratingPerWorkload有重复,但是代码逻辑不一样,maxMigratingPerWorkload根据当时所有podMigrationJob进行统计,而objectLimiters使用rateLimiter来统计。 这里两个都存相同的问题,如果pod是deployment生成,workload是replicaSet,在deployment滚动更新的时候,deployment副本数跟replicas不一样。 | nil |
| defaultJobMode | 代表PodMigrationJob执行pod驱逐的工作模式 可以设置:“ReservationFirst”–等待kooridinator-scheduler保留资源成功后,再执行pod驱逐,“EvictDirectly”–直接执行pod驱逐 | “ReservationFirst” |
| defaultJobTTL | koordinator-descheduler创建的PodMigrationJob资源生存时间 | 5m |
| schedulerNames | 这是一个调度器名字列表,这些调度器能够处理资源保留功能 当启用资源保留功能后,如果pod的调度器名字不在这个列表里,不会对这个pod执行驱逐。 | [“koord-scheduler”] |
| evictQPS | 全局限制,每秒驱逐pod数量 | 10 |
| evictBurst | 全局限制,最大突发的驱逐pod数量 | 1 |
| evictionPolicy | 配置执行pod驱逐的方法 可以配置:“Eviction”–调用Evict方法执行删除。“Delete”–调用Delete方法执行删除。“SoftEviction”–pod的annotation里添加key为"scheduling.koordinator.sh/soft-eviction"]",值为记录了驱逐的原因、谁触发的、时间和DeleteOptions的json字符串 | “Eviction” |
| defaultDeleteOptions | 执行驱逐pod时候传递的参数 | nil |
| arbitrationArgs.enabled | 是否开启仲裁机制 | true |
| arbitrationArgs.interval | 对PodMigrationJob执行仲裁的周期 | 500ms |
4 总结
MigrationController插件是解决了descheduler驱逐pod之后,新的pod处于不可调度状态。同时能够手动驱逐某个pod(通过手动创建PodMigrationJob)和让特定的pod不被驱逐。
资源预留功能需要配合koordinator-scheduler才能完成,所以需要同时运行koordinator-descheduler与koordinator-scheduler。


![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)