Kubernetes成本优化最佳实践
在降本增效的大环境下,Finops的理念非常符合这个需求。FinOps是一种结合财务、技术和业务的最佳实践方法,旨在优化云计算资源的成本、性能和价值。FinOps的目标是通过合理的资源管理和财务决策,使组织能够更好地理解、控制和优化云计算成本。
FinOps的阶段分为成本观测(Inform)、 成本分析(Recommend)和 成本优化(Operate)。
一般企业内部的成本平台会包含成本观测和成本分析,它将IT成本(云厂商的账单)按照服务类型维度和业务部门维度进行分析。
成本优化(Operate)从容易到难分为3个阶段:
- 处理空闲的机器和服务,合理选择服务和资源,包括适当的实例类型和计费模型(定价模型)和储值计划(Reserved Capacity)和套餐折扣。
- 应用服务缩容降配、减少冗余资源(三活变双活–“Twitter就是这么干”,双活变冷备,双活变单活、人员优化)
- 技术手段优化(提高利用率)
本文关注的技术优化成本阶段,在kubernets下的云原生降本策略。
1 理想的成本模型
我们的理想的成本模型是IT成本随着业务的变化而变化,比如订单增加了,则IT成本增加的趋势要小于等于订单增加趋势。而订单减少了,IT成本降低的趋势要大于等于订单降低趋势。
这个模型是我们执行降本的最终目标,一切都是围绕这个原则进行持续的优化成本。
2 云原生降本策略
kubernetes优化策略分为混部、弹性、提高节点利用率、合理的pod资源配置这方面进行阐述。
2.1 混部
一般大数据的离线任务在晚上执行,而在线业务白天到晚上是高峰器,凌晨是低峰期,所以就可以将在线业务和大数据离线任务进行混合部署,错峰利用资源。
下面是节点的资源模型(来自koordinator)。
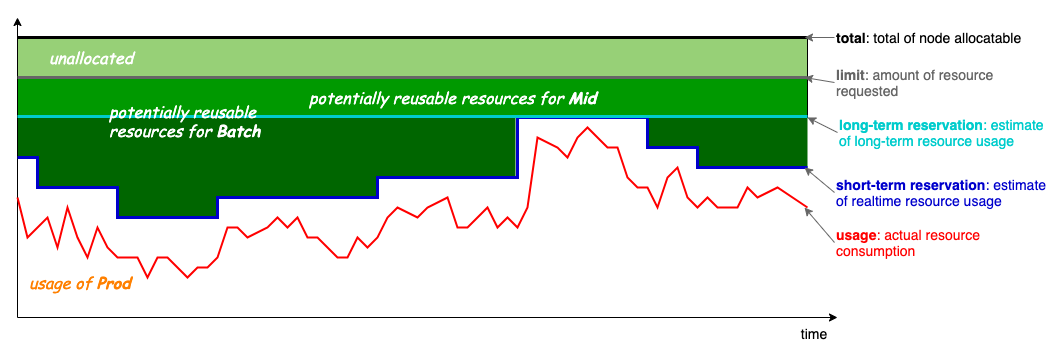
usage可以理解为实时在线业务的资源使用随时间变化情况。
short-term Reservation这部分是给在线业务空闲出来资源,可以用来运行短时间的job任务。
long-term Reservation这部分是预留的资源(一般情况下在线业务用不到这部分资源,只有在突发情况下才会用到这部分资源),可以用来运行长时间运行的任务。
Limit是节点分配给应用最大可以使用资源。
Total是节点的最大可以分配资源。
根据这个节点资源模型,需要进行调度优化和QOS保障,只有两方面做好了才能保证在线业务不受离线业务影响。
调度器方面有这些开源项目volcano、koordinator的scheduler、kueue、katalyst的scheduler、godel-scheduler
QOS保障有这些开源项目crane、koordinator、Katalyst
混部的另外一个好处可以将多个集群变成超大集群,节约公共组件的资源使用,比如apiserver、etcd、control-plane、监控组件。
混部不仅可以在单集群上,还可以在多个集群上。比如不同集群的资源利用率不一样,可以将任务部署到较低利用率的节点上。如果集群分布在不同时区,意味着集群的资源高峰器不一样,可以错峰部署离线任务。
多集群管理开源项目karmada正在探索解决这些方面需求。
2.2 弹性
弹性分为应用弹性、集群弹性、混合集群弹性。
应用弹性分为水平扩缩容和垂直扩缩容。水平扩缩容方面有HPA、KEDA、serverless(knative等)、定时HPA(腾讯云tke cron-hpa、阿里云开源kubernetes-cronhpa-controller、蚂蚁金服开源kapacity)、预测式扩容(crane的EHPA,蚂蚁金服的kapacity,阿里云的AHPA),其中在没有流量的时候,serverless可以让成本接近0。当然也要考虑下中间件和数据库的弹性,目前云原生数据库和中间件出现了很多开源项目(弹性是这些云原生开源项目必备的特性)。垂直扩缩容有VPA,从kubernets 1.27版本支持原地升级。
集群弹性方面,cluster-autoscaler根据pending pod(不可调度pod)数量决定自动增加集群的节点,出现空闲节点时候(也可以配合descheduler的HighNodeUtilization主动排空节点),自动将其下线。集群扩缩容还有aws开源的karpenter,它针对workload粒度扩容节点,而cluster-autoscaler基于云厂商的产品进行扩容节点。
混合集群弹性:当一个集群容量不足时候,临时将应用部署到其他集群中。典型场景是kubernetes在自建IDC机房,由于活动等原因需要扩容,由于自建机房资源交付较慢,而云厂商的快速的资源交付能力,将一部分业务部署到公有云上,以应对流量高峰期。
这个应用场景解决方案有两种:
-
利用virtual-kubelet将云厂商上的kubernets集群当作自建集群的一个节点,然后扩容的应用往这个节点调度。
-
将云厂商的kubernetes集群作为独立的集群,进行应用的部署。这个可以利用karmada完成应用在多集群中部署。
云厂商上kubernetes集群扩容节点策略:集群的节点分为两类,长期运行节点和短期运行节点,所以扩容短期运行节点,优先使用Spot Instance,然后是按量付费节点,最后是包年包月节点。长期运行节点扩容,选择包年包月。
2.3 提高节点利用率
资源超配即让pod的limit大于request,它是最简单的提高利用率的方法,它会提高节点的装箱率,但是这种方法缺点是pod的QOS只能是Burstable。
节点放大为将节点的可分配资源变大,让调度器认为可以节点可以分配更多的资源给pod。这样的好处是pod的QOS不用锁定为Burstable,pod可以自由配置QOS。开源里koordinator实现了节点放大。
BestEffort的pod使用节点空闲资源,即pod不设置limit和request。但是不限制limit会影响节点上的其他pod,针对这个问题crane的节点资源进行预测,动态计算出节点的剩余资源,pod配置扩展资源来使用这些资源(pod的QOS还是BestEffort),crane agent保证使用扩展资源的pod实际用量也不会超过其声明限制。
基于节点真实负载调度使用节点的真实资源使用进行调度,能够提高节点的利用率,均衡集群的节点的资源使用。crane和koordinator都具有这个功能。
Descheduler highNodeUtilization插件将高利用率的节点上的pod驱逐到底利用率的节点上,均衡集群的节点的资源使用。而lowNodeUtilization插件将底利用率的节点驱逐到高利用率的节点,然后将空闲的节点下线,从而提高节点利用率。目前社区的Descheduler使用已分配的request来计算节点的负载,对于实际使用并没有任何意义。而koordinator的Descheduler实现了负载感知的Descheduler,并增加了资源预留能力,保证被驱逐pod后生成新的pod,不会因为资源抢占导致pod处于pending状态。
2.4 合理的应用资源配置
业务方都会比较保守的为应用多预留资源,而这样会导致极大资源浪费。为应用设置合理的资源配置,避免资源的浪费。
资源规格推荐根据VPA的半衰期算法对应用规格进行推荐,可以让Request接近真实的使用值。这个对于默认的调度器kube-scheduler非常有用(它通过request来进行调度),可以提高节点的装箱率。crane和VPA都可以具有资源推荐的功能.
副本数推荐对于未开启HPA的应用,使用合理的副本数,也可以避免资源的浪费,crane具有副本数推荐功能。
HPA推荐对于开启了HPA的应用,也会因为HPA设置不合理,导致资源的浪费。crane根据应用真实资源使用,推荐合适的HPA的配置,提高应用的资源利用率。
3 总结
通过混部、弹性、提高节点利用率、合理的pod资源配置这几种技术手段能够提高kubernetes集群的资源利用率,降低成本。上面列举了我所了解的云原生降本的一些策略,具体到每个公司可以根据不同情况,可以采取不同策略,也不需要所有策略都要采用。
其中crane和koordinator都是非常好的进行降本增效的开源项目,但是crane在2023年变不活跃了,虽然两个创始人在kubeCon 2023 china上进行了分享When FinOps Meets Cloud Native – How We Reduce Cloud Cost with Cloud Native Scheduling Technologies。
koordinator和karmada依然非常活跃。
同时字节跳动也开始开源混部katalyst和调度器方面的项目godel-scheduler,其中godel-scheduler和katalyst-scheduler功能有点重叠,godel-scheduler是更专业的调度器,而katalyst-scheduler只实现了部分功能增强(在v0.4.0版本只扩展了节点资源拓扑感知和qos资源感知),需要关注一下项目后续发展。
在社区里问了katalyst-scheduler与godel-scheduler的关系、功能是否重叠,得到下面回复:
对于 katalyst 来说这两个的定位确实是重叠的,因为 katalyst 的部分功能需要调度器的能力来配合,e.g. 调度 reclaimed 资源,拓扑感知 etc。但是 katalyst 的核心能力还是在增强的 QoS 能力实现上,我们不希望它和某一个调度器是强绑定的关系,i.e. 想用 katalyst 的能力必须使用某一种调度器,或者基于某一种调度器来适配。它可以和 godel,基于 scheduler framework 的调度器,甚至 volcano 集成。 katalyst-scheduler 基于 scheduler framework 的调度器(核心是 scheduler plugin),目前主要作为一个 out-of-box 的调度器,方便用户能快速体验 katalyst 的能力,另外如果用户现在在生产中用的 k8s 的调度器,想使用 katalyst,但是不想替换调度器(e.g. 自己已经开发了一些调度插件),可以把 katalyst-scheduler 的一些 plugin 集成进去。 godel 是一个 production ready 的在离线融合调度的调度器,在融合调度场景中的性能和功能上更强,但是使用上需要把原来的调度器替换掉,并不是所有用户都能接受。 总体来说还是针对不同的使用场景的。
随着计算的发展,会有新的成本优化技术出现,也会有新的开源项目。