koordinator Descheduler的LowNodeLoad插件助力节点平衡与应用稳定性的提升
在 深度解析descheduler的highNodeUtilization和lowNodeUtilization插件的原理 中研究了kubernetes社区里的descheduler的两个Node utilization插件,而这两个插件用都存在使用request来计算节点的资源使用情况,无法解决节点过热(小部分节点的资源使用高于其他大部分节点)问题。而这篇文章介绍koordinator descheduler的LowNodeLoad插件就是解决这个问题的,它基于节点实际的资源使用值来区分高水位节点、正常节点和低水位节点。
koordinator descheduler兼容社区的descheduler,同时增加了两个插件MigrationController和LowNodeLoad(在Koordinator v1.1中增加的)。
koordinator的LowNodeLoad插件类似lowNodeUtilization插件,都是将高水位节点的pod驱逐到低水位节点上。跟lowNodeUtilization不同的是,它是基于节点的真实负载对节点进行分类,它能够真正解决节点资源过热问题。
MigrationController插件提供资源保留和仲裁机制(拦截机制),通过这两个能力保障descheduler驱逐pod时候的应用稳定性。
这篇文章只介绍LowNodeLoad插件,MigrationController插件后面文章会介绍,本文基于Koordinator v1.4版本和Descheduler v0.28.1。
1 执行原理
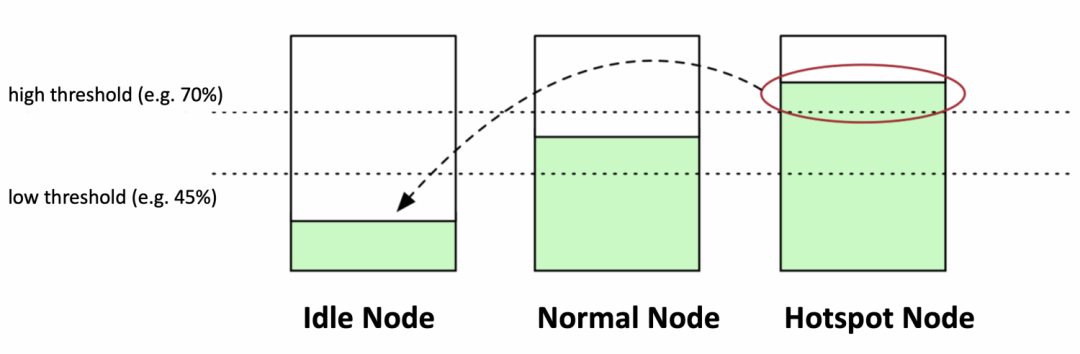
跟lowNodeUtilization一样有两个阈值,分别是高水位线和低水位线。节点里所有类型的资源使用率都小于低水位线为Idle node,节点里至少有一个资源使用率大于高水位线为Hotspot node,剩下的节点为Normal node。
它的目标将Hotspot node上的pod驱逐到Idle node,让Hotspot node变成Normal node,达到节点的资源使用量均衡。
2 与lowNodeUtilization插件区别
LowNodeLoad插件比lowNodeUtilization插件增加了不少的功能,节点资源池的支持、对Hotspot node进行再次过滤(防止节点资源使用值抖动导致驱逐)、资源类型可以设置权重、增强pod排序算法。
2.1 执行流程方面
执行流程方面跟社区descheduler的lowNodeUtilization插件类似,但是它将preEvictionFilter步骤整合到filter pods阶段,让整个执行流程更合理更易于理解。
主要有以下流程:
- select nodes:选择需要执行驱逐pod的节点
- order nodes:对node进行排序
- filter pods:筛选出node上能够被驱逐的pod列表
- order pods:pod排序
- evict pod:执行驱逐
2.2 节点的资源使用情况计算方式
lowNodeUtilization插件通过节点上所有pod的request之和跟节点可以分配的资源的百分比来计算节点的资源使用率。
LowNodeLoad插件通过节点上真实的资源使用值(所有pod的资源使用值加上系统资源使用值)占节点可以分配的资源的百分比来计算节点的资源使用率。
其中select nodes步骤中,节点的真实资源使用情况是从每个节点对应的自定义资源NodeMetric中获得。
自定义资源NodeMetric是节点上koordlet组件(Koordinator里类似kubelet的组件,用于收集上报节点状态,为pod的分配资源和调整pod的cgroup设置等功能)维护更新,每个节点上的koordlet会将节点上的系统资源使用值和pod资源使用值更新到节点的NodeMetric资源上。
即koordinator descheduler的LowNodeLoad插件依赖koordlet组件获得节点上的资源使用情况,而不是依赖metrics-server来获得节点资源使用情况。
2.3 支持节点资源池
普遍存在这样的应用场景:集群里会将节点分成多个类型,通常通过labels来进行区分,每个类型的节点集合称为节点资源池。比如不同的业务调度的到不同的资源节点资源池上,而每个节点资源池的阈值设置不一样的。
社区里的lowNodeUtilization插件并不支持节点资源池,但也可以变通的实现这个需求,一个资源池对应一个descheduler的全局的nodeSelector配置和lowNodeUtilization配置,即要实现每个节点资源池执行驱逐,需要运行多个descheduler。
Koordinator的LowNodeLoad插件原生支持节点资源池,即可以为不同的节点资源池设置NodeSelector、HighThresholds(高水位)、LowThresholds(低水位)、ResourceWeights(资源的权重)等配置项。
2.4 基于状态机制过滤出需要执行驱逐的节点
由于节点的request的变化不是很频繁,所以社区里的lowNodeUtilization插件根据节点当前request使用率对节点进行分类。
而节点的资源实际使用值是一个变化比较频繁的指标,为了避免资源使用发生抖动导致触发驱逐pod,LowNodeLoad插件采用固定时间内多次连续维持状态判定的方法来对节点进行分类。节点的状态分为异常和正常状态,节点在固定时间内(窗口是固定)多次连续为Hotspot node则认为这个节点处于异常状态,节点在固定时间内(窗口是固定)多次连续为Normal node则为正常状态。
在select nodes步骤中,先会对Hotspot node进行异常状态计数器累加和正常状态计数器重置,然后过滤出达到异常状态标准的节点,异常的节点才会执行驱逐pod。节点在驱逐后恢复到Normal node后会重置异常状态计数器和正常状态计数器。
2.5 资源类型有权重
在节点排序阶段,lowNodeUtilization插件直接根据节点所有资源类型的request之和从大到小进行排序。
LowNodeLoad插件可以设置每种资源类型的权重(资源池维度),这样的我可以倾向某个资源来影响排序,比如更关注cpu使用,cpu资源设置更大的权重,这样cpu使用高的节点尽可能的优先执行驱逐pod。节点排序按照节点分数从大到小进行排序,节点的分数为所有资源使用值占allocatable的千分比乘以权重的总和,然后除以权重之和,即sum((每种资源的使用值 * 1000/每种资源的allocatable) * 资源的weight)/sum(资源的weight)。
2.6 pod排序算法
lowNodeUtilization插件排序算法只根据priority和Qos,这无法满足企业的实际生产情况,它没有考虑pod实际的资源使用值,没有考虑pod-deletion-cost,没有考虑业务的重要性等。
LowNodeLoad插件根据pod的资源使用、 Koordinator的PriorityClass、Priority、QoS Class、Koordinator QoSClass、pod-deletion-cost、EvictionCost、pod创建时间维度进行排序。
其中pod的资源使用也是通过节点上对应的自定义资源NodeMetric获取的。
具体排序规则:
| 排序字段 | 维度 | 排序规则 |
|---|---|---|
| 第一排序字段 | Koordinator PriorityClass | 按照"koord-free"、“koord-batch”、“koord-mid”、“koord-prod”、""(没有值或为空)顺序 |
| 第二排序字段 | Priority | 按从小到大顺序 |
| 第三排序字段 | QoS Class | 按照BestEffort、Burstable、Guaranteed顺序 |
| 第四排序字段 | Koordinator QoSClass | 按照"BE"、“LS”、“LSR”、(“LSE”、“SYSTEM”)、""(没有值或为空)顺序 |
| 第五排序字段 | pod-deletion-cost | 按从小到大顺序 |
| 第六排序字段 | EvictionCost | 按从小到大顺序 |
| 第七排序字段 | pod的资源使用 | 1. 没有监控数据的pod排在有监控数据的pod前面 2. 在有监控数据的pod里,按照pod的分数从大到小排序,即按照pod资源使用从大到小排序 pod分数计算算法: sum((每种资源的使用值 * 1000/节点上资源的allocatable) * 资源的weight)/sum(资源的weight) |
| 第八排序字段 | pod创建时间 | 创建时间越晚的排在前面 |
3 配置样例
在官方helm chart里的koordinator descheduler默认配置,可以看到并没有启用LowNodeLoad插件。
|
|
下面单独启用插件配置的样例
|
|
启用启用LowNodeLoad插件和MigrationController插件
|
|
4 总结
koordinator descheduler的LowNodeLoad插件不是一个通用的descheduler插件,它依赖koordinator里koordlet来获取pod和node的资源使用情况,即无法单独运行koordinator descheduler来使用LowNodeLoad插件。其中节点状态机制设计太过于复杂,高利用率节点之间状态切换存在中间状态,而且窗口是固定的,如果使用滑动窗口算法实现会简单一点。
当然pod 排序算法考虑了pod的实际使用,也考虑了pod的重要性(通过Koordinator PriorityClass)同时也支持pod-deletion-cost和EvictionCost(可以一定程度手动调整排序),这个设计不错,虽然不一定满足所有企业的需求。
可以配置资源的类型设置权重,在设置多种资源来计算节点资源使用情况下,可以倾向于某个资源使用率高的节点更早进行驱逐pod(说明这个节点更迫切需要降低节点的资源)。
支持节点资源池资源,这样可以对每个节点资源池单独设置的HighThresholds(高水位)、LowThresholds(低水位)、ResourceWeights(资源的权重),这样更贴合每个资源池的业务特性。
同时结合MigrationController插件能够启用资源保留功能和仲裁机制功能,资源保留功能需要koordinator scheduler支持(意味着你需要运行koordinator全家桶),仲裁机制提供额外的拦截机制,比如workload驱逐pod数量限制(可以理解为PodDisruptionBucket)。
5 Reference
Koordinator v1.4 正式发布!为用户带来更多的计算负载类型和更灵活的资源管理机制