为什么HPA扩容比较慢
最近遇到业务活动期间遇到突发流量,由于pod资源使用飙升导致业务可用性降低的问题。这里面导致业务不可用的原因有很多,其中一个直接原因是流量来临时候资源使用飙升,而HPA没有及时的进行扩容。 这篇文章就是针对这个问题进行研究,主要从这三方面进行阐述:
- 扩容有多慢
- 为什么扩容慢
- 有什么解决方案
1 扩容有多慢
为了说明扩容有多慢,进行HPA扩容测试,记录每一时刻的副本数和pod的资源使用,对比流量增加时间和第一次副本数增加时间,粗略得出扩容的延迟。
hpa的数据源配置有"Object"、“Pods”、“Resource”、“ContainerResource”、“External”。为了测试简单这里只使用"Resource"进行测试,同时kubernetes版本为1.23。
测试方法:准备一个nginx deployment和service,然后对这个service进行压测,记录下每一时刻的副本数。
nginx deployment副本数为2,CPU的request为20m,hpa的目标设置为request的20%平均利用率。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.18
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
cpu: 20m
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-deployment
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 20
type: Utilization
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: ngx-service
namespace: default
spec:
clusterIP: 10.252.211.253
clusterIPs:
- 10.252.211.253
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
sessionAffinity: None
type: ClusterIP1.1 测试过程
使用ab命令对cluster ip进行压测
# date;ab -n 100000 -c 20 10.252.211.253/;date
Thu Nov 2 13:10:00 CST 2023
.....
Thu Nov 2 13:10:11 CST 2023在另一个窗口记录pod metrics
#while :; do date; kubectl get pods.metrics.k8s.io -l app=nginx;echo;sleep 1;done
Thu Nov 2 13:10:23 CST 2023
NAME CPU MEMORY WINDOW
nginx-deployment-596d9ffddd-6lrhv 0 9604Ki 17.068s
nginx-deployment-596d9ffddd-w6cm2 0 2060Ki 17.634s
Thu Nov 2 13:10:25 CST 2023
NAME CPU MEMORY WINDOW
nginx-deployment-596d9ffddd-6lrhv 505634152n 9548Ki 13.763s
nginx-deployment-596d9ffddd-w6cm2 523202787n 2060Ki 13.914s
Thu Nov 2 13:10:27 CST 2023
NAME CPU MEMORY WINDOW
nginx-deployment-596d9ffddd-6lrhv 505634152n 9548Ki 13.763s
nginx-deployment-596d9ffddd-w6cm2 523202787n 2060Ki 13.914s在另一个窗口记录副本数
#while :; do date;kubectl get deployments.apps nginx-deployment ;sleep 1;echo;done在另一个窗口记录hpa资源变化
kubectl get hpa nginx-deployment -o yaml -w 完整的测试记录在https://gist.github.com/wu0407/ebea8c0ee9ecbc15e94b3122f1a193dc
1.2 测试结果
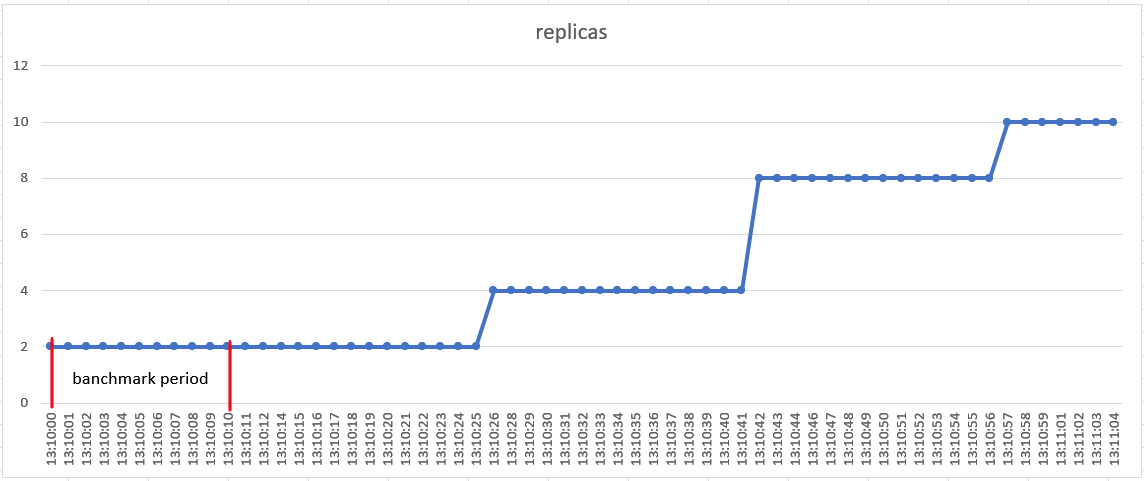
- 从13:10:00开始进行压测到13:10:11压测结束。
- 在13:10:26扩容2个副本,13:10:42扩容4个副本,13:10:57扩2个副本
- 在13:10:25 pod metrics资源观察到pods使用资源增加
1.3 结果分析
由于pod的扩容阈值是CPU平均使用为4m,可以粗略的认为只要有请求,pod的CPU平均使用率就超过4.2m(这里要加--horizontal-pod-autoscaler-tolerance,默认为0.1),那么这个实验里的扩容延迟为26s。
扩容是分成3个阶段,而不是一下扩容到10个副本。
甚至在没有压测流量时候还进行扩容,hpa对象里的status.currentMetrics里资源使用为0,但是desiredReplicas和currentReplicas不相等。
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: "0"
name: cpu
type: Resource
currentReplicas: 8
desiredReplicas: 10
lastScaleTime: "2023-11-02T05:10:57Z"2 为什么扩容慢
为什么会出现上面扩容的行为呢?为什么会有扩容延迟?
为了回答上面问题,首先需要知道HPA的扩容机制和HPA的扩容算法。
2.1 HPA扩容机制
horizontal pod autoscaler controller是kube-controller-manager的一部分,的它通过访问apiserver获得各个类型的资源监控数据。而这些监控数据是metrics-server提供的,metrics-server作为Aggregated API Servers扩展metrics.k8s.io 组下的API。custom.metrics.k8s.io和external.metrics.k8s.io 组下的API是由prometheus-adapter作为Aggregated API Servers提供的。
下面是HPA的架构图
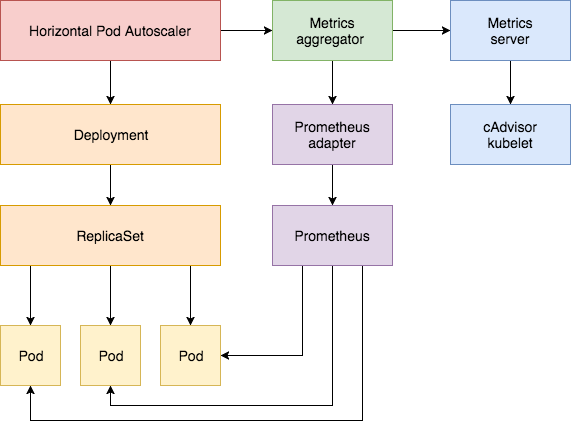
图片来自:https://www.weave.works/blog/kubernetes-horizontal-pod-autoscaler-and-prometheus
2.2 HPA计算流程
horizontal pod autoscaler controller默认每隔15秒执行一个HPA对象的调谐,即每隔15秒根据监控数据计算期望的副本数。如果期望的副本数不等于当前的副本数,则进行扩缩容。
流程:
- 访问apiserver获得监控数据
- 计算期望的副本数
- 扩缩容行为控制
2.2.1 监控数据获取
根据不同类型的数据源访问不同地址,这里就不展开了,详细可以看我的HPA代码注释
2.2.2 副本数算法
ratio为当前metric值与目标值的比值
tolerance为--horizontal-pod-autoscaler-tolerance,它指定了扩缩时候容忍抖动的范围,默认值为0.1
副本数为workload里scale资源的spec.replicas
当前的副本数为scale资源里的status.replicas
desiredReplicas为期望的副本数
2.2.2.1 object类型的数据源
- target类型是"Value",
ratio = MetricValue/spec.metrics[*].object.target.value- 如果spec.replicas为0,则desiredReplicas为
ratio向上取整。 - spec.replicas大于0,如果ratio在
[1-tolerance, 1+tolerance]范围内就不进行扩缩容,desiredReplicas为spec.replicas。否则desiredReplicas为ratio*readyPodCount向上取整
- 如果spec.replicas为0,则desiredReplicas为
- target类型为"AverageValue",
ratio = MetricValue / (spec.metrics[*].object.target.averageValue * status.replicas)- 如果ratio在
[1-tolerance, 1+tolerance]范围内,不进行扩缩容,desiredReplicas为spec.replicas。 - 否则desiredReplicas为
MetricValue / spec.metrics[*].object.target.averageValue向上取整
- 如果ratio在
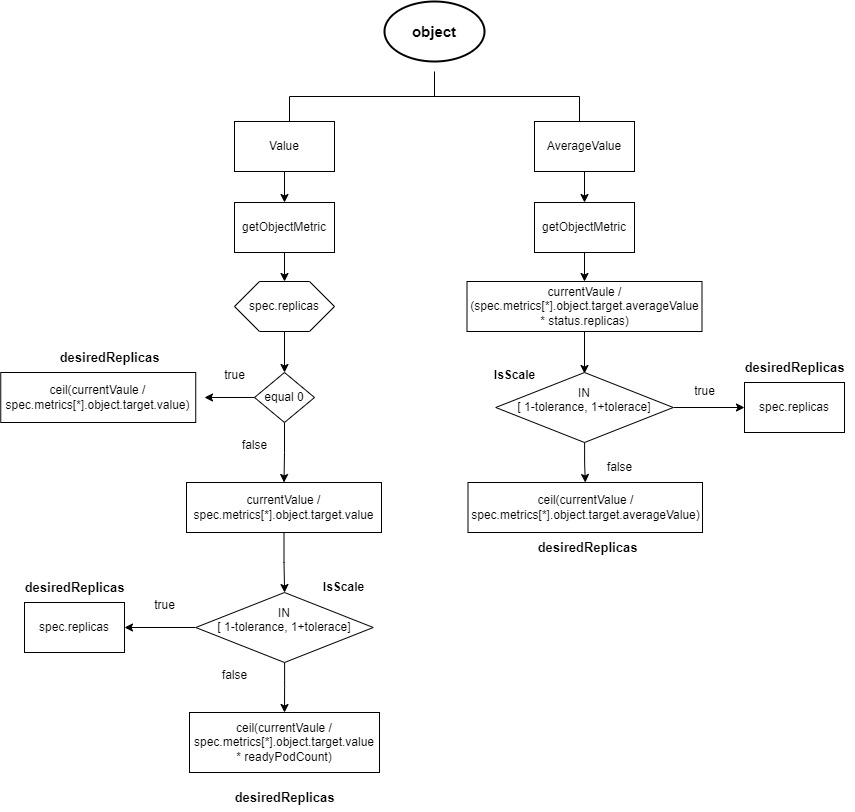
readyPodCount为处于ready状态的pod的数量
2.2.2.2 external类型的数据源
- target类型是"Value",
ratio = totalValue / spec.metrics[*].external.target.value- 如果spec.replicas为0,否则desiredReplicas为
ratio向上取整 - spec.replicas大于0,如果ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容,desiredReplicas为spec.replicas。否则desiredReplicas为ratio*readyPodCount向上取整
- 如果spec.replicas为0,否则desiredReplicas为
- target类型是"AverageValue",
ratio = totalValue / (spec.metrics[*].external.target.averageValue * status.replicas)- 如果ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容,desiredReplicas为status.replicas。 - 否则desiredReplicas为
totalValue / spec.metrics[*].external.target.averageValue向上取整
- 如果ratio在
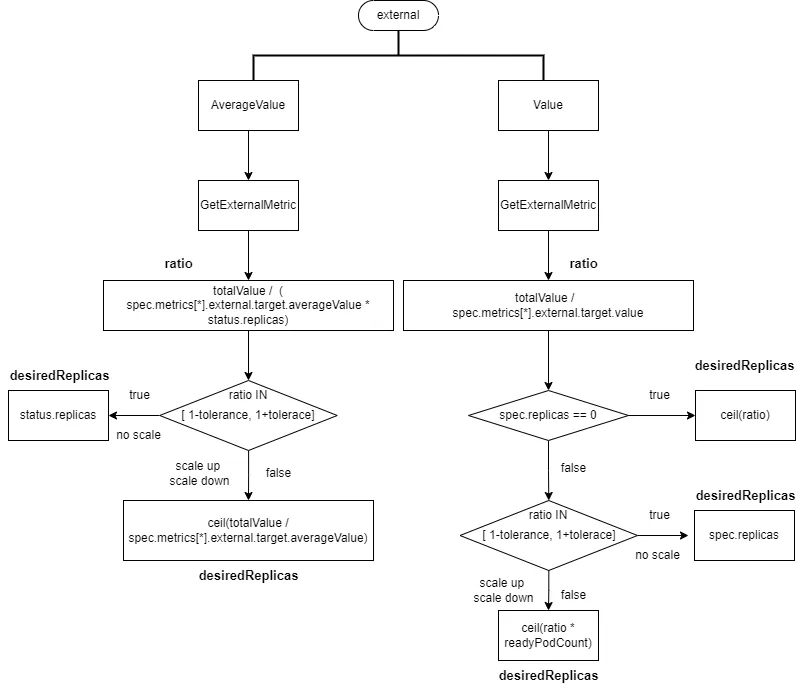
2.2.2.3 pod分类
因为pod的状态和pod是否有监控数据会影响副本数计算,所以要进行pod分类,对不同类型的pod进行不同的监控数据修复。
cpuInitializationPeriod:为--horizontal-pod-autoscaler-cpu-initialization-period的值,默认为5分钟
delayOfInitialReadinessStatus:为--horizontal-pod-autoscaler-initial-readiness-delay的值,默认为30s
根据pod状态和监控数据,对pod进行分类。分为“ready且有监控数据”、“unreadyPods”、“ignoredPods”、“missingPods”
unreadyPods:
- pod的Phase为pending
- resource、containerResource类型的数据源且为CPU资源监控的数据
- pod status没有type为Ready的condition或pod.Status.StartTime为nil(pod未被kubelet接管)
- 计算副本时间还未超过pod启动时间加
cpuInitializationPeriod,且ready condition为false - 计算副本时间还未超过pod启动时间加
cpuInitializationPeriod,且为ready状态且metric的timestamp是在readyCondition.LastTransitionTime加metric.Window之前 - 计算副本时间已经超过pod启动时间加
cpuInitializationPeriod,且ready condition为false,且readyCondition.LastTransitionTime在pod.Status.StartTime加delayOfInitialReadinessStatus时间内
missingPods:没有监控数据的pod
ignoredPods:pod被删除或pod的phase为“Failed”
2.2.2.4 数据修复
上面两种类型的监控数据是聚合数据,即多个pod对应一个监控数据。而下面三种类型的监控数据不是聚合数据,即每个pod对应一个监控数据。如果pod异常和监控数据缺失都会导致计算出的副本数异常,为了避免过多的扩容和缩容,所以需要进行数据修复。
- 根据ready pod数量和已有的监控数据,计算出副本数,根据这个副本数在不需要考虑tolerance下是否需要扩缩容。如果需要扩容,则没有监控数据pod的监控数据修正为0。需要缩容,则没有监控数据pod的监控数据修正为HPA对象里设置目标值。
- 需要扩容且存在unready pod,则unready pod的监控数据修复为0。(为了防止新生成的pod启动时候使用CPU很高,导致一直触发扩容)
| unreadyPods > 0 | missingPods > 0 | action | |
|---|---|---|---|
| scale up | true | true | fix unreadyPods and missingPods metrics value as 0 |
| scale up | true | false | no action |
| scale up | false | true | fix missingPods metrics value as 0 |
| scale up | false | false | no action |
| scale down | true | true | fix missingPods metrics as target value |
| scale down | true | false | no action |
| scale down | false | true | fix missingPods metrics as target value |
| scale down | false | false | no action |
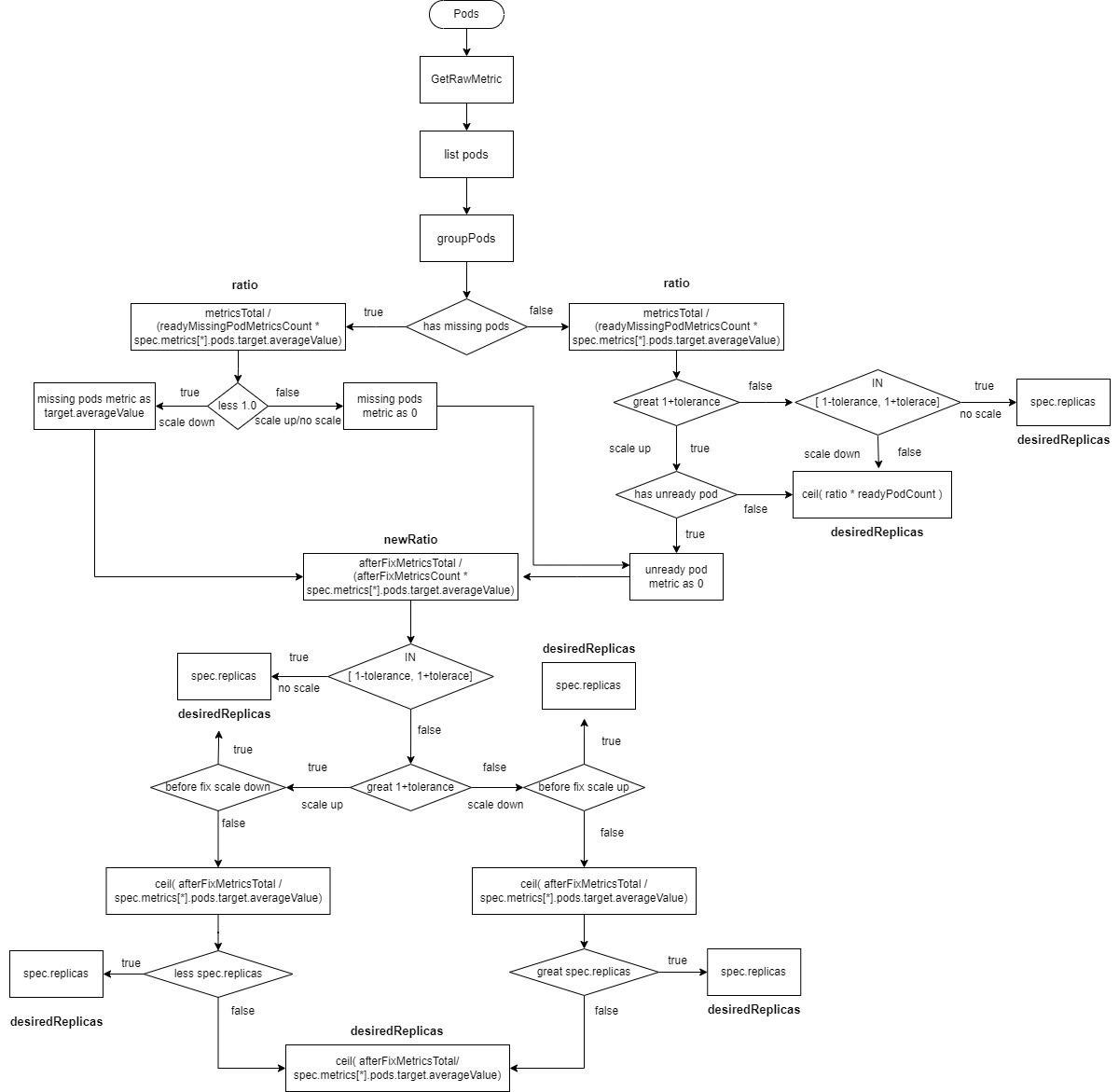
2.2.2.5 Pods类型的数据源
readyMissingPodMetricsCount为所有pod metrics中移除ignoredPods和unreadyPods后的metrics数量。
afterFixMetricsCount为数据修复之后pod的metric数量
- 计算
ratio=metricsTotal /(readyMissingPodMetricsCount * spec.metrics[*].pods.target.averageValue)。 - 如果有
missingPods且ratio小于1(缩容),则missingPods的监控数据修复为spec.metrics[*].pods.target.averageValue,afterFixMetricsCount重新包括了missingPods数量。 - 如果有
missingPods且ratio大于等于1(扩容或不扩不缩),则missingPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量。如果有unreadyPods,则unreadyPods的监控数据修复为0。afterFixMetricsCount重新包括了unreadyPods数量。 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且存在unreadyPods,则unreadyPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且不存在unreadyPods,则desiredReplicas为ratio*readyPodCount向上取整 - 如果没有
missingPods且ratio在[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果没有
missingPods且ratio小于1-tolerance,则进行缩容desiredReplicas为ratio*readyPodCount向上取整 - 重新计算新的ratio,
newRatio=afterFixMetricsTotal / (afterFixMetricsCount * spec.metrics[*].pods.target.averageValue - 如果新的ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio大于
1+tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是扩容,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是缩容,则不进行扩缩容desiredReplicas为spec.replicas - 计算新的副本数
ceil( afterFixMetricsTotal / spec.metrics[*].pods.target.averageValue) - 如果新的ratio大于
1+tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是扩容,且新的副本数小于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是缩容,且新的副本数大于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 剩余的情况,
desiredReplicas为ceil( afterFixMetricsTotal / spec.metrics[*].pods.target.averageValue)向上取整
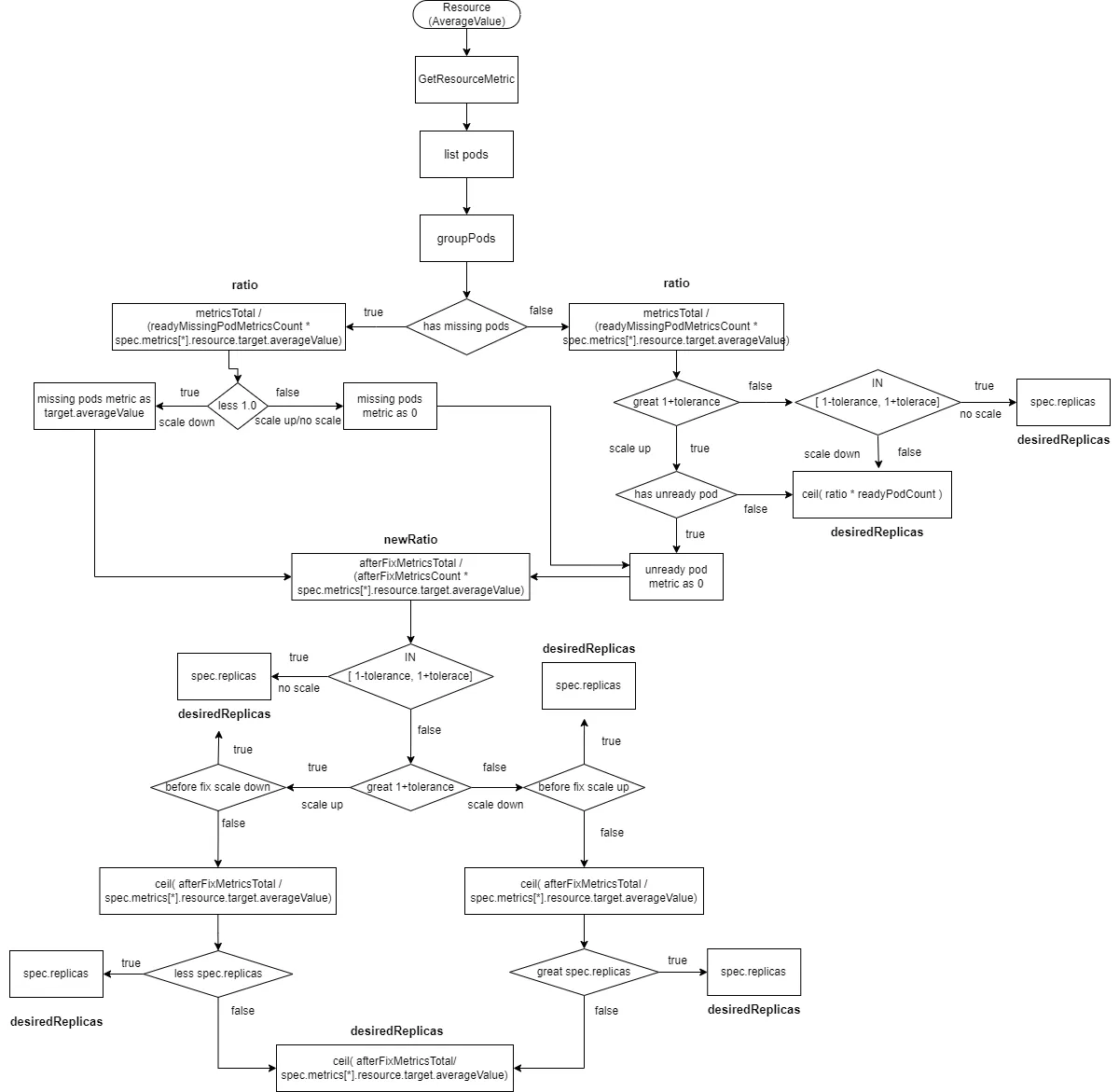
2.2.2.6 Resource类型的数据源且type为AverageValue
这个跟Pods类型的基本一样,只是获取metrics数据的方法不一样,target value是spec.metrics[*].resource.target.averageValue
readyMissingPodMetricsCount为所有pod metrics中移除ignoredPods和unreadyPods后的metrics数量。
afterFixMetricsCount为数据修复之后pod的metric数量
- 计算
ratio=metricsTotal /(readyMissingPodMetricsCount * spec.metrics[*].resource.target.averageValue)。 - 如果有
missingPods且ratio小于1(缩容),则missingPods的监控数据修复为spec.metrics[*].resource.target.averageValue,afterFixMetricsCount重新包括了missingPods数量。 - 如果有
missingPods且ratio大于等于1(扩容或不扩不缩),则missingPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量。如果有unreadyPods,则unreadyPods的监控数据修复为0。afterFixMetricsCount重新包括了unreadyPods数量。 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且存在unreadyPods,则unreadyPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且不存在unreadyPods,则desiredReplicas为ratio*readyPodCount向上取整 - 如果没有
missingPods且ratio在[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果没有
missingPods且ratio小于1-tolerance,则进行缩容desiredReplicas为ratio*readyPodCount向上取整 - 重新计算新的ratio,
newRatio=afterFixMetricsTotal / (afterFixMetricsCount * spec.metrics[*].resource.target.averageValue - 如果新的ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio大于
1+tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是扩容,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是缩容,则不进行扩缩容desiredReplicas为spec.replicas - 计算新的副本数
ceil( afterFixMetricsTotal / spec.metrics[*].resource.target.averageValue) - 如果新的ratio大于
1+tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是扩容,且新的副本数小于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是缩容,且新的副本数大于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 剩余的情况,
desiredReplicas为ceil( afterFixMetricsTotal / spec.metrics[*].resource.target.averageValue)向上取整
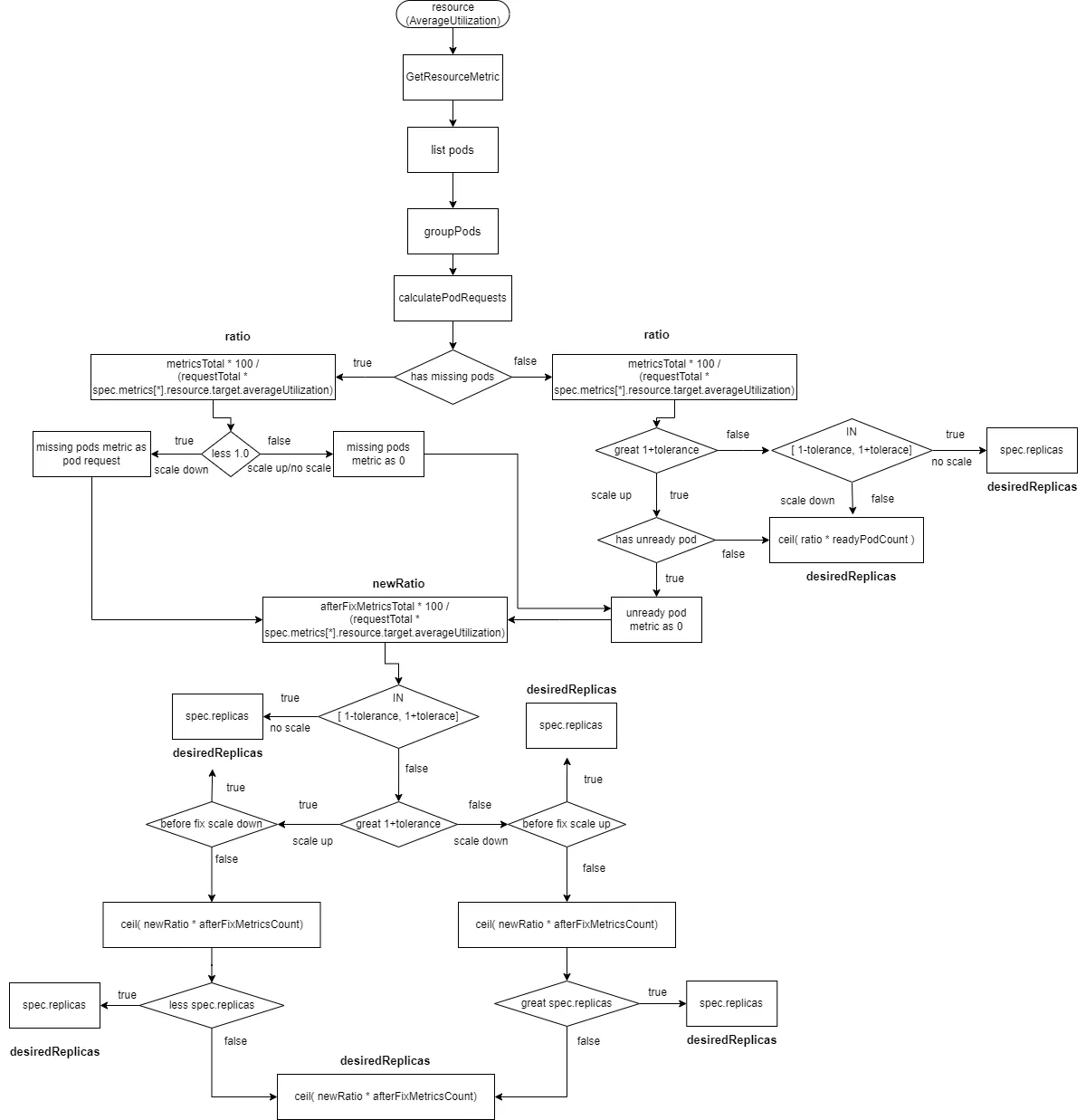
2.2.2.7 Resource类型的数据源且type为AverageUtilization
这里计算ratio发生了变化,ratio = metricsTotal * 100 / (requestTotal * spec.metrics[*].resource.target.averageUtilization)
其中requestTotal为所有pod里的container资源的request总和
readyMissingPodMetricsCount为所有pod metrics中移除ignoredPods和unreadyPods后的metrics数量。
afterFixMetricsCount为数据修复之后pod的metric数量
- 计算
ratio= metricsTotal * 100 / (requestTotal * spec.metrics[*].resource.target.averageUtilization)。 - 如果有
missingPods且ratio小于1(缩容),则missingPods的监控数据修复为spec.metrics[*].resource.target.averageUtilization,afterFixMetricsCount重新包括了missingPods数量。 - 如果有
missingPods且ratio大于等于1(扩容或不扩不缩),则missingPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量。如果有unreadyPods,则unreadyPods的监控数据修复为0。afterFixMetricsCount重新包括了unreadyPods数量。 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且存在unreadyPods,则unreadyPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且不存在unreadyPods,则desiredReplicas为ratio*readyPodCount向上取整 - 如果没有
missingPods且ratio在[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果没有
missingPods且ratio小于1-tolerance,则进行缩容desiredReplicas为ratio*readyPodCount向上取整 - 重新计算新的ratio,
newRatio=afterFixMetricsTotal * 100 / (requestTotal * spec.metrics[*].resource.target.averageUtilization - 如果新的ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio大于
1+tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是扩容,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是缩容,则不进行扩缩容desiredReplicas为spec.replicas - 计算新的副本数
ceil( afterFixMetricsTotal * newRatio) - 如果新的ratio大于
1+tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是扩容,且新的副本数小于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是缩容,且新的副本数大于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 剩余的情况,
desiredReplicas为ceil( afterFixMetricsCount * newRatio)向上取整
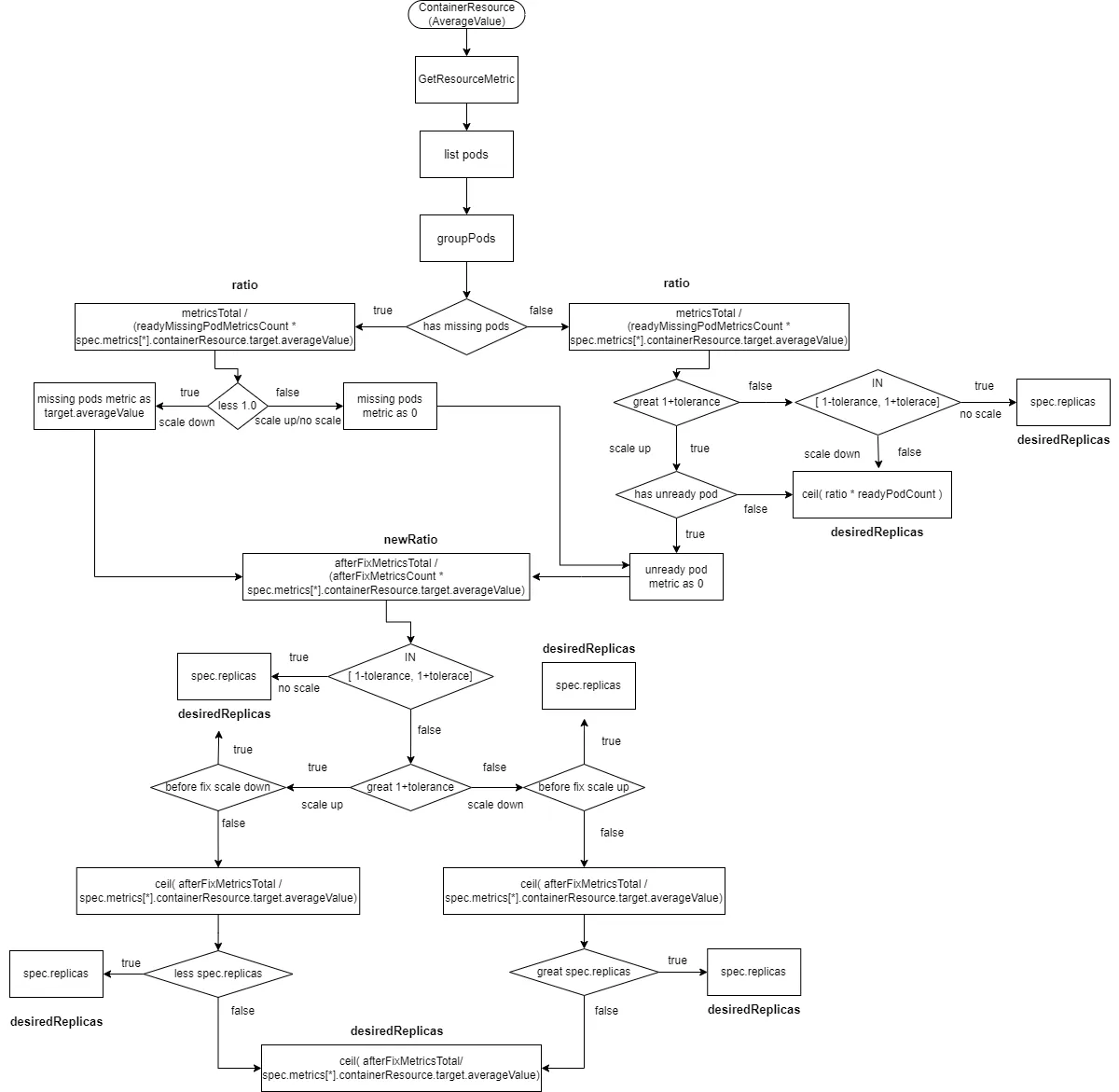
2.2.2.8 ContainerResource类型的数据源且type为AverageValue
这个跟“Resource类型的数据源且type为AverageValue”计算方式类似,只是metricsTotal是每个pod metrics里container(spec.metrics[*].containerResource.container)的metrics value。
readyMissingPodMetricsCount为所有pod metrics中移除ignoredPods和unreadyPods后的metrics数量。
afterFixMetricsCount为数据修复之后pod的metric数量
- 计算
ratio=metricsTotal /(readyMissingPodMetricsCount * spec.metrics[*].containerResource.target.averageValue)。 - 如果有
missingPods且ratio小于1(缩容),则missingPods的监控数据修复为spec.metrics[*].containerResource.target.averageValue,afterFixMetricsCount重新包括了missingPods数量。 - 如果有
missingPods且ratio大于等于1(扩容或不扩不缩),则missingPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量。如果有unreadyPods,则unreadyPods的监控数据修复为0。afterFixMetricsCount重新包括了unreadyPods数量。 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且存在unreadyPods,则unreadyPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且不存在unreadyPods,则desiredReplicas为ratio*readyPodCount向上取整 - 如果没有
missingPods且ratio在[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果没有
missingPods且ratio小于1-tolerance,则进行缩容desiredReplicas为ratio*readyPodCount向上取整 - 重新计算新的ratio,
newRatio=afterFixMetricsTotal / (afterFixMetricsCount * spec.metrics[*].containerResource.target.averageValue - 如果新的ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio大于
1+tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是扩容,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是缩容,则不进行扩缩容desiredReplicas为spec.replicas - 计算新的副本数
ceil( afterFixMetricsTotal / spec.metrics[*].containerResource.target.averageValue) - 如果新的ratio大于
1+tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是扩容,且新的副本数小于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是缩容,且新的副本数大于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 剩余的情况,
desiredReplicas为ceil( afterFixMetricsTotal / spec.metrics[*].containerResource.target.averageValue)向上取整
2.2.2.9 ContainerResource类型的数据源且type为AverageUtilization
这个跟“Resource类型的数据源且type为AverageUtilization”计算流程类似。
这里的totalRequest为pod里的container(在spec.metrics[*].containerResource.container)的资源的request
readyMissingPodMetricsCount为所有pod metrics中移除ignoredPods和unreadyPods后的metrics数量。
afterFixMetricsCount为数据修复之后pod的metric数量
- 计算
ratio= metricsTotal * 100 / (requestTotal * spec.metrics[*].containerResource.target.averageUtilization)。 - 如果有
missingPods且ratio小于1(缩容),则missingPods的监控数据修复为spec.metrics[*].containerResource.target.averageUtilization,afterFixMetricsCount重新包括了missingPods数量。 - 如果有
missingPods且ratio大于等于1(扩容或不扩不缩),则missingPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量。如果有unreadyPods,则unreadyPods的监控数据修复为0。afterFixMetricsCount重新包括了unreadyPods数量。 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且存在unreadyPods,则unreadyPods的监控数据修复为0,afterFixMetricsCount重新包括了missingPods数量 - 如果没有
missingPods且ratio大于1+tolerance(扩容)且不存在unreadyPods,则desiredReplicas为ratio*readyPodCount向上取整 - 如果没有
missingPods且ratio在[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果没有
missingPods且ratio小于1-tolerance,则进行缩容desiredReplicas为ratio*readyPodCount向上取整 - 重新计算新的ratio,
newRatio=afterFixMetricsTotal * 100 / (requestTotal * spec.metrics[*].containerResource.target.averageUtilization - 如果新的ratio在
[1-tolerance, 1+tolerance],则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio大于
1+tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是扩容,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是缩容,则不进行扩缩容desiredReplicas为spec.replicas - 计算新的副本数
ceil( afterFixMetricsTotal * newRatio) - 如果新的ratio大于
1+tolerance,且修复前的ratio大于1+tolerance,即修复之前是扩容且修复之后是扩容,且新的副本数小于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 如果新的ratio小于
1-tolerance,且修复前的ratio小于1-tolerance,即修复之前是缩容且修复之后是缩容,且新的副本数大于spec.replicas,则不进行扩缩容desiredReplicas为spec.replicas - 剩余的情况,
desiredReplicas为ceil( afterFixMetricsCount * newRatio)向上取整
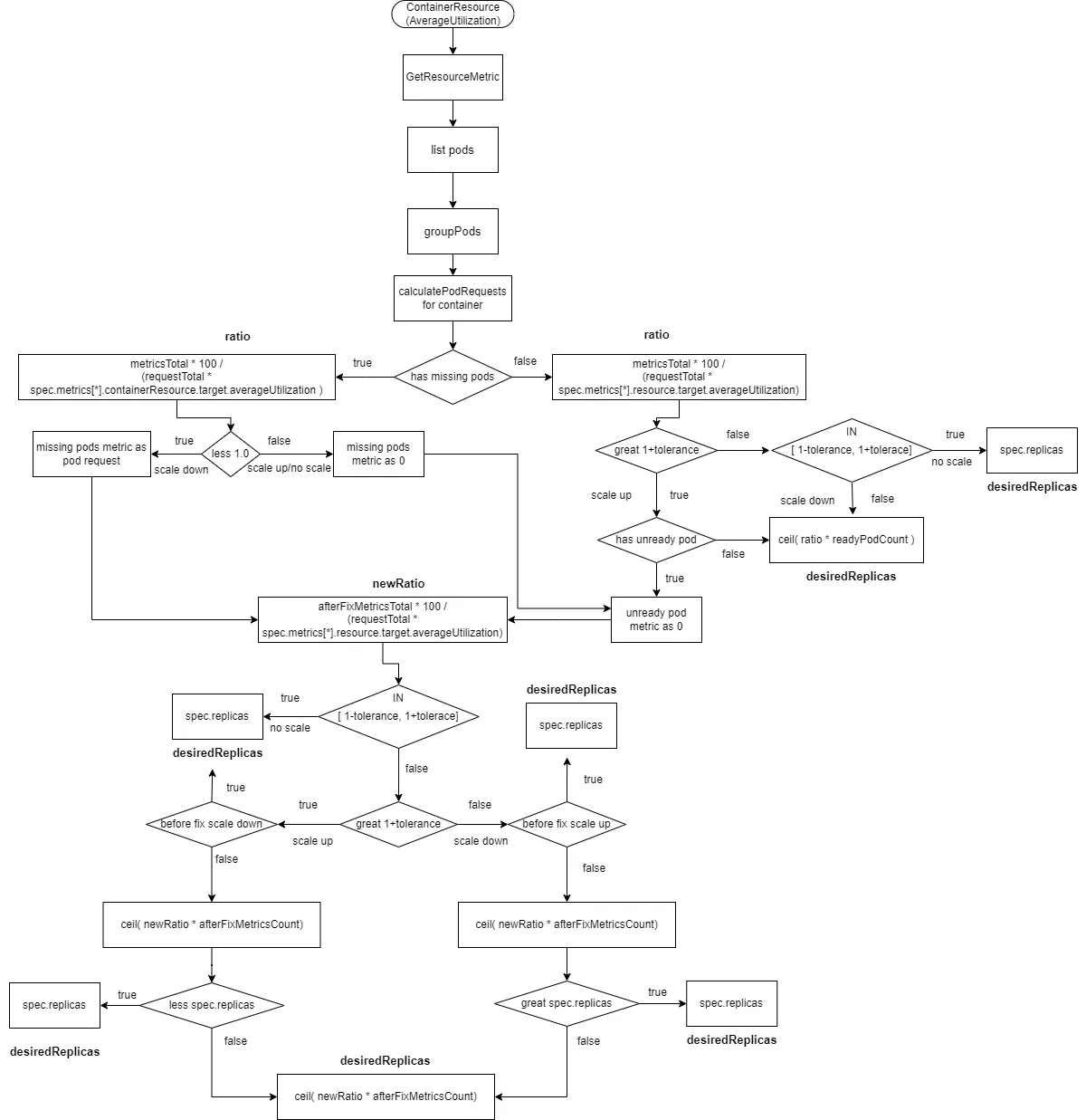
2.3 扩缩容行为策略控制
在上面的流程执行完会得到一个期望的副本数,但是这个副本数并不是HPA controller最终计算的副本数,它还需要经过扩缩容行为控制策略处理才能得到最终的副本数。
扩缩容行为策略是对控制扩缩容的速度进行限制,防止过快扩容和过快的缩容导致的不稳定的行为。
扩缩容行为控制分为两种,HPA对象里未设置了spec.behavior(默认扩缩容行为)和设置spec.behavior。
2.3.1 未设置spec.behavior(默认扩缩容行为)
downscaleStabilisationWindow:为–horizontal-pod-autoscaler-downscale-stabilization的值,默认为5分钟
- 将上面的流程执行的副本数和执行的时间记录到内存里
- 从内存中查找
downscaleStabilisationWindow窗口内最大的副本数stabilizedRecommendation - 这个窗口内的最大扩容上限
scaleUpLimit为max(2*spec.replicas, 4) - 对
stabilizedRecommendation进行规整(大于上限等于上限,小于下限就等于下限),得出最终的副本数。上限为min(scaleUpLimit, hpa.Spec.MaxReplicas),下限为minReplicas(默认为hpa.Spec.minReplicas,当hpa.Spec.minReplicas没有设置时候为1),即确保期望副本数在[minReplicas, min(max(2*spec.replicas, 4), hpa.Spec.maxReplicas)]
2.3.2 设置了spec.behavior
在每次HPA controller进行扩缩容时侯,会将HPA对应的workload的副本数的变化量和扩缩容时间记录到内存中
将上面流程
desiredReplicas和执行时间记录到内存里从
hpa.spec.behavior.scaleUp.stabilizationWindowSeconds窗口中(包括desiredReplicas)查找最小副本数upRecommendation从
hpa.spec.behavior.scaleDown.stabilizationWindowSeconds窗口中(包括desiredReplicas)查找最大副本数downRecommendation对
spec.replicas进行规整得到稳定窗口得副本数stabilizedRecommendation,即如果spec.replicas大于downRecommendation,则stabilizedRecommendation为downRecommendation。如果spec.replicas小于upRecommendation,则stabilizedRecommendation为upRecommendation。即stabilizedRecommendation在[upRecommendation, downRecommendation ],只有spec.replicas小于hpa.spec.behavior.scaleUp.stabilizationWindowSeconds窗口中的最小值才有可能扩容,只有spec.replicas大于hpa.spec.behavior.scaleDown.stabilizationWindowSeconds窗口中的最大值才有可能缩容。在需要扩容情况下(
stabilizedRecommendation大于spec.replicas)hpa.spec.behavior.scaleUp.selectPolicy为Disabled,则不进行扩缩容最终副本数为spec.replicashpa.spec.behavior.scaleUp.selectPolicy为Max,遍历hpa.spec.behavior.scaleUp.policies执行下面:从内存中查找在
policy.periodSeconds这个策略窗口内的累计副本数变化量replicasAddedInCurrentPeriod,窗口开始时候的副本数periodStartReplicas=spec.replicas - replicasAddedInCurrentPeriod。这个策略类型
policy.Type为"Pods",则这个策略窗口内的副本数上限policyLimit为periodStartReplicas + policy.Value这个策略类型
policy.Type为"Percent",则这个策略窗口里的副本数上限policyLimit为Ceil(periodStartReplicas * (1 + policy.Value/100))向上取整这个窗口内的最大扩容上限
scaleUpLimit为所有策略里最大的副本数上限,即scaleUpLimit=max(policyLimit1, policyLimit2....)
hpa.spec.behavior.scaleUp.selectPolicy为Min,遍历hpa.spec.behavior.scaleUp.policies执行下面:从内存中查找在
policy.periodSeconds这个策略窗口内的累计副本数变化量replicasAddedInCurrentPeriod,窗口开始时候的副本数periodStartReplicas=spec.replicas - replicasAddedInCurrentPeriod。这个策略类型
policy.Type为"Pods",则这个策略窗口内的副本数上限policyLimit为periodStartReplicas + policy.Value这个策略类型
policy.Type为"Percent",则这个策略窗口里的副本数上限policyLimit为Ceil(periodStartReplicas * (1 - policy.Value/100))向上取整这个窗口内的最大扩容上限
scaleUpLimit为所有策略里最小的副本数上限,即scaleUpLimit=min(policyLimit1, policyLimit2....)
最终的副本数为
min(stabilizedRecommendation, min(scaleUpLimit, hpa.Spec.maxReplicas))
在需要缩容情况下(
stabilizedRecommendation大于spec.replicas)hpa.spec.behavior.scaleDown.selectPolicy为Disabled,则不进行扩缩容最终副本数为spec.replicashpa.spec.behavior.scaleDown.selectPolicy为Max,遍历hpa.spec.behavior.scaleUp.policies执行下面:从内存中查找在
policy.periodSeconds这个策略窗口内的累计副本数变化量replicasAddedInCurrentPeriod,窗口开始时候的副本数periodStartReplicas=spec.replicas + replicasAddedInCurrentPeriod。这个策略类型
policy.Type为"Pods",则这个策略窗口内的副本数下限policyLimit为periodStartReplicas - policy.Value这个策略类型
policy.Type为"Percent",则这个策略窗口里的副本数下限policyLimit为Ceil(periodStartReplicas * (1 - policy.Value/100))向上取整这个窗口内的最大扩容上限
scaleUpLimit为所有策略里最大副本数上限,即scaleUpLimit=max(policyLimit1, policyLimit2....)
hpa.spec.behavior.scaleDown.selectPolicy为Min,遍历hpa.spec.behavior.scaleDown.policies执行下面:从内存中查找在
policy.periodSeconds这个策略窗口内的累计副本数变化量replicasAddedInCurrentPeriod,窗口开始时候的副本数periodStartReplicas=spec.replicas + replicasAddedInCurrentPeriod。这个策略类型
policy.Type为"Pods",则这个策略窗口内的副本数下限policyLimit为periodStartReplicas - policy.Value这个策略类型
policy.Type为"Percent",则这个策略窗口里的副本数下限policyLimit为Ceil(periodStartReplicas * (1 - policy.Value/100))向上取整这个窗口内的最大扩容上限
scaleUpLimit为所有策略里最大副本数上限,即scaleUpLimit=min(policyLimit1, policyLimit2....)
最终的副本数为
max(stabilizedRecommendation, max(scaleUpLimit, hpa.Spec.maxReplicas))
2.4 扩容慢的原因
扩容慢包含三个方面,一个是扩容的响应时间,另一个是每次扩容的副本数即扩容速度,还有扩容的敏感度。
2.4.1 扩缩容的响应时间
由于metrics-server是周期性的收集kubelet上的监控信息,这个周期默认是15s。而kubelet里的cadvisor周期性的收集pod相关的监控信息,这个周期是30s。HPA controller每15秒执行一次HPA对象的workload副本数计算。
所以resource和containerResource数据源类型的扩容延迟的时间在[0, 60s],即延迟最大为60s。
而其他类型的扩容延迟时间,还受监控组件(比如Prometheus、VictoriaMetrics)收集监控信息周期影响,所以延迟为[0, 15+监控收集周期]
2.4.2 扩缩容的速度
了解了HPA controller计算副本数的流程,最终的副本数由监控数据和扩缩容行为控制决定。分析一下开头的测试结果,先看压测开始后第一次HPA资源的变化时候的status字段,这里给出了当前的监控的averageUtilization为2575,averageValue为515m。
根据这个数据我们看一下期望的副本数为258 = ceil(spec.replicas * averageValue * 100 / request * target.averageUtilization) = ceil(2 * 515 * 100/20 * 20) 。
由于hpa.spec.maxReplicas为10,会将10保存到内存中。然后没有配置hpa.spec.behavior,所以这个窗口的扩容上限为4=max(2 * spec.replicas, 4)= max(4, 4),所以第一次最终的副本数为4。
status:
conditions:
- lastTransitionTime: "2023-11-02T03:27:06Z"
message: the HPA controller was able to update the target scale to 4
reason: SucceededRescale
status: "True"
type: AbleToScale
- lastTransitionTime: "2023-11-02T03:37:07Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2023-11-02T05:01:38Z"
message: the desired replica count is increasing faster than the maximum scale
rate
reason: ScaleUpLimit
status: "True"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 2575
averageValue: 515m
name: cpu
type: Resource
currentReplicas: 2
desiredReplicas: 4
lastScaleTime: "2023-11-02T05:10:26Z"第二次HPA资源变化的status字段里的监控数据averageUtilization和averageValue都为0,由于最小副本数为1(没有配置hpa.spec.minReplicas,默认为0),所以期望副本数为1,然后保存到内存中。由于这个窗口内内存里最大的副本数为10,所以还是会进行扩容。所以最终副本数为8=max(2 * spec.replicas, 4)= max(8, 4)。后面第三次扩容类似,这里就不分析了。
status:
conditions:
- lastTransitionTime: "2023-11-02T03:27:06Z"
message: the HPA controller was able to update the target scale to 8
reason: SucceededRescale
status: "True"
type: AbleToScale
- lastTransitionTime: "2023-11-02T03:37:07Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2023-11-02T05:01:38Z"
message: the desired replica count is increasing faster than the maximum scale
rate
reason: ScaleUpLimit
status: "True"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: "0"
name: cpu
type: Resource
currentReplicas: 4
desiredReplicas: 8
lastScaleTime: "2023-11-02T05:10:41Z"2.4.3 扩容的敏感度
--horizontal-pod-autoscaler-tolerance参数决定了扩缩容时可以容忍的抖动范围。该参数旨在防止因监控数据波动而引发的意外扩缩容行为,但同时也可能导致扩缩容的敏感度降低。默认值为0.1,意味着可容忍10%的监控数据变化。
比如上面的例子里,只有pod的CPU平均使用率达到request的22%时候才会进行扩容。
2.4.4 HPA controller执行效率
在1.23版本中HPA controller只启动一个goroutine来处理集群中所有HPA资源,在大量的HPA对象的集群中会有性能瓶颈,所以在1.26版本中增加--concurrent-horizontal-pod-autoscaler-syncs命令行选项支持配置goroutine数量PR#108501
2.4.5 应用ready时间
由于存在unready pod监控数据修复问题(扩容时候数据修复为0),所以扩容的速度会变慢。
pod ready需要的时间越短扩缩容速度越快,而pod从启动到ready时间,取决于pod调度、kubelet响应pod调度完成、镜像下载、容器创建、应用启动、应用readiness。
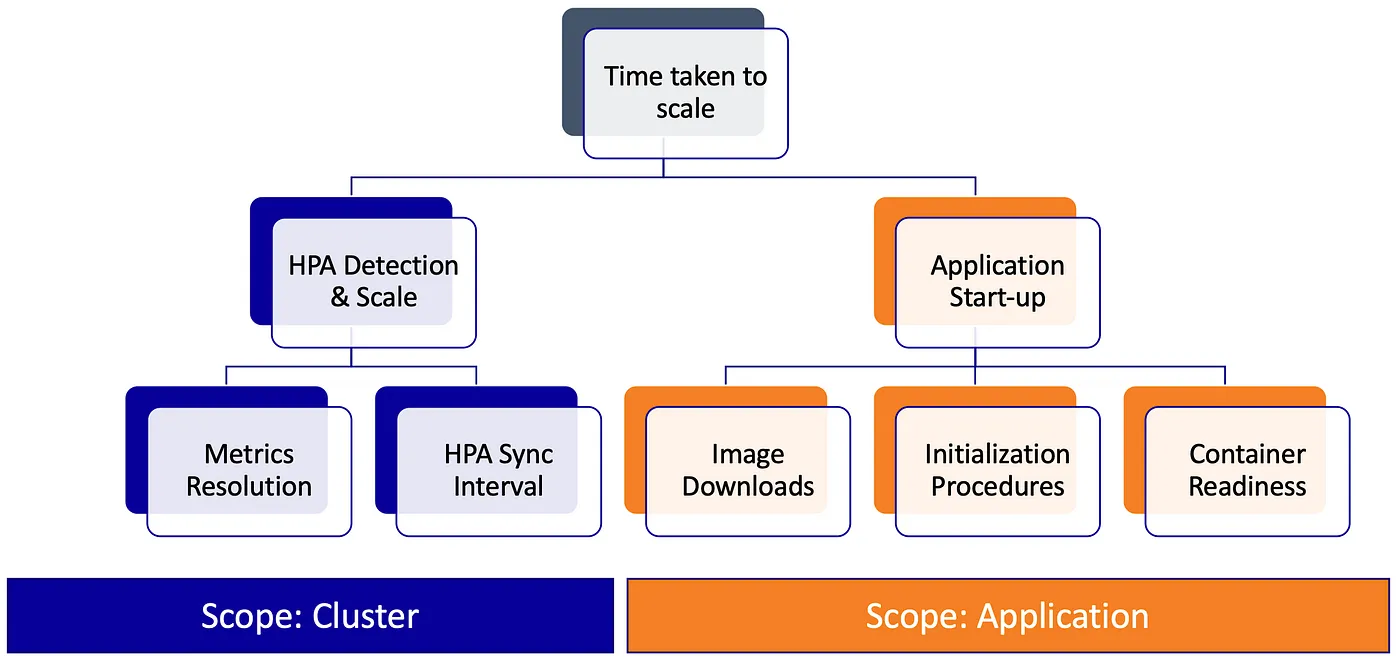
图片来自:https://medium.com/expedia-group-tech/autoscaling-in-kubernetes-why-doesnt-the-horizontal-pod-autoscaler-work-for-me-5f0094694054
3 解决方案
解决思路:
- 缩短获取监控的链路长度
- 缩短pod ready时间(pod生成到pod ready每个环节都进行优化)
- HPA controller性能提升
- 设置合理的扩容行为策略
- 设置合理的容忍度
- 预测式扩缩容或定时扩容
3.1 缩短获取监控的链路长度
除了kubernetes自身的HPA控制器进行水平扩缩容,还有Knative和KEDA项目也是进行水平扩缩容。
既然监控数据获取的链路过长导致扩缩容响应时间长,那么Knative就从简化链路长度来解决扩缩响应问题,支持基于qps和tps扩容,做到秒级弹性。
根据KEDA文档它的角色是取代Prometheus-adaptor,提供external和custom metrics,即依然使用HPA机制,并没有解决链路长问题。而是支持事件驱动然扩缩容更灵敏,这个knative也有这个功能。
3.2 缩短pod ready时间
这个话题就比较大了,包括镜像加速(dragonfly p2p,预拉取、containerd nydus),容器运行时(crun、podman、cri-o),调度器性能优化,拓扑感知。
3.3 HPA controller性能提升
使用1.26以上版本增加goroutine,当然不差钱的,有多好配置上多好配置。
3.4 设置合理的扩容行为策略
如果不设置behavior字段,每次扩容的数量受限于downscaleStabilisationWindow窗口内最大的副本数和当前的副本数spec.replicas(最大扩容上限scaleUpLimit为max(2*spec.replicas, 4))。
所以要在不设置behavior字段的情况下提高扩容速度,基本不可能。因为downscaleStabilisationWindow决定窗口内最大副本数的持续时间,它的作用的是防止突高随后突降导致副本数不稳定,而spec.replicas在HPA对象的调谐周期内是固定的。
既然behavior字段的配置影响扩缩容,那么合理的配置behavior字段能够提高扩缩容速度。
- 增加扩容速度: 减小
hpa.spec.behavior.scaleUp.stabilizationWindowSeconds(如果没有设置默认值为0)和增加hpa.spec.behavior.scaleUp.policies[*].Value和减小hpa.spec.behavior.scaleUp.policies[*].PeriodSeconds - 增加缩容速度:减小
hpa.spec.behavior.scaleDown.stabilizationWindowSeconds(如果没有设置默认值为–horizontal-pod-autoscaler-downscale-stabilization值)和增加hpa.spec.behavior.scaleDown.policies[*].Value和减小hpa.spec.behavior.scaleDown.policies[*].PeriodSeconds
3.5 设置合理的容忍度
设置合理的--horizontal-pod-autoscaler-tolerance,它是一把双刃剑,如果调整不合理容易频繁的扩缩容行为。
3.6 预测式扩缩容或定时扩容
换个思路,既然扩容慢不如提前扩容,像阿里云的AHPA,蚂蚁金服的kapacity。
基于历史流量进行预测式扩容,比如crane的EHPA,蚂蚁金服的kapacity,阿里云的AHPA。
4 总结
由于监控数据获取链路过长和HPA controller性能问题导致的扩容延迟,而应用的ready时间长短和hpa.spec.behavior会影响扩容速度。
缩短pod ready时间,需要在pod生成到pod ready的每个环节进行优化。
knative从简化监控获取链路角度来解决扩容延迟问题,提前扩容角度解决问题有crane的EHPA和蚂蚁金服的kapacity。
5 Reference
Autoscaling in Kubernetes: Why doesn’t the Horizontal Pod Autoscaler work for me?


![[译]Kubernetes CRD生成中的那些坑](/translate/kubernetes-crd-generation-pitfalls/crd-gen-pitfall.webp)