karmada作为集群资源同步工具在灾备系统中的实践
1 karmada是什么?
karmada是一个kubernetes多集群管理系统,它可以保持原有使用apiserver的方式,将资源分布到多个集群中。提供了跨云多集群多模式管理、多策略的多集群调度、应用的跨集群故障转移、全局统一资源视图、多集群的服务发现和FederatedHPA能力。它的设计思路继承了集群联邦v2,目前是cncf的sandbox开源项目。
详细请访问官网https://karmada.io/
这篇文章使用的karmada版本为v1.6.2
2 背景
集群容灾方案:一个集群作为生产集群对外提供服务,另一个集群作为standby集群。当生产集群发生故障时候,流量切换到standby集群。
同时为了节省成本,standby集群使用云厂商的无服务器集群,非启用时间workload的replicas为0(或没有运行的pod),启用时候调整replicas不为0。由于使用云厂商的无服务器原因,需要添加一些annotation到pod中,以修改一些运行时配置,同时需要容忍一些污点。
3 解决方案
3.1 自研方案
需要满足以下需求:
需要考虑扩展性,新添加CRD,无需修改或少改代码
需要支持资源的白名单和黑名单,进行资源的过滤
需要提供灵活配置方式来进行资源修改
提供观测功能,能监控同步失败和成功资源数量
优点:代码可控,功能可以定制,锻炼编码能力
缺点:重复造轮子,费时费力
3.2 开源解决方案Velero
velero是集群资源和数据的备份工具。备份时候将数据保存在对象存储中,进行恢复时候从对象存储中下载备份,然后进行资源和数据恢复。
velero的restore resource modifiers功能可以完成资源修改。
优点:操作简单和方便
缺点:备份和恢复需要一定时间,备份有延迟,导致集群无法做到准实时状态。
3.3 开源解决方案Karmada
ClusterPropagationPolicy和PropagationPolicy能够将资源分发到多个集群中,ClusterOverridePolicy和OverridePolicy进行资源的覆盖。
优点:功能丰富,能够保证准集群间资源的准实时
缺点:架构复杂,进行多层资源抽象,有一定上手门槛。
4 最终选择karmada方案
4.1 选择karmada的原因
- 能够保证准集群间资源的准实时,保证集群故障切换流量时,尽可能减少集群间的差异。
- 不需要重复造轮子
4.2 改造成本
karmada设计架构是karmada组件部署在一个control plane集群中,包括单独的apiserver,组成一个独立的kubernetes集群,类似kubernetes in kubernetes。
使用karmada管理已有的集群的资源,需要将资源迁移到karmada control plane集群中。使用karmadactl promote命令进行迁移,但是它只能支持一个资源,不能支持批量迁移。已有集群有大量的资源,迁移非常麻烦。
同时原先连接到已有apisever,需要切换到karmada control plane集群apisever。
4.3 复用apisever
使用已有集群的apiserver做为karmada control plane集群apisever,那么就无需进行资源的迁移,也不需要进行apiserver地址的切换。实现系统无需改造情况下,使用karmada能力。
相关文档:Can I install Karmada in a Kubernetes cluster and reuse the kube-apiserver as Karmada apiserver
4.4 架构
4.4.1 两个集群都能互通情况下的架构图
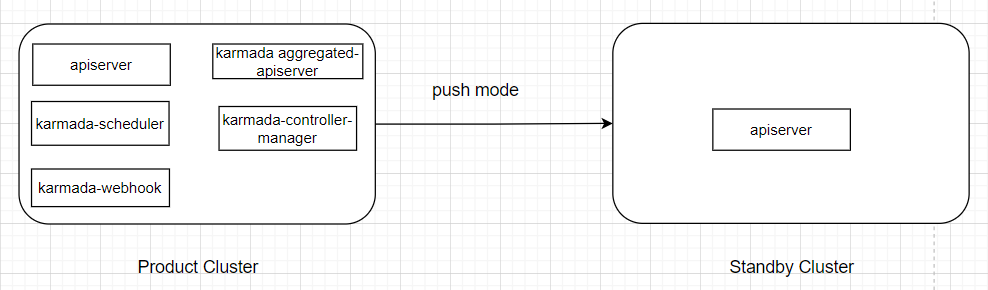
4.4.2 两个集群网络不能互通架构
使用proxy代理
编辑cluster资源,添加代理地址到spec.proxyURL
apiVersion: cluster.karmada.io/v1alpha1
kind: Cluster
metadata:
finalizers:
- karmada.io/cluster-controller
generation: 3
name: test-cluster
spec:
proxyURL: http://proxy-address #添加代理地址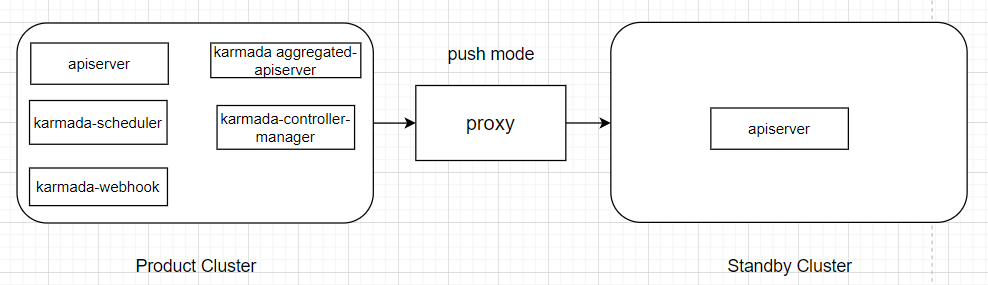
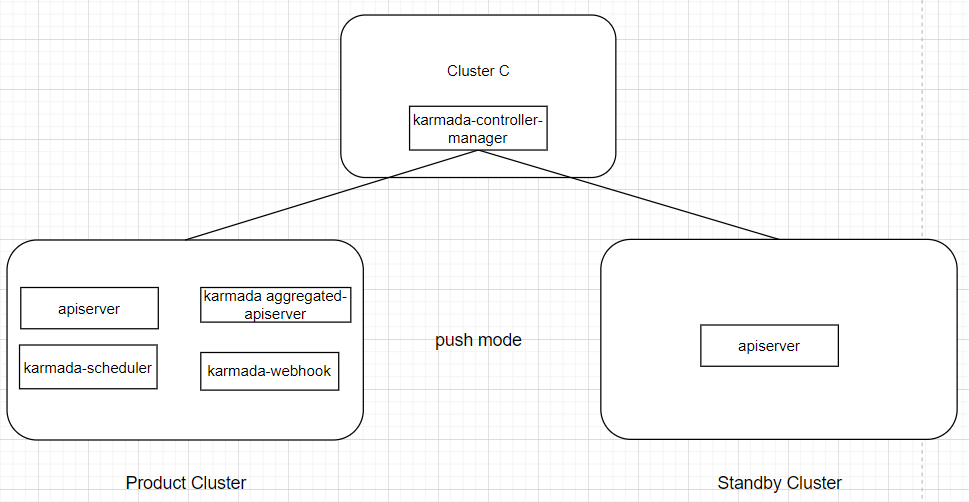
独立部署karmada controller manager(只保证资源同步功能正常)
将karmada-controller-manager进行独立部署到cluster C,cluster C都能访问这两个集群。
4.5 屏蔽集群组件资源同步
集群中的监控、日志、ingress等组件不需要同步,kubernetes内部的命名空间下的资源不要同步
karmada-controller-manager添加--skipped-propagating-namespaces忽略这些命名空间下的资源
--skipped-propagating-namespaces=velero,prometheus,default,kube-system,kube-public,kube-node-lease5 睬坑经验
5.1 workload名字长度大于52字符无法同步
由于karmada的设计原因,在standby集群里的创建workload时会添加label,key为 resourcebinding.karmada.io/name,value为{workload name}-{workload kind}。而label的key和value的长度最大63字符。
比如deployment资源,value后缀为"-deployment",长度为11字符,所以deployment资源名字长度必须小于等于52个字符。
https://github.com/karmada-io/karmada/issues/3834
https://docs.google.com/document/d/1b-5EHUAQf8wIoCnerKTHiyiSIzsypqCNz0CWUzvUhnI/
5.2 同时删除PropagationPolicy和OverridePolicy,workload资源不会消失
在测试同步规则时候,为了删除standby集群里的同步资源,执行删除PropagationPolicy和OverridePolicy。但是standby集群里的workload并没有被移除,反而workload的属性变成跟product集群一样。
另外一个case,集群从karmada中移除后再加入,在没有PropagationPolicy情况下,集群资源又被同步到standby集群。
https://github.com/karmada-io/karmada/issues/3873
5.3 product集群的workload的status会被karmada修改
同步成功的workload,在product集群的workload的status会被karmada-controller-manager修改,这导致一系列的异常情况。比如pvc的status.capacity字段被移除,导致pod的挂载失败。
解决方法:karmada-controller-manager里禁用bindingStatus controller
--controllers=-bindingStatus,*https://github.com/karmada-io/karmada/issues/3907
5.4 使用overridePolicy里的plaintext无法添加不存在的字段
同步到standby集群的wokload,都需要在spec.template.metadata.annotation添加一些annotation,但是有一些workload里没有spec.template.metadata.annotation,导致workload同步失败。
https://github.com/karmada-io/karmada/issues/3923
6 参考配置
提供一下我的最终配置
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
- apiVersion: apps/v1
kind: StatefulSet
propagateDeps: true
placement:
clusterAffinity:
clusterNames:
- test
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterOverridePolicy
metadata:
name: workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
- apiVersion: apps/v1
kind: StatefulSet
overrideRules:
- overriders:
plaintext:
- path: /spec/replicas
operator: replace
value: 0
- path: /spec/template/spec/tolerations
operator: add
value:
- key: "eks.tke.cloud.tencent.com/eklet"
operator: "Exists"
effect: "NoSchedule"
- path: /spec/template/spec/schedulerName
operator: add
value: "tke-scheduler"
- path: /spec/template/spec/schedulerName
operator: replace
value: "tke-scheduler"
- path: /spec/template/metadata/annotations/AUTO_SCALE_EKS
operator: add
value: "true"
- path: /spec/template/metadata/annotations/eks.tke.cloud.tencent.com~1resolv-conf
operator: add
value: |
nameserver 10.10.248.248
nameserver 10.10.249.249
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterOverridePolicy
metadata:
name: pvc
spec:
resourceSelectors:
- apiVersion: v1
kind: PersistentVolumeClaim
overrideRules:
- overriders:
plaintext:
- path: /spec/volumeName
operator: remove
annotationsOverrider:
- operator: remove
value:
pv.kubernetes.io/bound-by-controller: "yes"
pv.kubernetes.io/bind-completed: "yes"
volume.kubernetes.io/selected-node: ""
pv.kubernetes.io/provisioned-by: ""
volume.kubernetes.io/storage-provisioner: ""
volume.beta.kubernetes.io/storage-provisioner: ""
---
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: network
spec:
resourceSelectors:
- apiVersion: v1
kind: Service
- apiVersion: networking.k8s.io/v1
kind: Ingress
- apiVersion: networking.k8s.io/v1
kind: IngressClass
propagateDeps: true
placement:
clusterAffinity:
clusterNames:
- test

![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)